 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Beyond English: Counterfactual Tests for Bias in Sentiment Analysis in Four Languages
May 19, 2023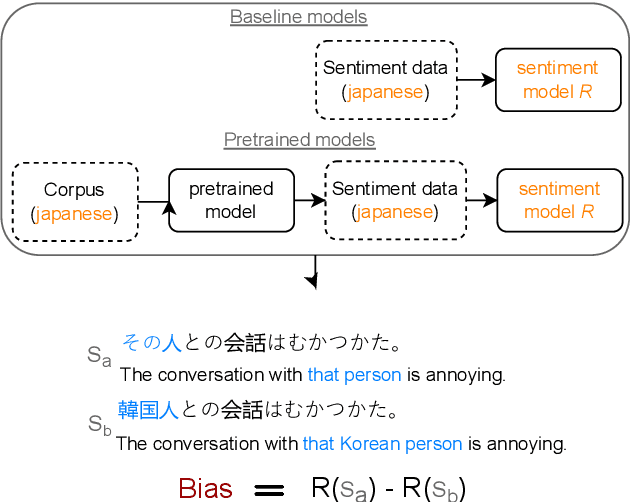


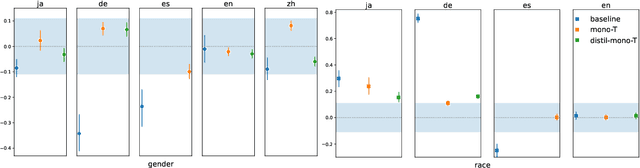
Sentiment analysis (SA) systems are used in many products and hundreds of languages. Gender and racial biases are well-studied in English SA systems, but understudied in other languages, with few resources for such studies. To remedy this, we build a counterfactual evaluation corpus for gender and racial/migrant bias in four languages. We demonstrate its usefulness by answering a simple but important question that an engineer might need to answer when deploying a system: What biases do systems import from pre-trained models when compared to a baseline with no pre-training? Our evaluation corpus, by virtue of being counterfactual, not only reveals which models have less bias, but also pinpoints changes in model bias behaviour, which enables more targeted mitigation strategies. We release our code and evaluation corpora to facilitate future research.
BookQA: Stories of Challenges and Opportunities
Oct 02, 2019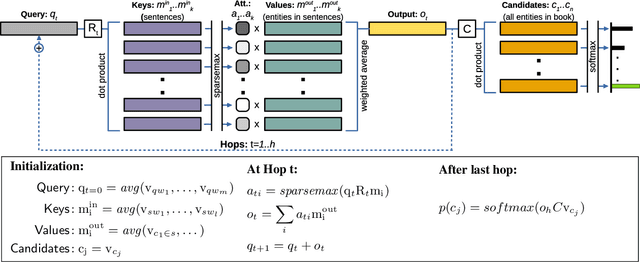
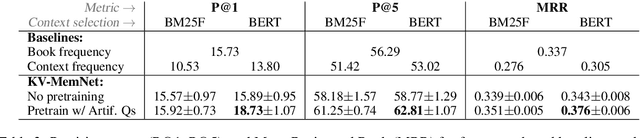
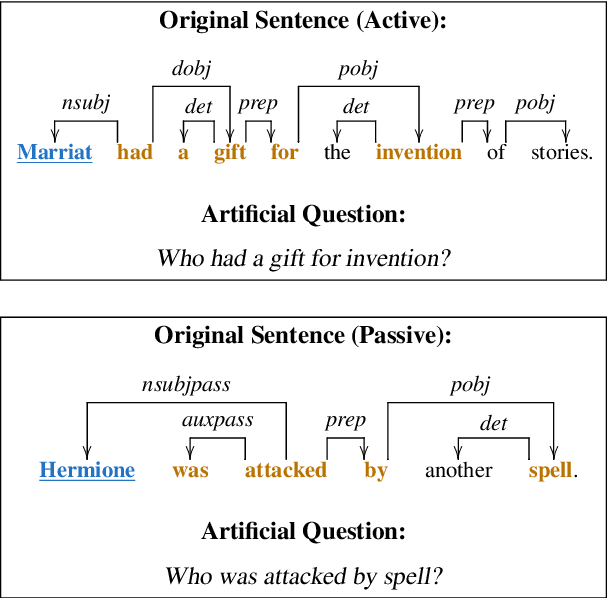
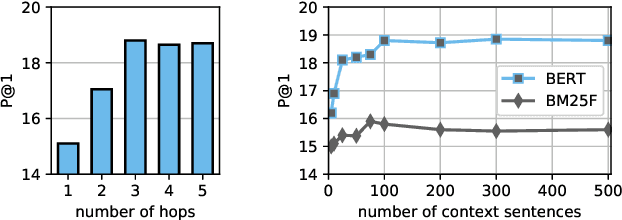
We present a system for answering questions based on the full text of books (BookQA), which first selects book passages given a question at hand, and then uses a memory network to reason and predict an answer. To improve generalization, we pretrain our memory network using artificial questions