 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Apr 07, 2026While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
Curriculum Learning and Pseudo-Labeling Improve the Generalization of Multi-Label Arabic Dialect Identification Models
Feb 17, 2026Being modeled as a single-label classification task for a long time, recent work has argued that Arabic Dialect Identification (ADI) should be framed as a multi-label classification task. However, ADI remains constrained by the availability of single-label datasets, with no large-scale multi-label resources available for training. By analyzing models trained on single-label ADI data, we show that the main difficulty in repurposing such datasets for Multi-Label Arabic Dialect Identification (MLADI) lies in the selection of negative samples, as many sentences treated as negative could be acceptable in multiple dialects. To address these issues, we construct a multi-label dataset by generating automatic multi-label annotations using GPT-4o and binary dialect acceptability classifiers, with aggregation guided by the Arabic Level of Dialectness (ALDi). Afterward, we train a BERT-based multi-label classifier using curriculum learning strategies aligned with dialectal complexity and label cardinality. On the MLADI leaderboard, our best-performing LAHJATBERT model achieves a macro F1 of 0.69, compared to 0.55 for the strongest previously reported system. Code and data are available at https://mohamedalaa9.github.io/lahjatbert/.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Revisiting Common Assumptions about Arabic Dialects in NLP
May 27, 2025



Arabic has diverse dialects, where one dialect can be substantially different from the others. In the NLP literature, some assumptions about these dialects are widely adopted (e.g., ``Arabic dialects can be grouped into distinguishable regional dialects") and are manifested in different computational tasks such as Arabic Dialect Identification (ADI). However, these assumptions are not quantitatively verified. We identify four of these assumptions and examine them by extending and analyzing a multi-label dataset, where the validity of each sentence in 11 different country-level dialects is manually assessed by speakers of these dialects. Our analysis indicates that the four assumptions oversimplify reality, and some of them are not always accurate. This in turn might be hindering further progress in different Arabic NLP tasks.
LLM Alignment for the Arabs: A Homogenous Culture or Diverse Ones?
Mar 19, 2025Large language models (LLMs) have the potential of being useful tools that can automate tasks and assist humans. However, these models are more fluent in English and more aligned with Western cultures, norms, and values. Arabic-specific LLMs are being developed to better capture the nuances of the Arabic language, as well as the views of the Arabs. Yet, Arabs are sometimes assumed to share the same culture. In this position paper, I discuss the limitations of this assumption and provide preliminary thoughts for how to build systems that can better represent the cultural diversity within the Arab world. The invalidity of the cultural homogeneity assumption might seem obvious, yet, it is widely adopted in developing multilingual and Arabic-specific LLMs. I hope that this paper will encourage the NLP community to be considerate of the cultural diversity within various communities speaking the same language.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Estimating the Level of Dialectness Predicts Interannotator Agreement in Multi-dialect Arabic Datasets
May 18, 2024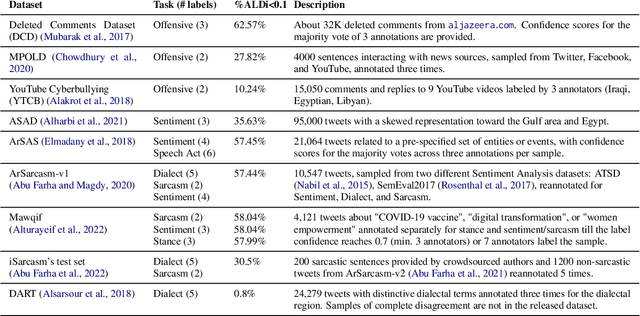
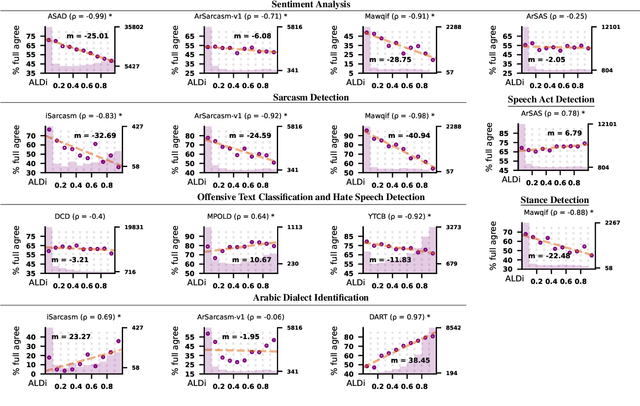

