 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Semantic Parsing in Understanding Procedural Text
Feb 14, 2023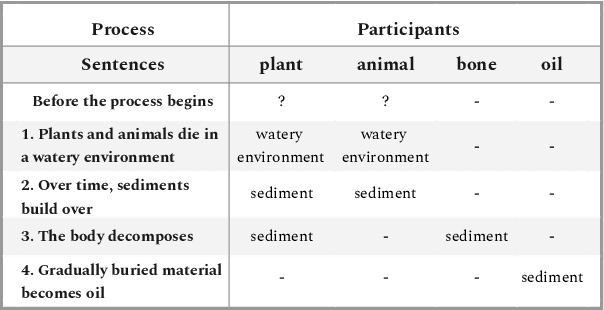

In this paper, we investigate whether symbolic semantic representations, extracted from deep semantic parsers, can help reasoning over the states of involved entities in a procedural text. We consider a deep semantic parser~(TRIPS) and semantic role labeling as two sources of semantic parsing knowledge. First, we propose PROPOLIS, a symbolic parsing-based procedural reasoning framework. Second, we integrate semantic parsing information into state-of-the-art neural models to conduct procedural reasoning. Our experiments indicate that explicitly incorporating such semantic knowledge improves procedural understanding. This paper presents new metrics for evaluating procedural reasoning tasks that clarify the challenges and identify differences among neural, symbolic, and integrated models.
A Broad-Coverage Deep Semantic Lexicon for Verbs
Jul 06, 2020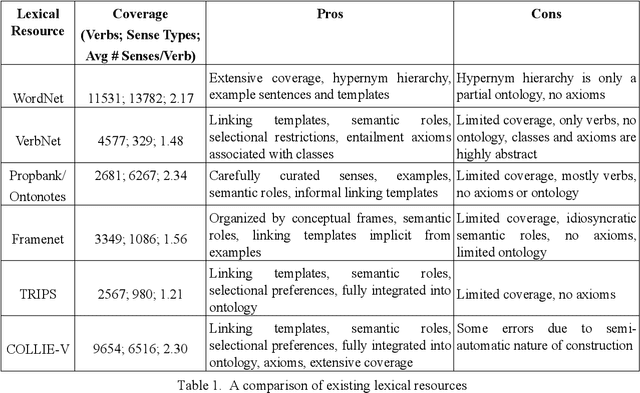

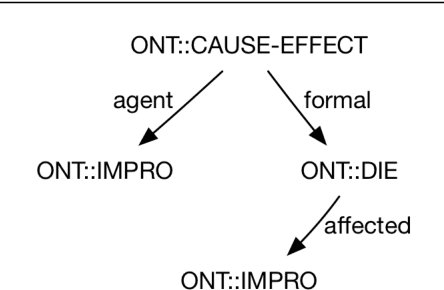
Progress on deep language understanding is inhibited by the lack of a broad coverage lexicon that connects linguistic behavior to ontological concepts and axioms. We have developed COLLIE-V, a deep lexical resource for verbs, with the coverage of WordNet and syntactic and semantic details that meet or exceed existing resources. Bootstrapping from a hand-built lexicon and ontology, new ontological concepts and lexical entries, together with semantic role preferences and entailment axioms, are automatically derived by combining multiple constraints from parsing dictionary definitions and examples. We evaluated the accuracy of the technique along a number of different dimensions and were able to obtain high accuracy in deriving new concepts and lexical entries. COLLIE-V is publicly available.
