 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"What's my model inside of?": Exploring the role of environments for grounded natural language understanding
Feb 04, 2024In contrast to classical cognitive science which studied brains in isolation, ecological approaches focused on the role of the body and environment in shaping cognition. Similarly, in this thesis we adopt an ecological approach to grounded natural language understanding (NLU) research. Grounded language understanding studies language understanding systems situated in the context of events, actions and precepts in naturalistic/simulated virtual environments. Where classic research tends to focus on designing new models and optimization methods while treating environments as given, we explore the potential of environment design for improving data collection and model development. We developed novel training and annotation approaches for procedural text understanding based on text-based game environments. We also drew upon embodied cognitive linguistics literature to propose a roadmap for grounded NLP research, and to inform the development of a new benchmark for measuring the progress of large language models on challenging commonsense reasoning tasks. We leveraged the richer supervision provided by text-based game environments to develop Breakpoint Transformers, a novel approach to modeling intermediate semantic information in long narrative or procedural texts. Finally, we integrated theories on the role of environments in collective human intelligence to propose a design for AI-augmented "social thinking environments" for knowledge workers like scientists.
Breakpoint Transformers for Modeling and Tracking Intermediate Beliefs
Nov 15, 2022



Can we teach natural language understanding models to track their beliefs through intermediate points in text? We propose a representation learning framework called breakpoint modeling that allows for learning of this type. Given any text encoder and data marked with intermediate states (breakpoints) along with corresponding textual queries viewed as true/false propositions (i.e., the candidate beliefs of a model, consisting of information changing through time) our approach trains models in an efficient and end-to-end fashion to build intermediate representations that facilitate teaching and direct querying of beliefs at arbitrary points alongside solving other end tasks. To show the benefit of our approach, we