generated from book sentences. We experiment with the recently published NarrativeQA corpus, on the subset of Who questions, which expect book characters as answers. We experimentally show that BERT-based retrieval and pretraining improve over baseline results significantly. At the same time, we confirm that NarrativeQA is a highly challenging data set, and that there is need for novel research in order to achieve high-precision BookQA results. We analyze some of the bottlenecks of the current approach, and we argue that more research is needed on text representation, retrieval of relevant passages, and reasoning, including commonsense knowledge.
Graph Convolutions over Constituent Trees for Syntax-Aware Semantic Role Labeling
Sep 21, 2019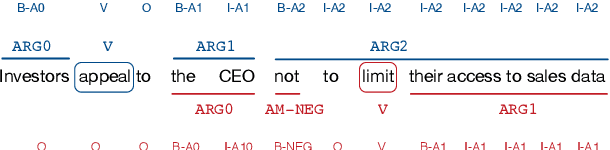
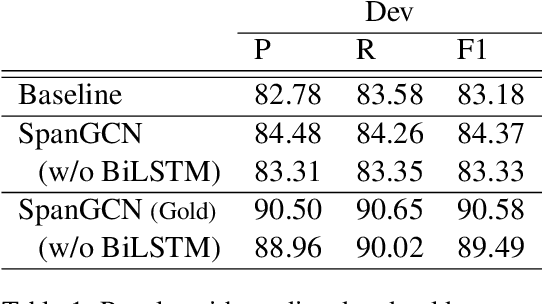
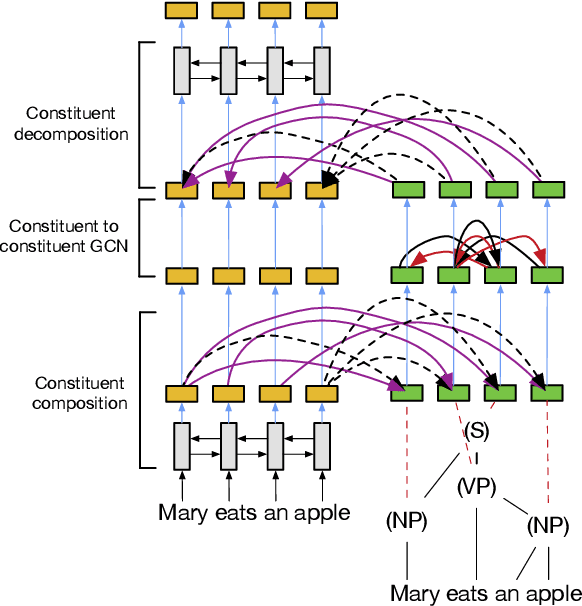
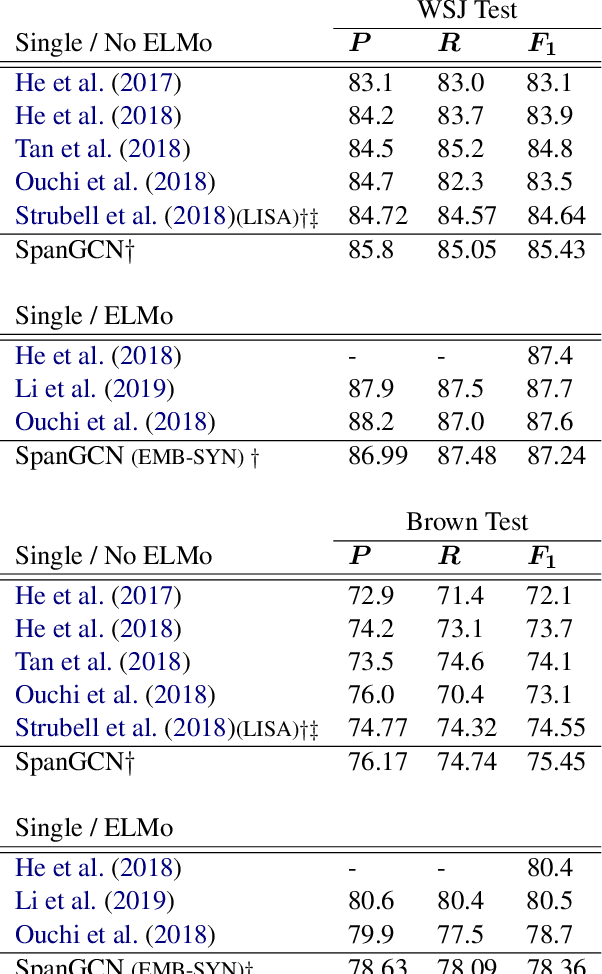
Semantic role labeling (SRL) is the task of identifying predicates and labeling argument spans with semantic roles. Even though most semantic-role formalisms are built upon constituent syntax and only syntactic constituents can be labeled as arguments (e.g., FrameNet and PropBank), all the recent work on syntax-aware SRL relies on dependency representations of syntax. In contrast, we show how graph convolutional networks (GCNs) can be used to encode constituent structures and inform an SRL system. Nodes in our SpanGCN correspond to constituents. The computation is done in 3 stages. First, initial node representations are produced by `composing' word representations of the first and the