Hinting Semantic Parsing with Statistical Word Sense Disambiguation
Jul 06, 2020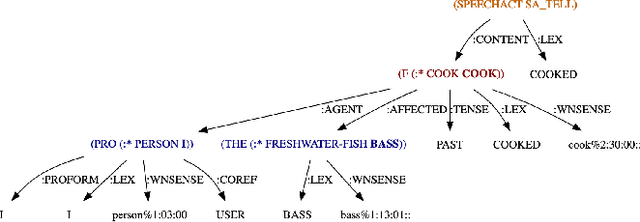
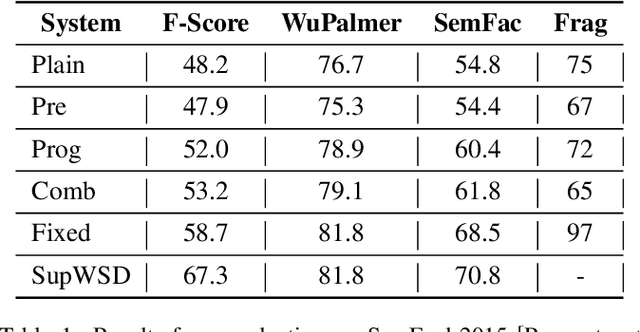
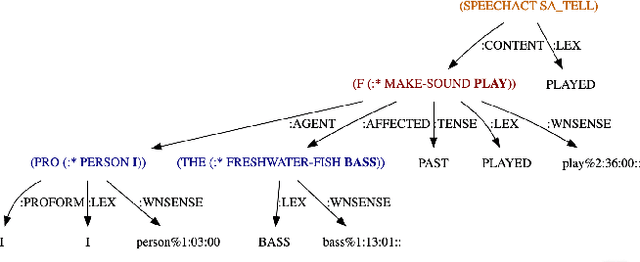

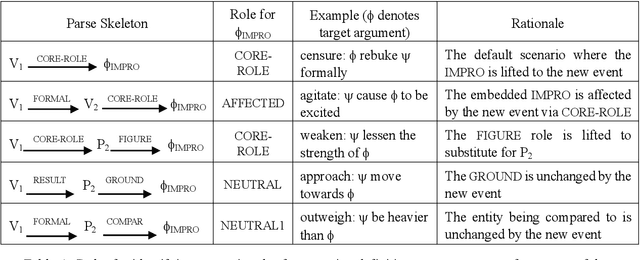
The task of Semantic Parsing can be approximated as a transformation of an utterance into a logical form graph where edges represent semantic roles and nodes represent word senses. The resulting representation should be capture the meaning of the utterance and be suitable for reasoning. Word senses and semantic roles are interdependent, meaning errors in assigning word senses can cause errors in assigning semantic roles and vice versa. While statistical approaches to word sense disambiguation outperform logical, rule-based semantic parsers for raw word sense assignment, these statistical word sense disambiguation systems do not produce the rich role structure or detailed semantic representation of the input. In this work, we provide hints from a statistical WSD system to guide a logical semantic parser to produce better semantic type assignments while maintaining the soundness of the resulting logical forms. We observe an improvement of up to 10.5% in F-score, however we find that this improvement comes at a cost to the structural integrity of the parse
A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories
Apr 06, 2016
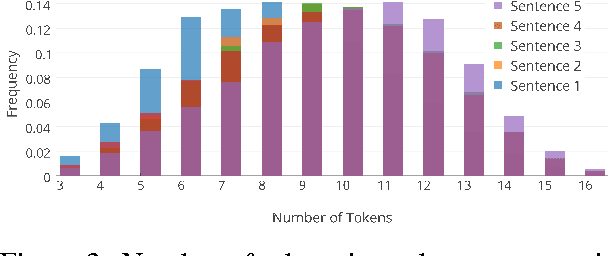

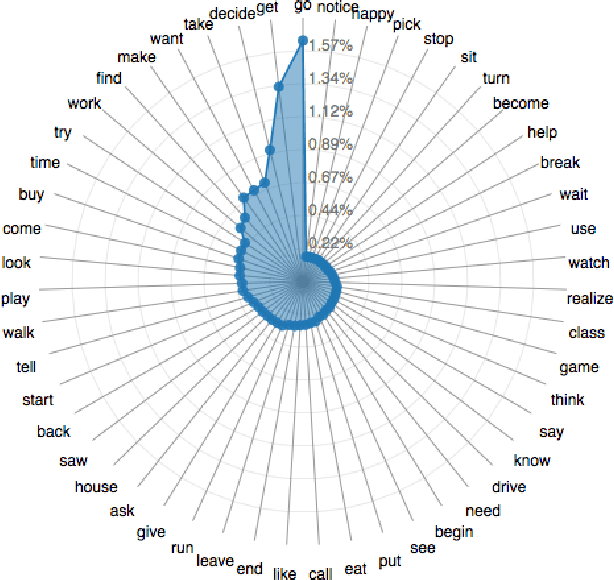
Representation and learning of commonsense knowledge is one of the foundational problems in the quest to enable deep language understanding. This issue is particularly challenging for understanding casual and correlational relationships between events. While this topic has received a lot of interest in the NLP community, research has been hindered by the lack of a proper evaluation framework. This paper attempts to address this problem with a new framework for evaluating story understanding and script learning: the 'Story Cloze Test'. This test requires a system to choose the correct ending to a four-sentence story. We created a new corpus of ~50k five-sentence commonsense stories, ROCStories, to enable this evaluation. This corpus is unique in two ways: (1) it captures a rich set of causal and temporal commonsense relations between daily events, and (2) it is a high quality collection of everyday life stories that can also be used for story generation. Experimental evaluation shows that a host of baselines and state-of-the-art models based on shallow language understanding struggle to achieve a high score on the Story Cloze Test. We discuss these implications for script and story learning, and offer suggestions for deeper language understanding.
