 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemMED: Fast and Effective Neural Morphological Analysis with Short Context Windows
Oct 21, 2020
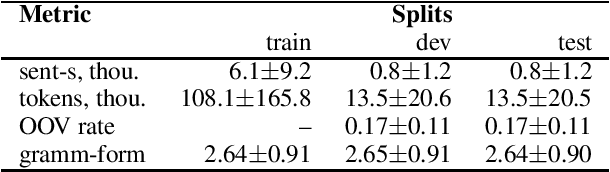
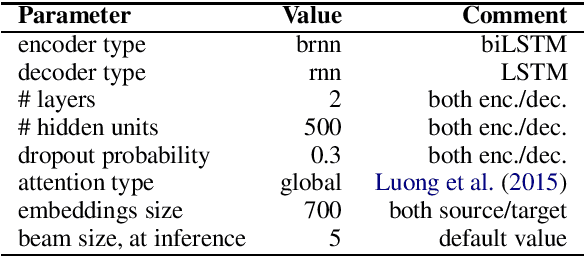
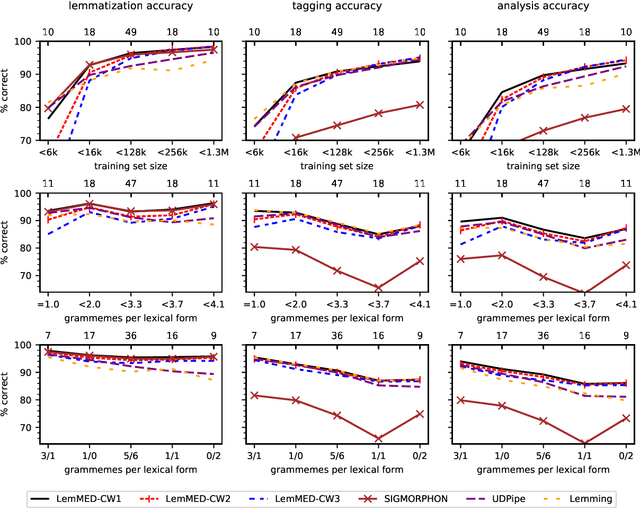
We present LemMED, a character-level encoder-decoder for contextual morphological analysis (combined lemmatization and tagging). LemMED extends and is named after two other attention-based models, namely Lematus, a contextual lemmatizer, and MED, a morphological (re)inflection model. Our approach does not require training separate lemmatization and tagging models, nor does it need additional resources and tools, such as morphological dictionaries or transducers. Moreover, LemMED relies solely on character-level representations and on local context. Although the model can, in principle, account for global context on sentence level, our experiments show that using just a single word of context around each target word is not only more computationally feasible, but yields better results as well. We evaluate LemMED in the framework of the SIMGMORPHON-2019 shared task on combined lemmatization and tagging. In terms of average performance LemMED ranks 5th among 13 systems and is bested only by the submissions that use contextualized embeddings.
Extracting Family Relationship Networks from Novels
May 03, 2014
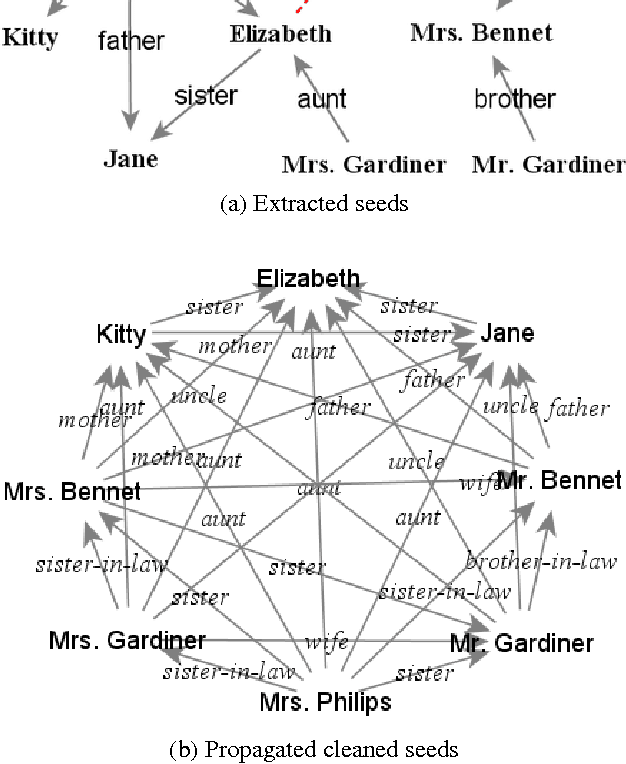

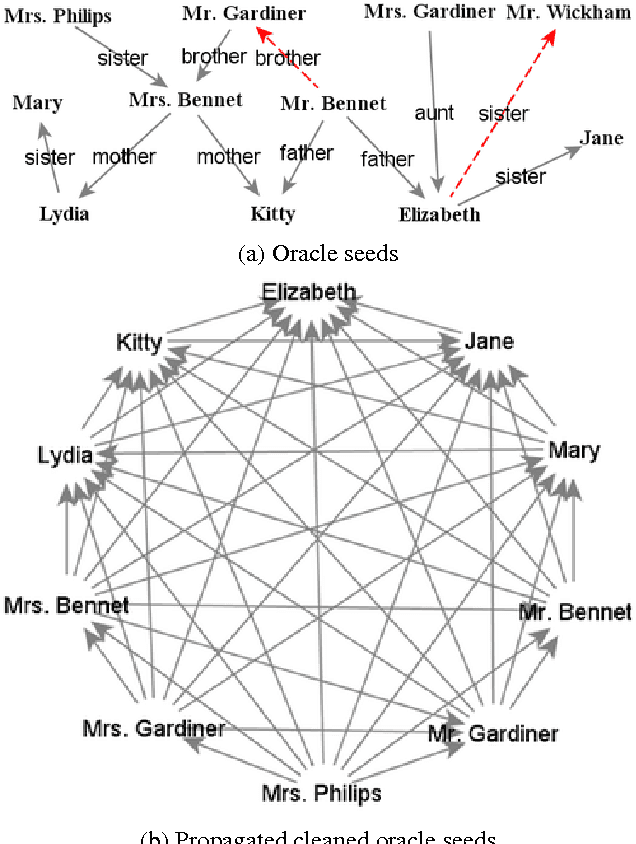
We present an approach to the extraction of family relations from literary narrative, which incorporates a technique for utterance attribution proposed recently by Elson and McKeown (2010). In our work this technique is used in combination with the detection of vocatives - the explicit forms of address used by the characters in a novel. We take advantage of the fact that certain vocatives indicate family relations between speakers. The extracted relations are then propagated using a set of rules. We report the results of the application of our method to Jane Austen's Pride and Prejudice.