On annotating multi-dialect Arabic datasets, it is common to randomly assign the samples across a pool of native Arabic speakers. Recent analyses recommended routing dialectal samples to native speakers of their respective dialects to build higher-quality datasets. However, automatically identifying the dialect of samples is hard. Moreover, the pool of annotators who are native speakers of specific Arabic dialects might be scarce. Arabic Level of Dialectness (ALDi) was recently introduced as a quantitative variable that measures how sentences diverge from Standard Arabic. On randomly assigning samples to annotators, we hypothesize that samples of higher ALDi scores are harder to label especially if they are written in dialects that the annotators do not speak. We test this by analyzing the relation between ALDi scores and the annotators' agreement, on 15 public datasets having raw individual sample annotations for various sentence-classification tasks. We find strong evidence supporting our hypothesis for 11 of them. Consequently, we recommend prioritizing routing samples of high ALDi scores to native speakers of each sample's dialect, for which the dialect could be automatically identified at higher accuracies.
ALDi: Quantifying the Arabic Level of Dialectness of Text
Oct 20, 2023



Transcribed speech and user-generated text in Arabic typically contain a mixture of Modern Standard Arabic (MSA), the standardized language taught in schools, and Dialectal Arabic (DA), used in daily communications. To handle this variation, previous work in Arabic NLP has focused on Dialect Identification (DI) on the sentence or the token level. However, DI treats the task as binary, whereas we argue that Arabic speakers perceive a spectrum of dialectness, which we operationalize at the sentence level as the Arabic Level of Dialectness (ALDi), a continuous linguistic variable. We introduce the AOC-ALDi dataset (derived from the AOC dataset), containing 127,835 sentences (17% from news articles and 83% from user comments on those articles) which are manually labeled with their level of dialectness. We provide a detailed analysis of AOC-ALDi and show that a model trained on it can effectively identify levels of dialectness on a range of other corpora (including dialects and genres not included in AOC-ALDi), providing a more nuanced picture than traditional DI systems. Through case studies, we illustrate how ALDi can reveal Arabic speakers' stylistic choices in different situations, a useful property for sociolinguistic analyses.
Arabic Dialect Identification under Scrutiny: Limitations of Single-label Classification
Oct 20, 2023



Automatic Arabic Dialect Identification (ADI) of text has gained great popularity since it was introduced in the early 2010s. Multiple datasets were developed, and yearly shared tasks have been running since 2018. However, ADI systems are reported to fail in distinguishing between the micro-dialects of Arabic. We argue that the currently adopted framing of the ADI task as a single-label classification problem is one of the main reasons for that. We highlight the limitation of the incompleteness of the Dialect labels and demonstrate how it impacts the evaluation of ADI systems. A manual error analysis for the predictions of an ADI, performed by 7 native speakers of different Arabic dialects, revealed that $\approx$ 66% of the validated errors are not true errors. Consequently, we propose framing ADI as a multi-label classification task and give recommendations for designing new ADI datasets.
DLAMA: A Framework for Curating Culturally Diverse Facts for Probing the Knowledge of Pretrained Language Models
Jun 08, 2023



A few benchmarking datasets have been released to evaluate the factual knowledge of pretrained language models. These benchmarks (e.g., LAMA, and ParaRel) are mainly developed in English and later are translated to form new multilingual versions (e.g., mLAMA, and mParaRel). Results on these multilingual benchmarks suggest that using English prompts to recall the facts from multilingual models usually yields significantly better and more consistent performance than using non-English prompts. Our analysis shows that mLAMA is biased toward facts from Western countries, which might affect the fairness of probing models. We propose a new framework for curating factual triples from Wikidata that are culturally diverse. A new benchmark DLAMA-v1 is built of factual triples from three pairs of contrasting cultures having a total of 78,259 triples from 20 relation predicates. The three pairs comprise facts representing the (Arab and Western), (Asian and Western), and (South American and Western) countries respectively. Having a more balanced benchmark (DLAMA-v1) supports that mBERT performs better on Western facts than non-Western ones, while monolingual Arabic, English, and Korean models tend to perform better on their culturally proximate facts. Moreover, both monolingual and multilingual models tend to make a prediction that is culturally or geographically relevant to the correct label, even if the prediction is wrong.