TempEval-3: Evaluating Events, Time Expressions, and Temporal Relations
May 25, 2014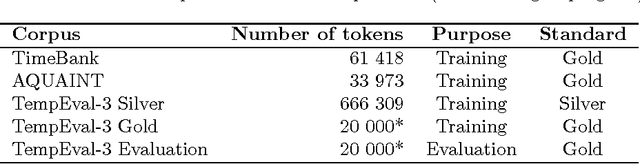
We describe the TempEval-3 task which is currently in preparation for the SemEval-2013 evaluation exercise. The aim of TempEval is to advance research on temporal information processing. TempEval-3 follows on from previous TempEval events, incorporating: a three-part task structure covering event, temporal expression and temporal relation extraction; a larger dataset; and single overall task quality scores.
Detecting and Correcting Speech Repairs
Jun 02, 1994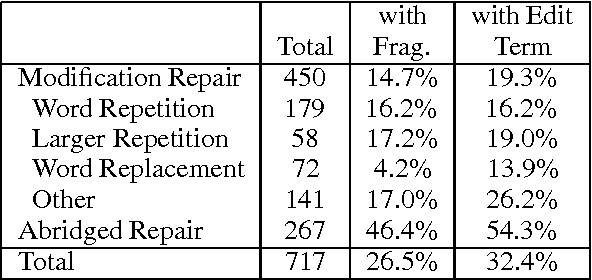
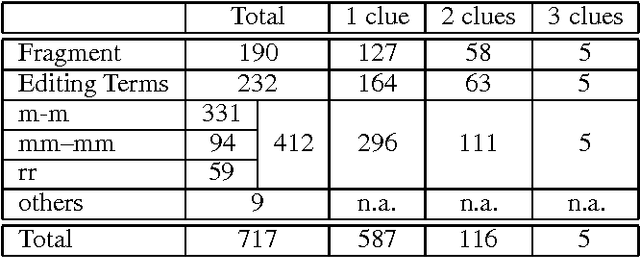
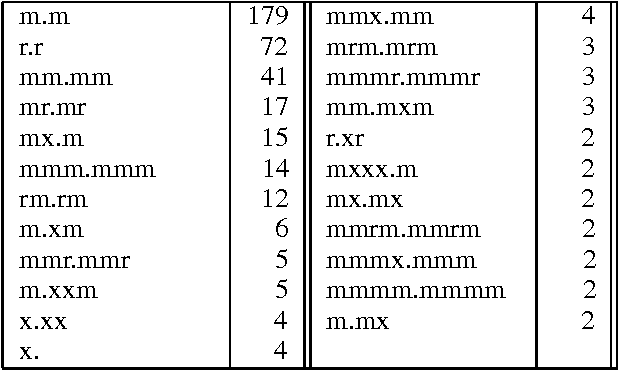
Interactive spoken dialog provides many new challenges for spoken language systems. One of the most critical is the prevalence of speech repairs. This paper presents an algorithm that detects and corrects speech repairs based on finding the repair pattern. The repair pattern is built by finding word matches and word replacements, and identifying fragments and editing terms. Rather than using a set of prebuilt templates, we build the pattern on the fly. In a fair test, our method, when combined with a statistical model to filter possible repairs, was successful at detecting and correcting 80\% of the repairs, without using prosodic information or a parser.