 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the relationships between pretraining language, phonetic, tonal, and speaker information in self-supervised speech models
Jun 12, 2025


Analyses of self-supervised speech models have begun to reveal where and how they represent different types of information. However, almost all analyses have focused on English. Here, we examine how wav2vec2 models trained on four different languages encode both language-matched and non-matched speech. We use probing classifiers and geometric analyses to examine how phones, lexical tones, and speaker information are represented. We show that for all pretraining and test languages, the subspaces encoding phones, tones, and speakers are largely orthogonal, and that layerwise patterns of probing accuracy are similar, with a relatively small advantage for matched-language phone and tone (but not speaker) probes in the later layers. Our findings suggest that the structure of representations learned by wav2vec2 is largely independent of the speech material used during pretraining.
Effective Context in Neural Speech Models
May 28, 2025
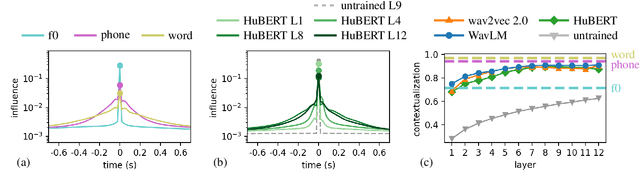
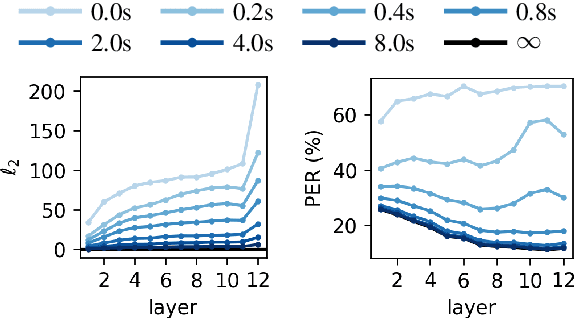
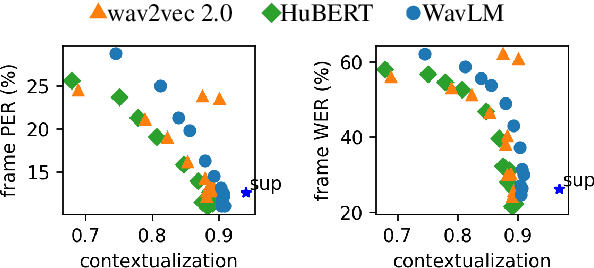
Modern neural speech models benefit from having longer context, and many approaches have been proposed to increase the maximum context a model can use. However, few have attempted to measure how much context these models actually use, i.e., the effective context. Here, we propose two approaches to measuring the effective context, and use them to analyze different speech Transformers. For supervised models, we find that the effective context correlates well with the nature of the task, with fundamental frequency tracking, phone classification, and word classification requiring increasing amounts of effective context. For self-supervised models, we find that effective context increases mainly in the early layers, and remains relatively short -- similar to the supervised phone model. Given that these models do not use a long context during prediction, we show that HuBERT can be run in streaming mode without modification to the architecture and without further fine-tuning.
Revisiting Common Assumptions about Arabic Dialects in NLP
May 27, 2025



Arabic has diverse dialects, where one dialect can be substantially different from the others. In the NLP literature, some assumptions about these dialects are widely adopted (e.g., ``Arabic dialects can be grouped into distinguishable regional dialects") and are manifested in different computational tasks such as Arabic Dialect Identification (ADI). However, these assumptions are not quantitatively verified. We identify four of these assumptions and examine them by extending and analyzing a multi-label dataset, where the validity of each sentence in 11 different country-level dialects is manually assessed by speakers of these dialects. Our analysis indicates that the four assumptions oversimplify reality, and some of them are not always accurate. This in turn might be hindering further progress in different Arabic NLP tasks.
A Grounded Typology of Word Classes
Dec 13, 2024We propose a grounded approach to meaning in language typology. We treat data from perceptual modalities, such as images, as a language-agnostic representation of meaning. Hence, we can quantify the function--form relationship between images and captions across languages. Inspired by information theory, we define "groundedness", an empirical measure of contextual semantic contentfulness (formulated as a difference in surprisal) which can be computed with multilingual multimodal language models. As a proof of concept, we apply this measure to the typology of word classes. Our measure captures the contentfulness asymmetry between functional (grammatical) and lexical (content) classes across languages, but contradicts the view that functional classes do not convey content. Moreover, we find universal trends in the hierarchy of groundedness (e.g., nouns > adjectives > verbs), and show that our measure partly correlates with psycholinguistic concreteness norms in English. We release a dataset of groundedness scores for 30 languages. Our results suggest that the grounded typology approach can provide quantitative evidence about semantic function in language.
Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations
Jun 13, 2024