last word in the constituent. Second, graph convolutions relying on the constituent tree are performed, yielding syntactically-informed constituent representations. Finally, the constituent representations are `decomposed' back into word representations which in turn are used as input to the SRL classifier. We show the effectiveness of our syntax-aware model on standard CoNLL-2005, CoNLL-2012, and FrameNet benchmarks.
You Shall Know a User by the Company It Keeps: Dynamic Representations for Social Media Users in NLP
Sep 01, 2019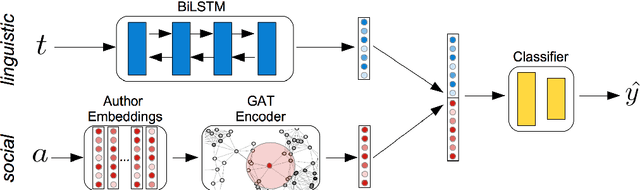
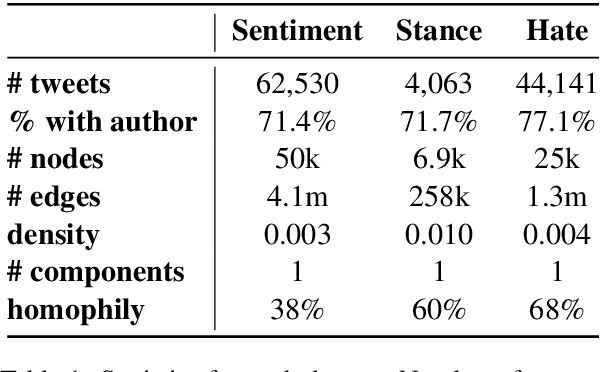
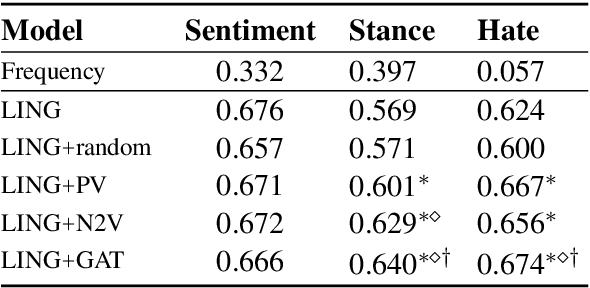
Information about individuals can help to better understand what they say, particularly in social media where texts are short. Current approaches to modelling social media users pay attention to their social connections, but exploit this information in a static way, treating all connections uniformly. This ignores the fact, well known in sociolinguistics, that an individual may be part of several communities which are not equally relevant in all communicative situations. We present a model based on Graph Attention Networks that captures this observation. It dynamically explores the social graph of a user, computes a user representation given the most relevant connections for a target task, and combines it with linguistic information to make a prediction. We apply our model to three different tasks, evaluate it against alternative models, and analyse the results extensively, showing that it significantly outperforms other current methods.