experiment with a diverse set of NLU tasks including relational reasoning on CLUTRR and narrative understanding on bAbI. Using novel belief prediction tasks for both tasks, we show the benefit of our main breakpoint transformer, based on T5, over conventional representation learning approaches in terms of processing efficiency, prediction accuracy and prediction consistency, all with minimal to no effect on corresponding QA end tasks. To show the feasibility of incorporating our belief tracker into more complex reasoning pipelines, we also obtain SOTA performance on the three-tiered reasoning challenge for the TRIP benchmark (around 23-32% absolute improvement on Tasks 2-3).
Dyna-bAbI: unlocking bAbI's potential with dynamic synthetic benchmarking
Nov 30, 2021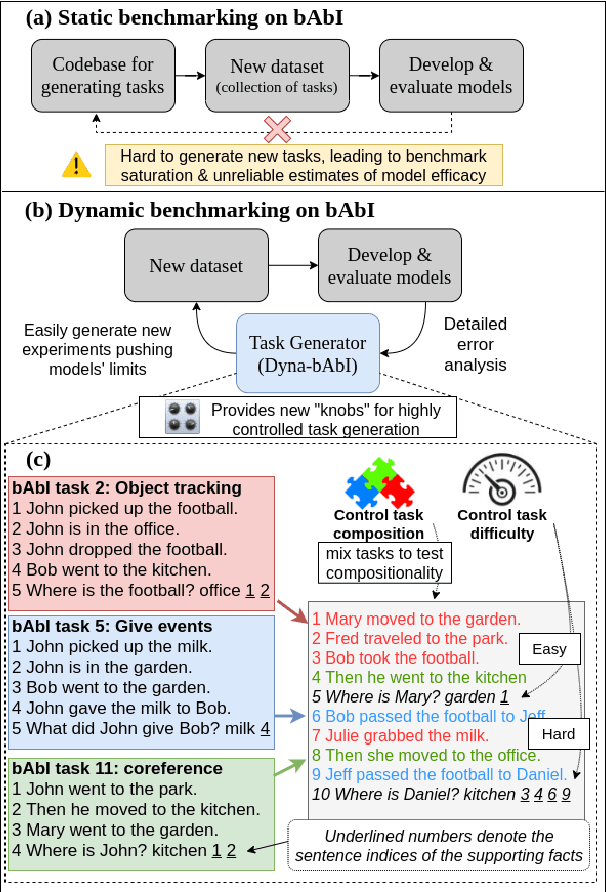
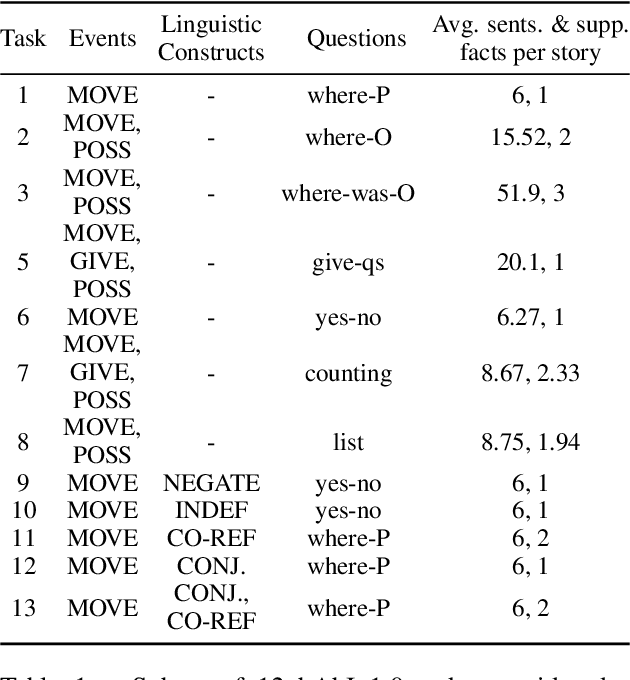
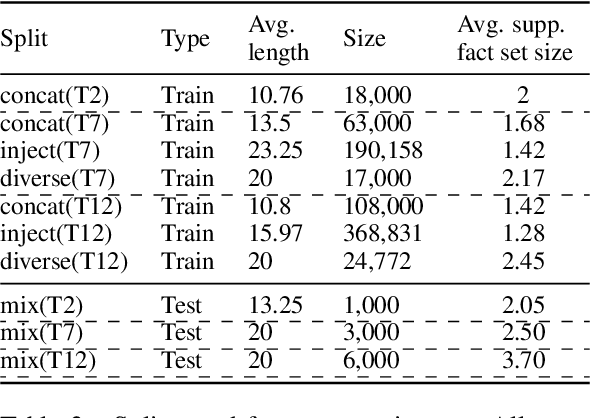
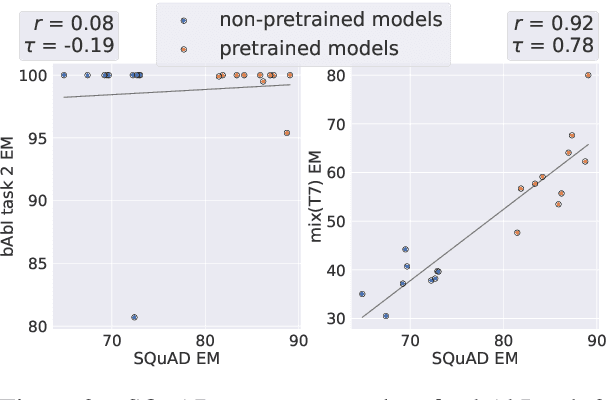
While neural language models often perform surprisingly well on natural language understanding (NLU) tasks, their strengths and limitations remain poorly understood. Controlled synthetic tasks are thus an increasingly important resource for diagnosing model behavior. In this work we focus on story understanding, a core competency for NLU systems. However, the main synthetic resource for story understanding, the bAbI benchmark, lacks such a systematic mechanism for controllable task generation. We develop Dyna-bAbI, a dynamic framework providing fine-grained control over task generation in bAbI. We demonstrate our ideas by constructing three new tasks requiring compositional generalization, an important evaluation setting absent from the original benchmark. We tested both special-purpose models developed for bAbI as well as state-of-the-art pre-trained methods, and found that while both approaches solve the original tasks (>99% accuracy), neither approach succeeded in the compositional generalization setting, indicating the limitations of the original training data. We explored ways to augment the original data, and found that though diversifying training data was far more useful than simply increasing dataset size, it was still insufficient for driving robust compositional generalization (with <70% accuracy for complex compositions). Our results underscore the importance of highly controllable task generators for creating robust NLU systems through a virtuous cycle of model and data development.