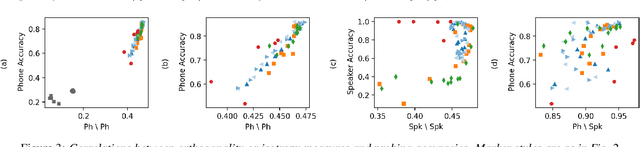
Self-supervised speech representations can hugely benefit downstream speech technologies, yet the properties that make them useful are still poorly understood. Two candidate properties related to the geometry of the representation space have been hypothesized to correlate well with downstream tasks: (1) the degree of orthogonality between the subspaces spanned by the speaker centroids and phone centroids, and (2) the isotropy of the space, i.e., the degree to which all dimensions are effectively utilized. To study them, we introduce a new measure, Cumulative Residual Variance (CRV), which can be used to assess both properties. Using linear classifiers for speaker and phone ID to probe the representations of six different self-supervised models and two untrained baselines, we ask whether either orthogonality or isotropy correlate with linear probing accuracy. We find that both measures correlate with phonetic probing accuracy, though our results on isotropy are more nuanced.
Estimating the Level of Dialectness Predicts Interannotator Agreement in Multi-dialect Arabic Datasets
May 18, 2024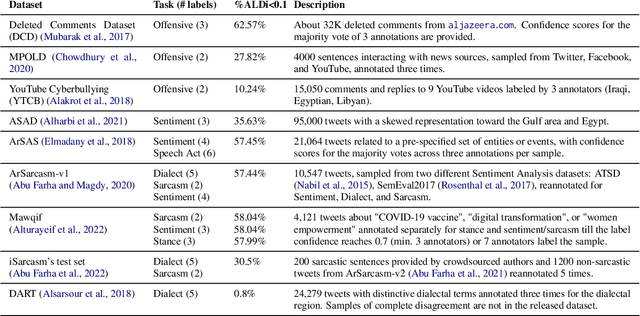
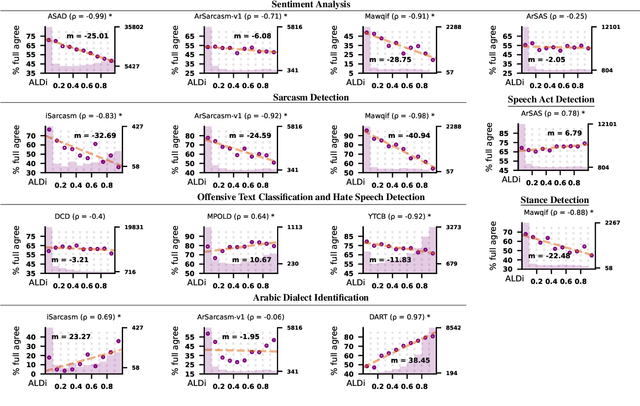