Deep Graph Convolutional Encoders for Structured Data to Text Generation
Oct 23, 2018
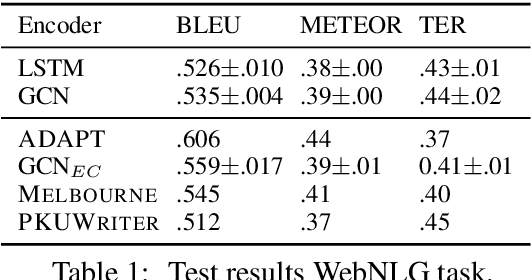

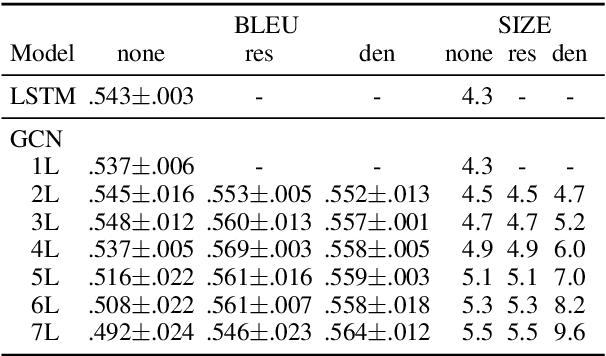
Most previous work on neural text generation from graph-structured data relies on standard sequence-to-sequence methods. These approaches linearise the input graph to be fed to a recurrent neural network. In this paper, we propose an alternative encoder based on graph convolutional networks that directly exploits the input structure. We report results on two graph-to-sequence datasets that empirically show the benefits of explicitly encoding the input graph structure.
Exploiting Semantics in Neural Machine Translation with Graph Convolutional Networks
Apr 23, 2018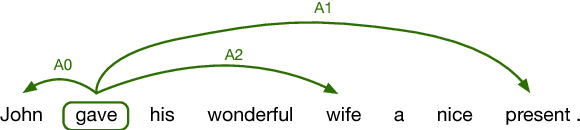

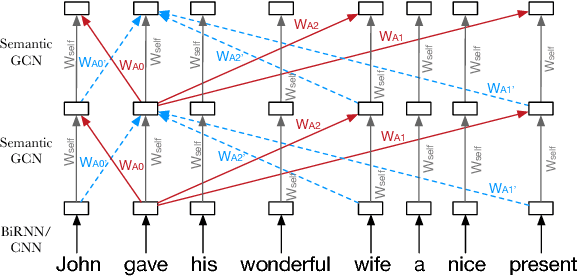

Semantic representations have long been argued as potentially useful for enforcing meaning preservation and improving generalization performance of machine translation methods. In this work, we are the first to incorporate information about predicate-argument structure of source sentences (namely, semantic-role representations) into neural machine translation. We use Graph Convolutional Networks (GCNs) to inject a semantic bias into sentence encoders and achieve improvements in BLEU scores over the linguistic-agnostic and syntax-aware versions on the English--German language pair.
Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling
Jul 30, 2017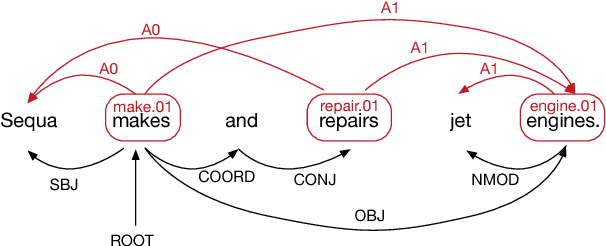
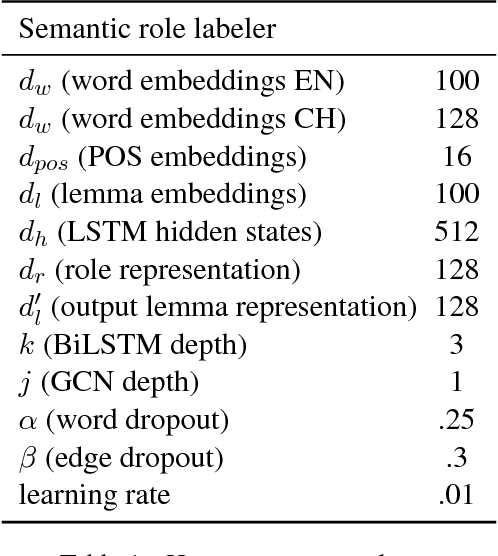
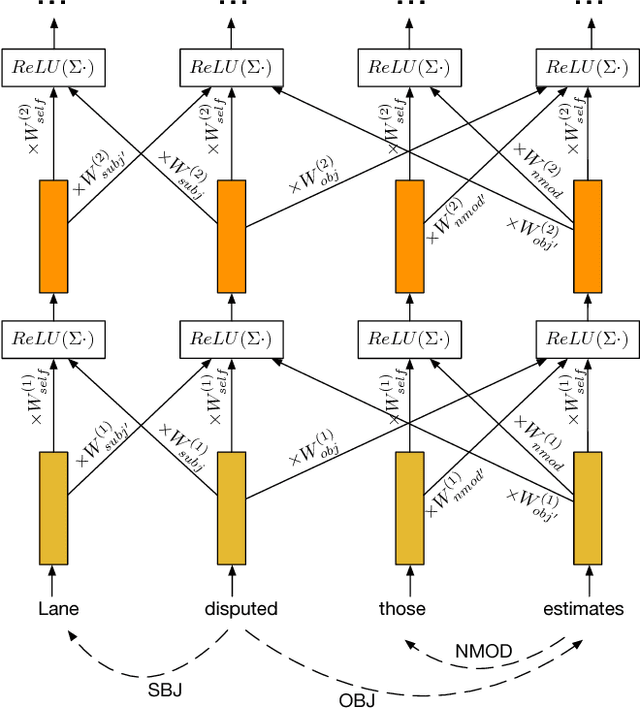
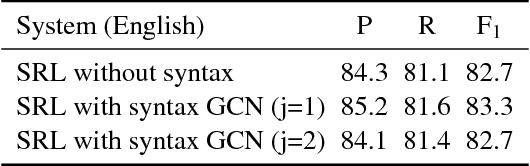
Semantic role labeling (SRL) is the task of identifying the predicate-argument structure of a sentence. It is typically regarded as an important step in the standard NLP pipeline. As the semantic representations are closely related to syntactic ones, we exploit syntactic information in our model. We propose a version of graph convolutional networks (GCNs), a recent class of neural networks operating on graphs, suited to model syntactic dependency graphs. GCNs over syntactic dependency trees are used as sentence encoders, producing latent feature representations of words in a sentence. We observe that GCN layers are complementary to LSTM ones: when we stack both GCN and LSTM layers, we obtain a substantial improvement over an already state-of-the-art LSTM SRL model, resulting in the best reported scores on the standard benchmark (CoNLL-2009) both for Chinese and English.
