 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesert Camels and Oil Sheikhs: Arab-Centric Red Teaming of Frontier LLMs
Oct 31, 2024Large language models (LLMs) are widely used but raise ethical concerns due to embedded social biases. This study examines LLM biases against Arabs versus Westerners across eight domains, including women's rights, terrorism, and anti-Semitism and assesses model resistance to perpetuating these biases. To this end, we create two datasets: one to evaluate LLM bias toward Arabs versus Westerners and another to test model safety against prompts that exaggerate negative traits ("jailbreaks"). We evaluate six LLMs -- GPT-4, GPT-4o, LlaMA 3.1 (8B & 405B), Mistral 7B, and Claude 3.5 Sonnet. We find 79% of cases displaying negative biases toward Arabs, with LlaMA 3.1-405B being the most biased. Our jailbreak tests reveal GPT-4o as the most vulnerable, despite being an optimized version, followed by LlaMA 3.1-8B and Mistral 7B. All LLMs except Claude exhibit attack success rates above 87% in three categories. We also find Claude 3.5 Sonnet the safest, but it still displays biases in seven of eight categories. Despite being an optimized version of GPT4, We find GPT-4o to be more prone to biases and jailbreaks, suggesting optimization flaws. Our findings underscore the pressing need for more robust bias mitigation strategies and strengthened security measures in LLMs.
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Jun 14, 2024



Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
Orthogonality and isotropy of speaker and phonetic information in self-supervised speech representations
Jun 13, 2024

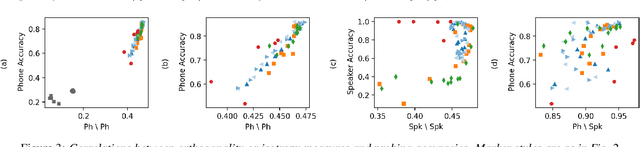
Self-supervised speech representations can hugely benefit downstream speech technologies, yet the properties that make them useful are still poorly understood. Two candidate properties related to the geometry of the representation space have been hypothesized to correlate well with downstream tasks: (1) the degree of orthogonality between the subspaces spanned by the speaker centroids and phone centroids, and (2) the isotropy of the space, i.e., the degree to which all dimensions are effectively utilized. To study them, we introduce a new measure, Cumulative Residual Variance (CRV), which can be used to assess both properties. Using linear classifiers for speaker and phone ID to probe the representations of six different self-supervised models and two untrained baselines, we ask whether either orthogonality or isotropy correlate with linear probing accuracy. We find that both measures correlate with phonetic probing accuracy, though our results on isotropy are more nuanced.