 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Reproduce Stereotypes of Sexual and Gender Minorities
Jan 10, 2025A large body of research has found substantial gender bias in NLP systems. Most of this research takes a binary, essentialist view of gender: limiting its variation to the categories _men_ and _women_, conflating gender with sex, and ignoring different sexual identities. But gender and sexuality exist on a spectrum, so in this paper we study the biases of large language models (LLMs) towards sexual and gender minorities beyond binary categories. Grounding our study in a widely used psychological framework -- the Stereotype Content Model -- we demonstrate that English-language survey questions about social perceptions elicit more negative stereotypes of sexual and gender minorities from LLMs, just as they do from humans. We then extend this framework to a more realistic use case: text generation. Our analysis shows that LLMs generate stereotyped representations of sexual and gender minorities in this setting, raising concerns about their capacity to amplify representational harms in creative writing, a widely promoted use case.
First Tragedy, then Parse: History Repeats Itself in the New Era of Large Language Models
Nov 08, 2023

Many NLP researchers are experiencing an existential crisis triggered by the astonishing success of ChatGPT and other systems based on large language models (LLMs). After such a disruptive change to our understanding of the field, what is left to do? Taking a historical lens, we look for guidance from the first era of LLMs, which began in 2005 with large $n$-gram models for machine translation. We identify durable lessons from the first era, and more importantly, we identify evergreen problems where NLP researchers can continue to make meaningful contributions in areas where LLMs are ascendant. Among these lessons, we discuss the primacy of hardware advancement in shaping the availability and importance of scale, as well as the urgent challenge of quality evaluation, both automated and human. We argue that disparities in scale are transient and that researchers can work to reduce them; that data, rather than hardware, is still a bottleneck for many meaningful applications; that meaningful evaluation informed by actual use is still an open problem; and that there is still room for speculative approaches.
Taming the Sigmoid Bottleneck: Provably Argmaxable Sparse Multi-Label Classification
Oct 16, 2023



Sigmoid output layers are widely used in multi-label classification (MLC) tasks, in which multiple labels can be assigned to any input. In many practical MLC tasks, the number of possible labels is in the thousands, often exceeding the number of input features and resulting in a low-rank output layer. In multi-class classification, it is known that such a low-rank output layer is a bottleneck that can result in unargmaxable classes: classes which cannot be predicted for any input. In this paper, we show that for MLC tasks, the analogous sigmoid bottleneck results in exponentially many unargmaxable label combinations. We explain how to detect these unargmaxable outputs and demonstrate their presence in three widely used MLC datasets. We then show that they can be prevented in practice by introducing a Discrete Fourier Transform (DFT) output layer, which guarantees that all sparse label combinations with up to $k$ active labels are argmaxable. Our DFT layer trains faster and is more parameter efficient, matching the F1@k score of a sigmoid layer while using up to 50% fewer trainable parameters. Our code is publicly available at https://github.com/andreasgrv/sigmoid-bottleneck.
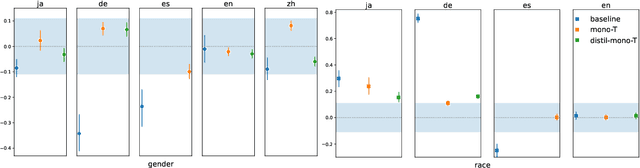
Cross-lingual Transfer Can Worsen Bias in Sentiment Analysis
May 22, 2023Sentiment analysis (SA) systems are widely deployed in many of the world's languages, and there is well-documented evidence of demographic bias in these systems. In languages beyond English, scarcer training data is often supplemented with transfer learning using pre-trained models, including multilingual models trained on other languages. In some cases, even supervision data comes from other languages. Does cross-lingual transfer also import new biases? To answer this question, we use counterfactual evaluation to test whether gender or racial biases are imported when using cross-lingual transfer, compared to a monolingual transfer setting. Across five languages, we find that systems using cross-lingual transfer usually become more biased than their monolingual counterparts. We also find racial biases to be much more prevalent than gender biases. To spur further research on this topic, we release the sentiment models we used for this study, and the intermediate checkpoints throughout training, yielding 1,525 distinct models; we also release our evaluation code.