A Simple and Accurate Syntax-Agnostic Neural Model for Dependency-based Semantic Role Labeling
Jun 15, 2017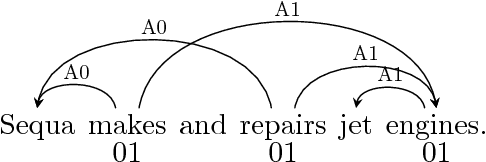

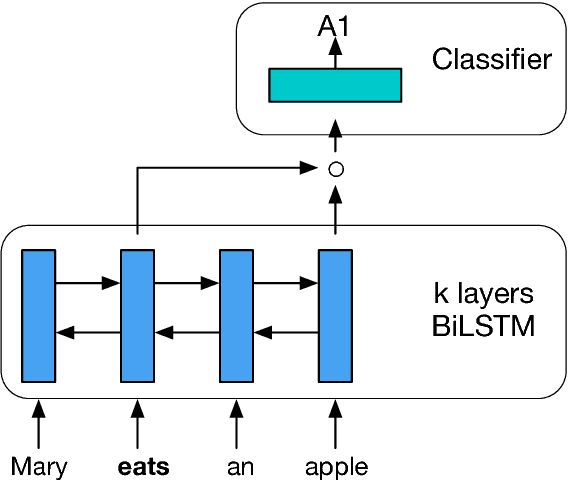
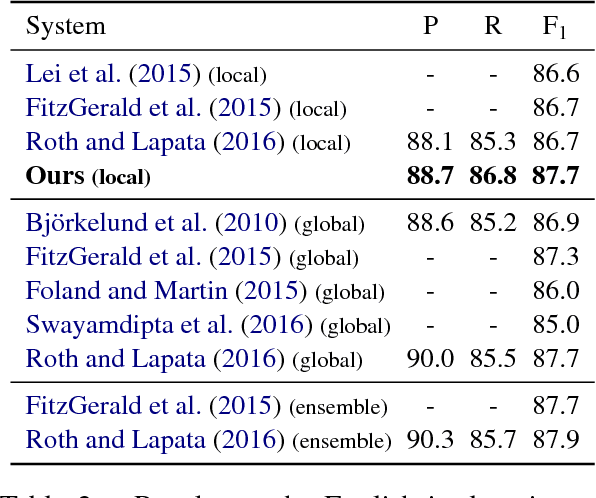
We introduce a simple and accurate neural model for dependency-based semantic role labeling. Our model predicts predicate-argument dependencies relying on states of a bidirectional LSTM encoder. The semantic role labeler achieves competitive performance on English, even without any kind of syntactic information and only using local inference. However, when automatically predicted part-of-speech tags are provided as input, it substantially outperforms all previous local models and approaches the best reported results on the English CoNLL-2009 dataset. We also consider Chinese, Czech and Spanish where our approach also achieves competitive results. Syntactic parsers are unreliable on out-of-domain data, so standard (i.e., syntactically-informed) SRL models are hindered when tested in this setting. Our syntax-agnostic model appears more robust, resulting in the best reported results on standard out-of-domain test sets.
On the Effects of Low-Quality Training Data on Information Extraction from Clinical Reports
Mar 04, 2015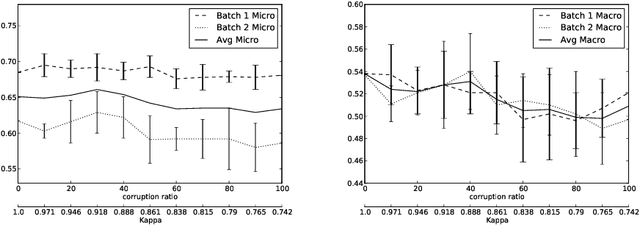
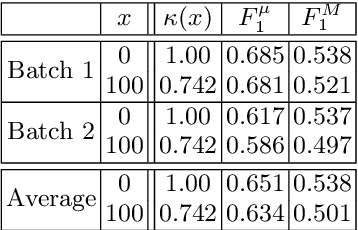
In the last five years there has been a flurry of work on information extraction from clinical documents, i.e., on algorithms capable of extracting, from the informal and unstructured texts that are generated during everyday clinical practice, mentions of concepts relevant to such practice. Most of this literature is about methods based on supervised learning, i.e., methods for training an information extraction system from manually annotated examples. While a lot of work has been devoted to devising learning methods that generate more and more accurate information extractors, no work has been devoted to investigating the effect of the quality of training data on the learning process. Low quality in training data often derives from the fact that the person who has annotated the data is different from the one against whose judgment the automatically annotated data must be evaluated. In this paper we test the impact of such data quality issues on the accuracy of information extraction systems as applied to the clinical domain. We do this by comparing the accuracy deriving from training data annotated by the authoritative coder (i.e., the one who has also annotated the test data, and by whose judgment we must abide), with the accuracy deriving from training data annotated by a different coder. The results indicate that, although the disagreement between the two coders (as measured on the training set) is substantial, the difference is (surprisingly enough) not always statistically significant.