Scaling Creative Inspiration with Fine-Grained Functional Facets of Product Ideas
Feb 19, 2021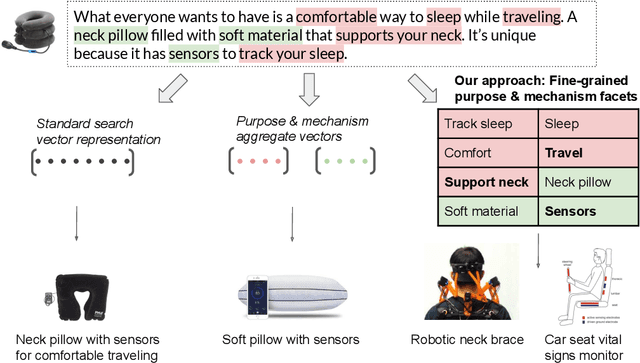

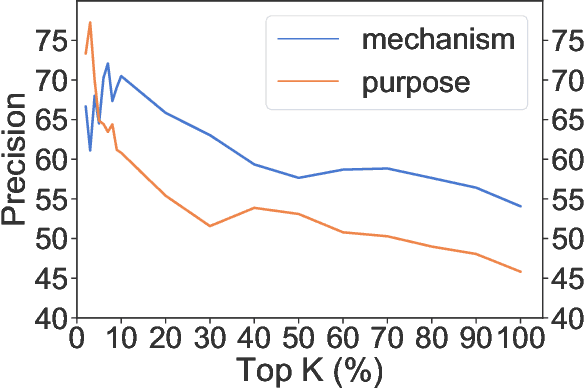
Web-scale repositories of products, patents and scientific papers offer an opportunity for creating automated systems that scour millions of ideas and assist users in discovering inspirations and solutions. Yet the common representation of ideas is in the form of raw textual descriptions, lacking important structure that is required for supporting creative innovation. Prior work has pointed to the importance of functional structure -- capturing the mechanisms and purposes of inventions -- for allowing users to discover structural connections across ideas and creatively adapt existing technologies. However, the use of functional representations was either coarse and limited in expressivity, or dependent on curated knowledge bases with poor coverage and significant manual effort from users. To help bridge this gap and unlock the potential of large-scale idea mining, we propose a novel computational representation that automatically breaks up products into fine-grained functional facets. We train a model to extract these facets from a challenging real-world corpus of invention descriptions, and represent each product as a set of facet embeddings. We design similarity metrics that support granular matching between functional facets across ideas, and use them to build a novel functional search capability that enables expressive queries for mechanisms and purposes. We construct a graph capturing hierarchical relations between purposes and mechanisms across an entire corpus of products, and use the graph to help problem-solvers explore the design space around a focal problem and view related problem perspectives. In empirical user studies, our approach leads to a significant boost in search accuracy and in the quality of creative inspirations, outperforming strong baselines and state-of-art representations of product texts by 50-60%.