Bias Beyond English: Counterfactual Tests for Bias in Sentiment Analysis in Four Languages
May 19, 2023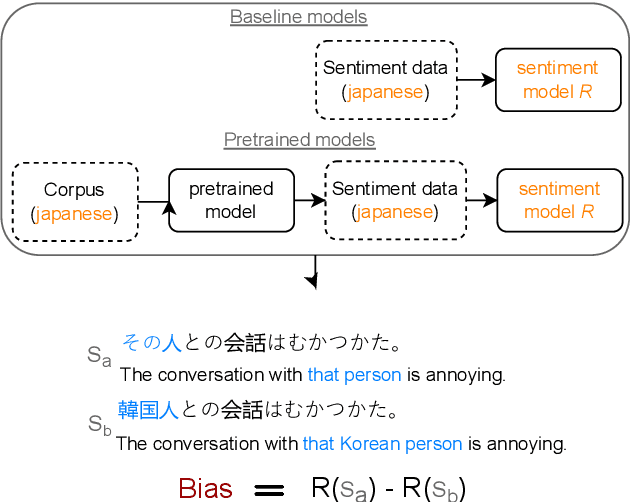


Sentiment analysis (SA) systems are used in many products and hundreds of languages. Gender and racial biases are well-studied in English SA systems, but understudied in other languages, with few resources for such studies. To remedy this, we build a counterfactual evaluation corpus for gender and racial/migrant bias in four languages. We demonstrate its usefulness by answering a simple but important question that an engineer might need to answer when deploying a system: What biases do systems import from pre-trained models when compared to a baseline with no pre-training? Our evaluation corpus, by virtue of being counterfactual, not only reveals which models have less bias, but also pinpoints changes in model bias behaviour, which enables more targeted mitigation strategies. We release our code and evaluation corpora to facilitate future research.
Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice
Mar 21, 2022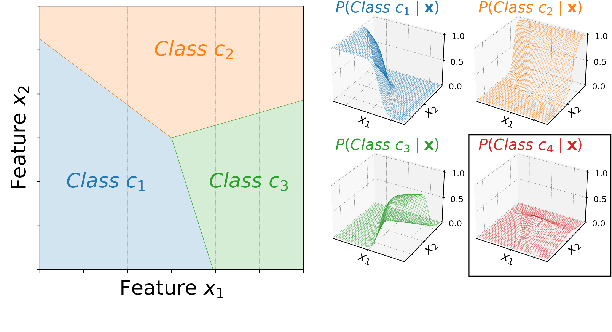
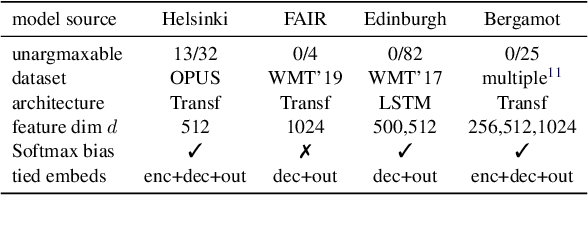
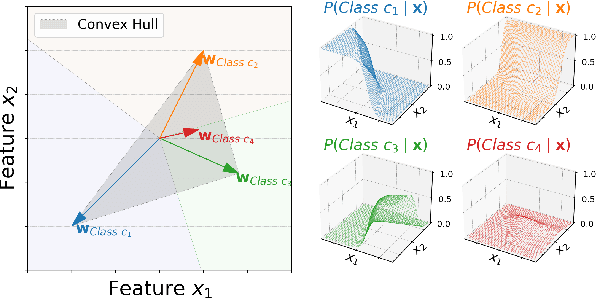
Classifiers in natural language processing (NLP) often have a large number of output classes. For example, neural language models (LMs) and machine translation (MT) models both predict tokens from a vocabulary of thousands. The Softmax output layer of these models typically receives as input a dense feature representation, which has much lower dimensionality than the output. In theory, the result is some words may be impossible to be predicted via argmax, irrespective of input features, and empirically, there is evidence this happens in small language models. In this paper we ask whether it can happen in practical large language models and translation models. To do so, we develop algorithms to detect such \emph{unargmaxable} tokens in public models. We find that 13 out of 150 models do indeed have such tokens; however, they are very infrequent and unlikely to impact model quality. We release our code so that others can inspect their models.