On annotating multi-dialect Arabic datasets, it is common to randomly assign the samples across a pool of native Arabic speakers. Recent analyses recommended routing dialectal samples to native speakers of their respective dialects to build higher-quality datasets. However, automatically identifying the dialect of samples is hard. Moreover, the pool of annotators who are native speakers of specific Arabic dialects might be scarce. Arabic Level of Dialectness (ALDi) was recently introduced as a quantitative variable that measures how sentences diverge from Standard Arabic. On randomly assigning samples to annotators, we hypothesize that samples of higher ALDi scores are harder to label especially if they are written in dialects that the annotators do not speak. We test this by analyzing the relation between ALDi scores and the annotators' agreement, on 15 public datasets having raw individual sample annotations for various sentence-classification tasks. We find strong evidence supporting our hypothesis for 11 of them. Consequently, we recommend prioritizing routing samples of high ALDi scores to native speakers of each sample's dialect, for which the dialect could be automatically identified at higher accuracies.
A predictive learning model can simulate temporal dynamics and context effects found in neural representations of continuous speech
May 13, 2024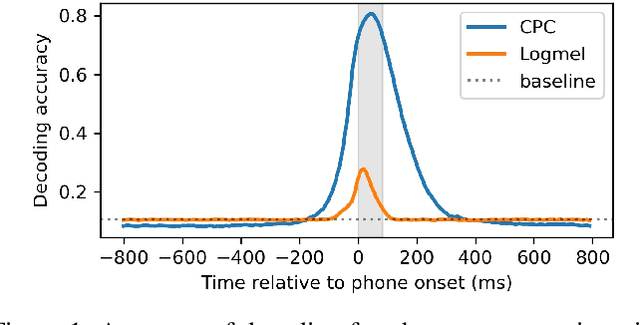
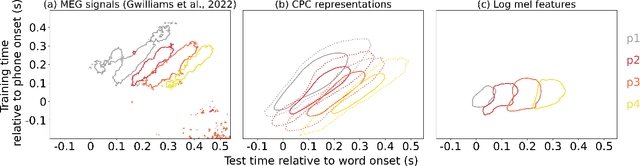
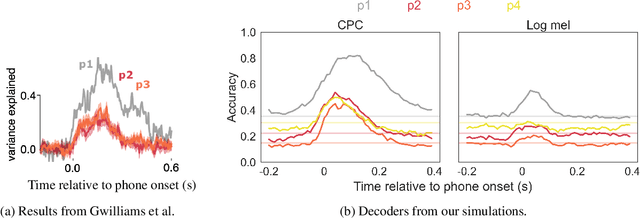
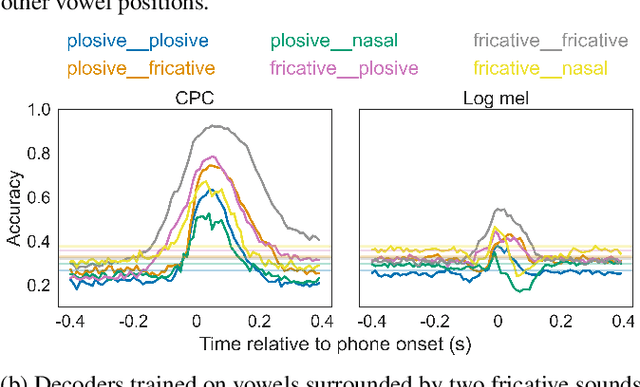
Speech perception involves storing and integrating sequentially presented items. Recent work in cognitive neuroscience has identified temporal and contextual characteristics in humans' neural encoding of speech that may facilitate this temporal processing. In this study, we simulated similar analyses with representations extracted from a computational model that was trained on unlabelled speech with the learning objective of predicting upcoming acoustics. Our simulations revealed temporal dynamics similar to those in brain signals, implying that these properties can arise without linguistic knowledge. Another property shared between brains and the model is that the encoding patterns of phonemes support some degree of cross-context generalization. However, we found evidence that the effectiveness of these generalizations depends on the specific contexts, which suggests that this analysis alone is insufficient to support the presence of context-invariant encoding.
ALDi: Quantifying the Arabic Level of Dialectness of Text
Oct 20, 2023



Transcribed speech and user-generated text in Arabic typically contain a mixture of Modern Standard Arabic (MSA), the standardized language taught in schools, and Dialectal Arabic (DA), used in daily communications. To handle this variation, previous work in Arabic NLP has focused on Dialect Identification (DI) on the sentence or the token level. However, DI treats the task as binary, whereas we argue that Arabic speakers perceive a spectrum of dialectness, which we operationalize at the sentence level as the Arabic Level of Dialectness (ALDi), a continuous linguistic variable. We introduce the AOC-ALDi dataset (derived from the AOC dataset), containing 127,835 sentences (17% from news articles and 83% from user comments on those articles) which are manually labeled with their level of dialectness. We provide a detailed analysis of AOC-ALDi and show that a model trained on it can effectively identify levels of dialectness on a range of other corpora (including dialects and genres not included in AOC-ALDi), providing a more nuanced picture than traditional DI systems. Through case studies, we illustrate how ALDi can reveal Arabic speakers' stylistic choices in different situations, a useful property for sociolinguistic analyses.
Acoustic Word Embeddings for Untranscribed Target Languages with Continued Pretraining and Learned Pooling
Jun 03, 2023