Process-Level Representation of Scientific Protocols with Interactive Annotation
Jan 25, 2021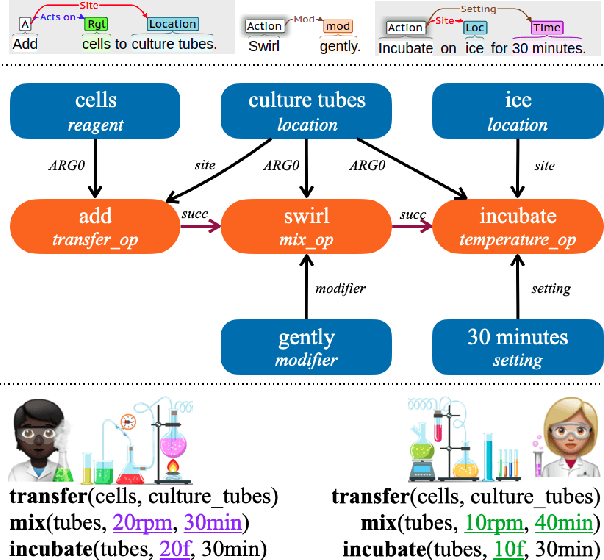
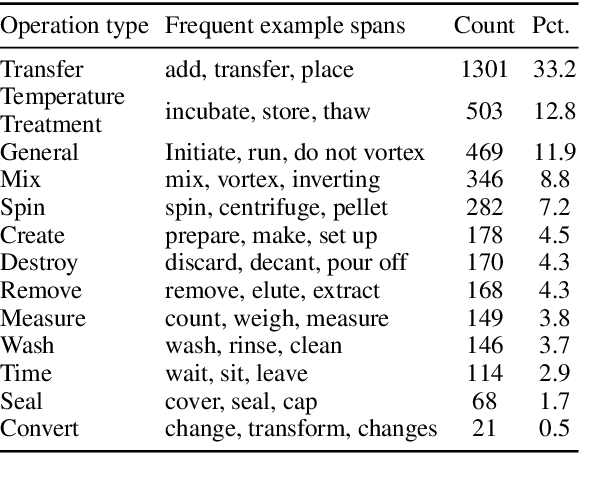
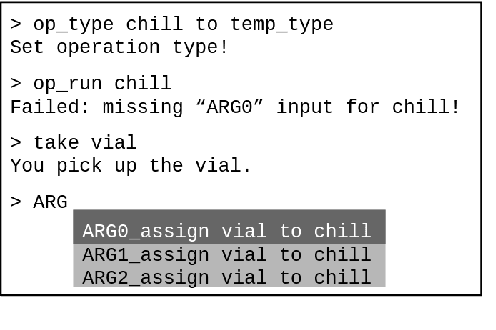

We develop Process Execution Graphs~(PEG), a document-level representation of real-world wet lab biochemistry protocols, addressing challenges such as cross-sentence relations, long-range coreference, grounding, and implicit arguments. We manually annotate PEGs in a corpus of complex lab protocols with a novel interactive textual simulator that keeps track of entity traits and semantic constraints during annotation. We use this data to develop graph-prediction models, finding them to be good at entity identification and local relation extraction, while our corpus facilitates further exploration of challenging long-range relations.
Language (Re)modelling: Towards Embodied Language Understanding
May 01, 2020

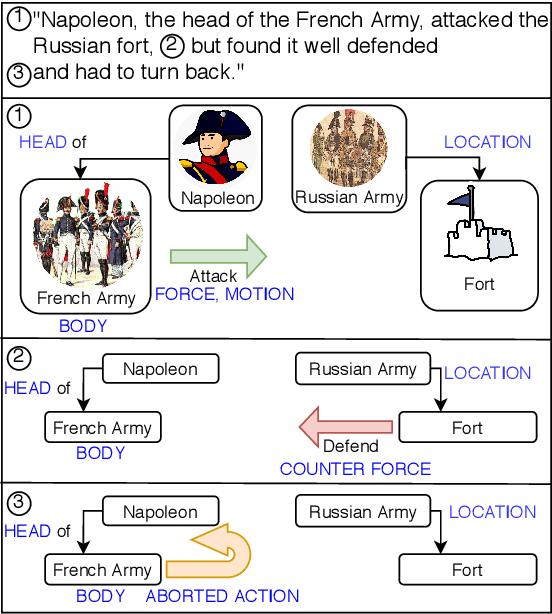
While natural language understanding (NLU) is advancing rapidly, today's technology differs from human-like language understanding in fundamental ways, notably in its inferior efficiency, interpretability, and generalization. This work proposes an approach to representation and learning based on the tenets of embodied cognitive linguistics (ECL). According to ECL, natural language is inherently executable (like programming languages), driven by mental simulation and metaphoric mappings over hierarchical compositions of structures and schemata learned through embodied interaction. This position paper argues that the use of grounding by metaphoric inference and simulation will greatly benefit NLU systems, and proposes a system architecture along with a roadmap towards realizing this vision.