Intrinsic Bias Metrics Do Not Correlate with Application Bias
Jan 02, 2021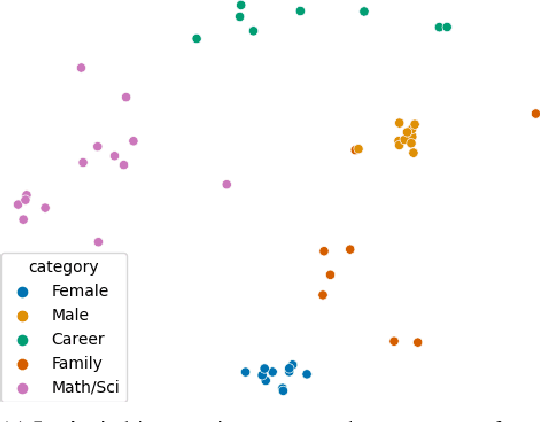

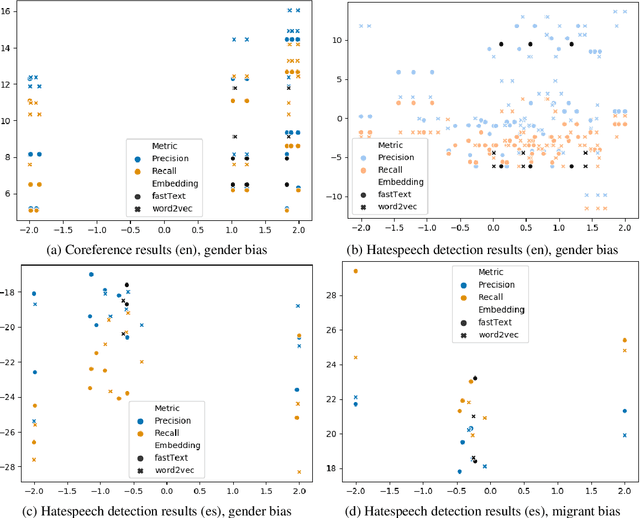
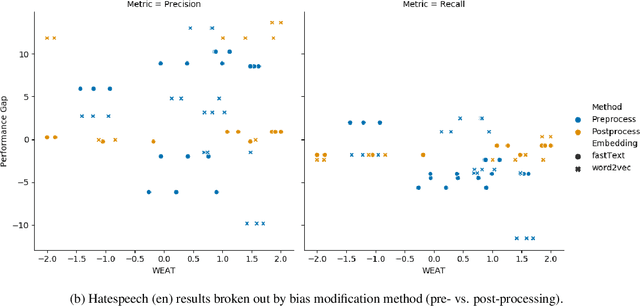
Natural Language Processing (NLP) systems learn harmful societal biases that cause them to widely proliferate inequality as they are deployed in more and more situations. To address and combat this, the NLP community relies on a variety of metrics to identify and quantify bias in black-box models and to guide efforts at debiasing. Some of these metrics are intrinsic, and are measured in word embedding spaces, and some are extrinsic, which measure the bias present downstream in the tasks that the word embeddings are plugged into. This research examines whether easy-to-measure intrinsic metrics correlate well to real world extrinsic metrics. We measure both intrinsic and extrinsic bias across hundreds of trained models covering different tasks and experimental conditions and find that there is no reliable correlation between these metrics that holds in all scenarios across tasks and languages. We advise that efforts to debias embedding spaces be always also paired with measurement of downstream model bias, and suggest that that community increase effort into making downstream measurement more feasible via creation of additional challenge sets and annotated test data. We additionally release code, a new intrinsic metric, and an annotated test set for gender bias for hatespeech.