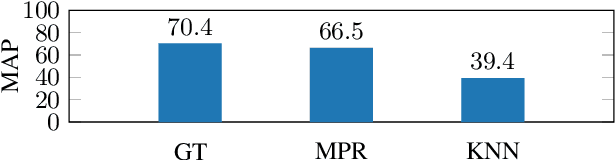

Acoustic word embeddings are typically created by training a pooling function using pairs of word-like units. For unsupervised systems, these are mined using k-nearest neighbor (KNN) search, which is slow. Recently, mean-pooled representations from a pre-trained self-supervised English model were suggested as a promising alternative, but their performance on target languages was not fully competitive. Here, we explore improvements to both approaches: we use continued pre-training to adapt the self-supervised model to the target language, and we use a multilingual phone recognizer (MPR) to mine phone n-gram pairs for training the pooling function. Evaluating on four languages, we show that both methods outperform a recent approach on word discrimination. Moreover, the MPR method is orders of magnitude faster than KNN, and is highly data efficient. We also show a small improvement from performing learned pooling on top of the continued pre-trained representations.
Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces
May 21, 2023
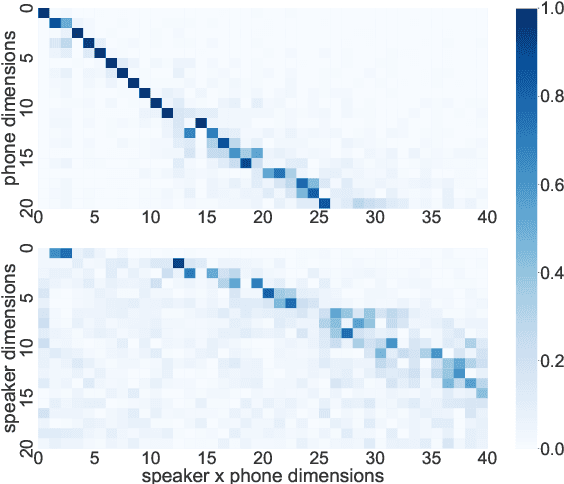
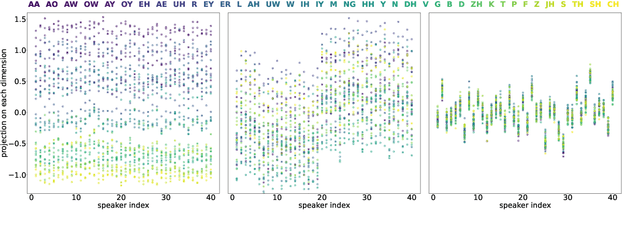
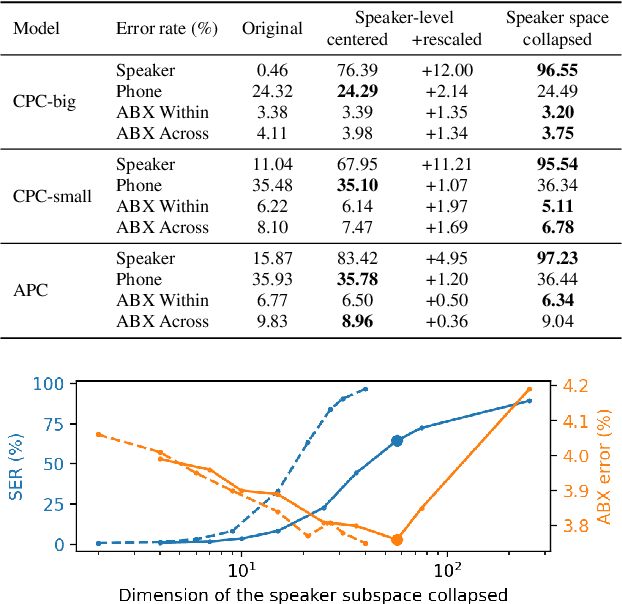
Self-supervised speech representations are known to encode both speaker and phonetic information, but how they are distributed in the high-dimensional space remains largely unexplored. We hypothesize that they are encoded in orthogonal subspaces, a property that lends itself to simple disentanglement. Applying principal component analysis to representations of two predictive coding models, we identify two subspaces that capture speaker and phonetic variances, and confirm that they are nearly orthogonal. Based on this property, we propose a new speaker normalization method which collapses the subspace that encodes speaker information, without requiring transcriptions. Probing experiments show that our method effectively eliminates speaker information and outperforms a previous baseline in phone discrimination tasks. Moreover, the approach generalizes and can be used to remove information of unseen speakers.