 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonality and isotropy of speaker and phonetic information in self-supervised speech representations
Paper and Code
Jun 13, 2024

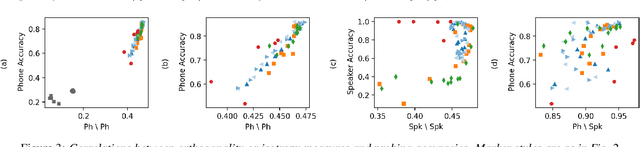
Self-supervised speech representations can hugely benefit downstream speech technologies, yet the properties that make them useful are still poorly understood. Two candidate properties related to the geometry of the representation space have been hypothesized to correlate well with downstream tasks: (1) the degree of orthogonality between the subspaces spanned by the speaker centroids and phone centroids, and (2) the isotropy of the space, i.e., the degree to which all dimensions are effectively utilized. To study them, we introduce a new measure, Cumulative Residual Variance (CRV), which can be used to assess both properties. Using linear classifiers for speaker and phone ID to probe the representations of six different self-supervised models and two untrained baselines, we ask whether either orthogonality or isotropy correlate with linear probing accuracy. We find that both measures correlate with phonetic probing accuracy, though our results on isotropy are more nuanced.