 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Level of Dialectness Predicts Interannotator Agreement in Multi-dialect Arabic Datasets
Paper and Code
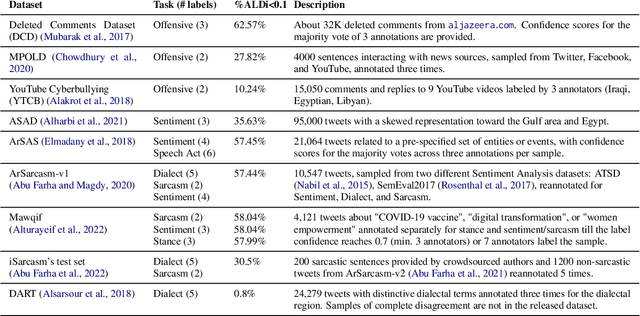
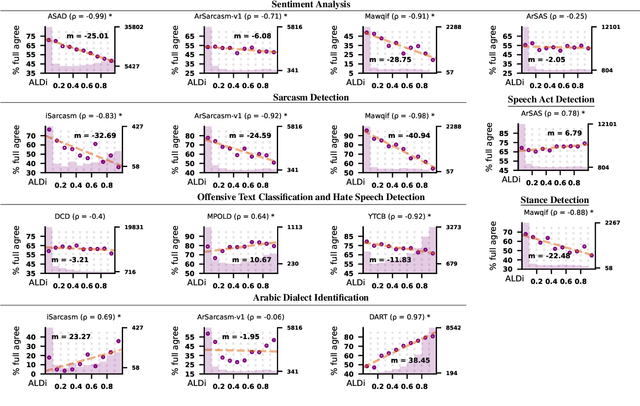

On annotating multi-dialect Arabic datasets, it is common to randomly assign the samples across a pool of native Arabic speakers. Recent analyses recommended routing dialectal samples to native speakers of their respective dialects to build higher-quality datasets. However, automatically identifying the dialect of samples is hard. Moreover, the pool of annotators who are native speakers of specific Arabic dialects might be scarce. Arabic Level of Dialectness (ALDi) was recently introduced as a quantitative variable that measures how sentences diverge from Standard Arabic. On randomly assigning samples to annotators, we hypothesize that samples of higher ALDi scores are harder to label especially if they are written in dialects that the annotators do not speak. We test this by analyzing the relation between ALDi scores and the annotators' agreement, on 15 public datasets having raw individual sample annotations for various sentence-classification tasks. We find strong evidence supporting our hypothesis for 11 of them. Consequently, we recommend prioritizing routing samples of high ALDi scores to native speakers of each sample's dialect, for which the dialect could be automatically identified at higher accuracies.