Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Parallel Passages Across a Large Hebrew/Aramaic Corpus
Paper and Code
Jan 01, 2018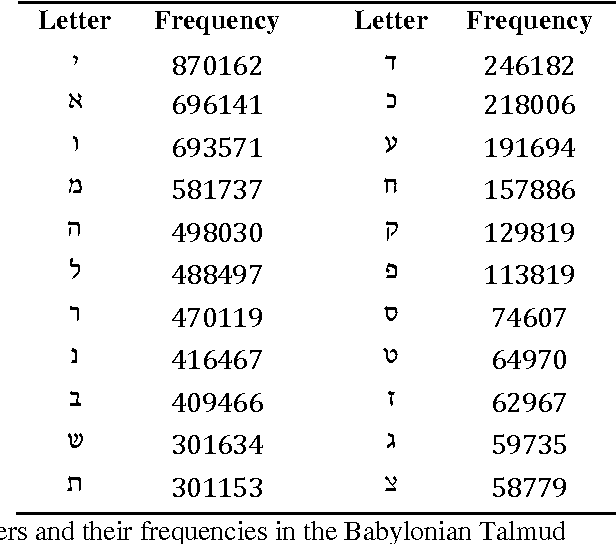



We propose a method for efficiently finding all parallel passages in a large corpus, even if the passages are not quite identical due to rephrasing and orthographic variation. The key ideas are the representation of each word in the corpus by its two most infrequent letters, finding matched pairs of strings of four or five words that differ by at most one word and then identifying clusters of such matched pairs. Using this method, over 4600 parallel pairs of passages were identified in the Babylonian Talmud, a Hebrew-Aramaic corpus of over 1.8 million words, in just over 30 seconds. Empirical comparisons on sample data indicate that the coverage obtained by our method is essentially the same as that obtained using slow exhaustive methods.
* Journal of Data Mining & Digital Humanities, Special Issue on
Computer-Aided Processing of Intertextuality in Ancient Languages, Towards a
Digital Ecosystem: NLP. Corpus infrastructure. Methods for Retrieving Texts
and Computing Text Similarities (March 11, 2018) jdmdh:4175 * Submission to the Journal of Data Mining and Digital Humanities
(Special Issue on Computer-Aided Processing of Intertextuality in Ancient
Languages)
View paper on