LemMED: Fast and Effective Neural Morphological Analysis with Short Context Windows
Oct 21, 2020
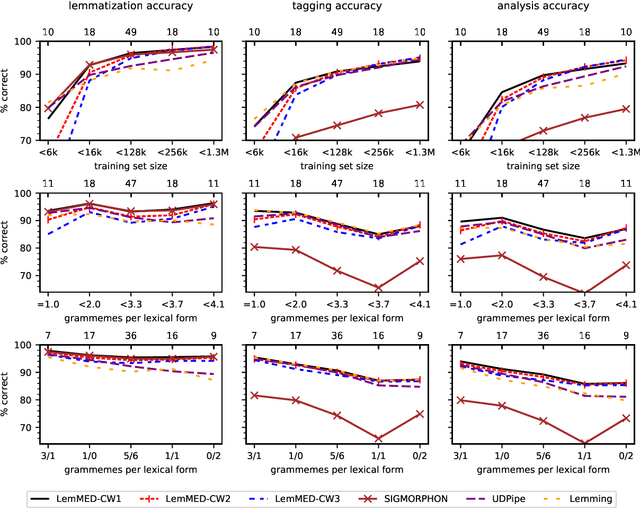
We present LemMED, a character-level encoder-decoder for contextual morphological analysis (combined lemmatization and tagging). LemMED extends and is named after two other attention-based models, namely Lematus, a contextual lemmatizer, and MED, a morphological (re)inflection model. Our approach does not require training separate lemmatization and tagging models, nor does it need additional resources and tools, such as morphological dictionaries or transducers. Moreover, LemMED relies solely on character-level representations and on local context. Although the model can, in principle, account for global context on sentence level, our experiments show that using just a single word of context around each target word is not only more computationally feasible, but yields better results as well. We evaluate LemMED in the framework of the SIMGMORPHON-2019 shared task on combined lemmatization and tagging. In terms of average performance LemMED ranks 5th among 13 systems and is bested only by the submissions that use contextualized embeddings.
LSTMs Compose (and Learn) Bottom-Up
Oct 06, 2020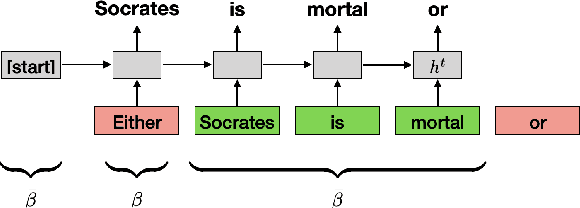
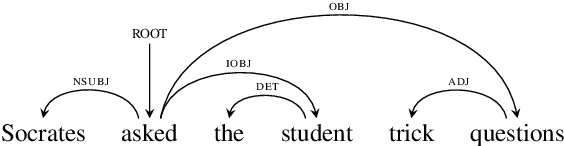
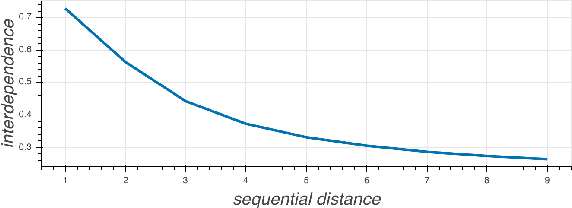
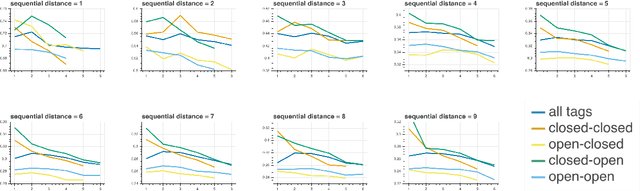
Recent work in NLP shows that LSTM language models capture hierarchical structure in language data. In contrast to existing work, we consider the \textit{learning} process that leads to their compositional behavior. For a closer look at how an LSTM's sequential representations are composed hierarchically, we present a related measure of Decompositional Interdependence (DI) between word meanings in an LSTM, based on their gate interactions. We connect this measure to syntax with experiments on English language data, where DI is higher on pairs of words with lower syntactic distance. To explore the inductive biases that cause these compositional representations to arise during training, we conduct simple experiments on synthetic data. These synthetic experiments support a specific hypothesis about how hierarchical structures are discovered over the course of training: that LSTM constituent representations are learned bottom-up, relying on effective representations of their shorter children, rather than learning the longer-range relations independently from children.
