 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Entity Matching with Pre-Trained Language Models
Paper and Code


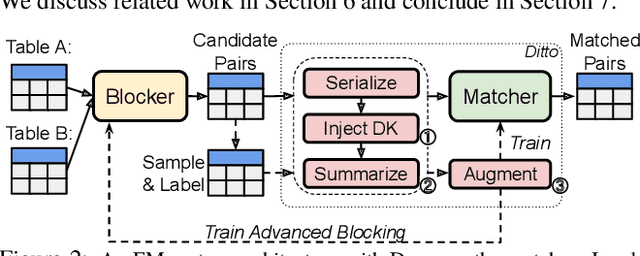

We present Ditto, a novel entity matching system based on pre-trained Transformer-based language models. We fine-tune and cast EM as a sequence-pair classification problem to leverage such models with a simple architecture. Our experiments show that a straightforward application of language models such as BERT, DistilBERT, or ALBERT pre-trained on large text corpora already significantly improves the matching quality and outperforms previous state-of-the-art (SOTA), by up to 19% of F1 score on benchmark datasets. We also developed three optimization techniques to further improve Ditto's matching capability. Ditto allows domain knowledge to be injected by highlighting important pieces of input information that may be of interest when making matching decisions. Ditto also summarizes strings that are too long so that only the essential information is retained and used for EM. Finally, Ditto adapts a SOTA technique on data augmentation for text to EM to augment the training data with (difficult) examples. This way, Ditto is forced to learn "harder" to improve the model's matching capability. The optimizations we developed further boost the performance of Ditto by up to 8.5%. Perhaps more surprisingly, we establish that Ditto can achieve the previous SOTA results with at most half the number of labeled data. Finally, we demonstrate Ditto's effectiveness on a real-world large-scale EM task. On matching two company datasets consisting of 789K and 412K records, Ditto achieves a high F1 score of 96.5%.