Inflecting when there's no majority: Limitations of encoder-decoder neural networks as cognitive models for German plurals
May 18, 2020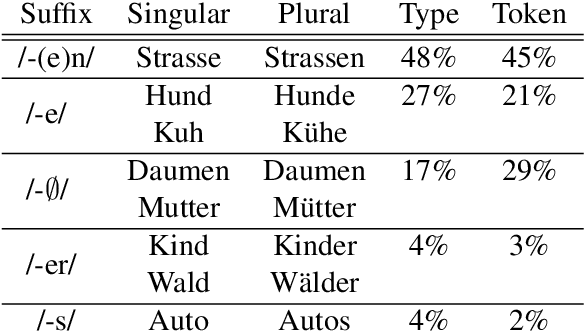
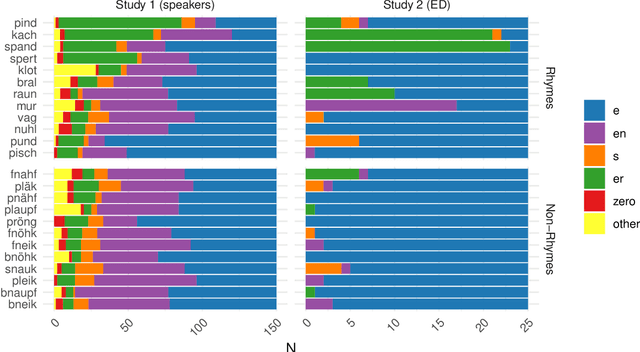
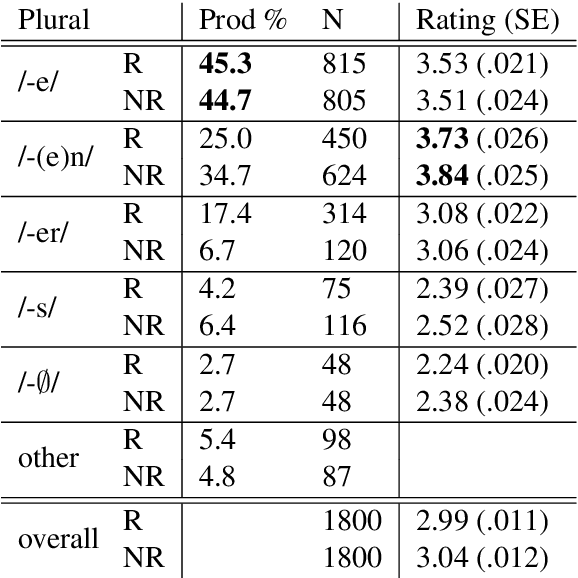
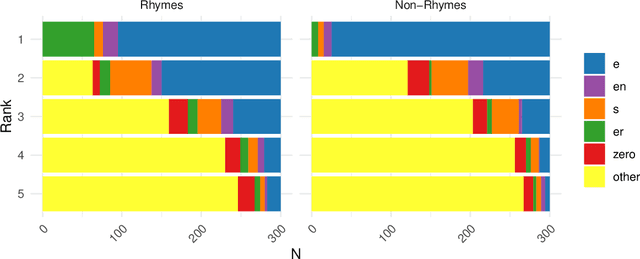
Can artificial neural networks learn to represent inflectional morphology and generalize to new words as human speakers do? Kirov and Cotterell (2018) argue that the answer is yes: modern Encoder-Decoder (ED) architectures learn human-like behavior when inflecting English verbs, such as extending the regular past tense form -(e)d to novel words. However, their work does not address the criticism raised by Marcus et al. (1995): that neural models may learn to extend not the regular, but the most frequent class -- and thus fail on tasks like German number inflection, where infrequent suffixes like -s can still be productively generalized. To investigate this question, we first collect a new dataset from German speakers (production and ratings of plural forms for novel nouns) that is designed to avoid sources of information unavailable to the ED model. The speaker data show high variability, and two suffixes evince 'regular' behavior, appearing more often with phonologically atypical inputs. Encoder-decoder models do generalize the most frequently produced plural class, but do not show human-like variability or 'regular' extension of these other plural markers. We conclude that modern neural models may still struggle with minority-class generalization.