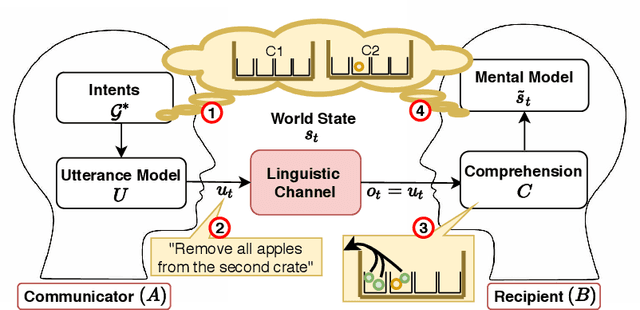
Ecological Semantics: Programming Environments for Situated Language Understanding
Mar 10, 2020
Large-scale natural language understanding (NLU) systems have made impressive progress: they can be applied flexibly across a variety of tasks, and employ minimal structural assumptions. However, extensive empirical research has shown this to be a double-edged sword, coming at the cost of shallow understanding: inferior generalization, grounding and explainability. Grounded language learning approaches offer the promise of deeper understanding by situating learning in richer, more structured training environments, but are limited in scale to relatively narrow, predefined domains. How might we enjoy the best of both worlds: grounded, general NLU? Following extensive contemporary cognitive science, we propose treating environments as ``first-class citizens'' in semantic representations, worthy of research and development in their own right. Importantly, models should also be partners in the creation and configuration of environments, rather than just actors within them, as in existing approaches. To do so, we argue that models must begin to understand and program in the language of affordances (which define possible actions in a given situation) both for online, situated discourse comprehension, as well as large-scale, offline common-sense knowledge mining. To this end we propose an environment-oriented ecological semantics, outlining theoretical and practical approaches towards implementation. We further provide actual demonstrations building upon interactive fiction programming languages.
Yall should read this! Identifying Plurality in Second-Person Personal Pronouns in English Texts
Oct 26, 2019



Distinguishing between singular and plural "you" in English is a challenging task which has potential for downstream applications, such as machine translation or coreference resolution. While formal written English does not distinguish between these cases, other languages (such as Spanish), as well as other dialects of English (via phrases such as "yall"), do make this distinction. We make use of this to obtain distantly-supervised labels for the task on a large-scale in two domains. Following, we train a model to distinguish between the single/plural you, finding that although in-domain training achieves reasonable accuracy (over 77%), there is still a lot of room for improvement, especially in the domain-transfer scenario, which proves extremely challenging. Our code and data are publicly available.
Playing by the Book: Towards Agent-based Narrative Understanding through Role-playing and Simulation
Nov 10, 2018



Understanding procedural text requires tracking entities, actions and effects as the narrative unfolds (often implicitly). We focus on the challenging real-world problem of structured narrative extraction in the materials science domain, where language is highly specialized and suitable annotated data is not publicly available. We propose an approach, Text2Quest, where procedural text is interpreted as instructions for an interactive game. A reinforcement-learning agent completes the game by understanding and executing the procedure correctly, in a text-based simulated lab environment. The framework is intended to be more broadly applicable to other domain-specific and data-scarce settings. We conclude with a discussion of challenges and interesting potential extensions enabled by the agent-based perspective.
Analysis and Design of Convolutional Networks via Hierarchical Tensor Decompositions
Jun 11, 2018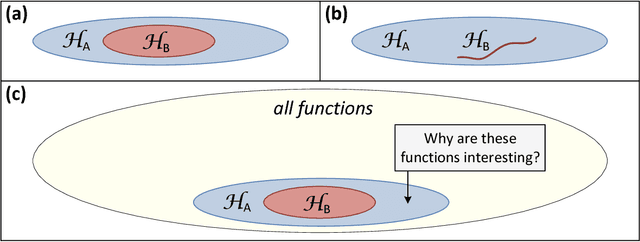
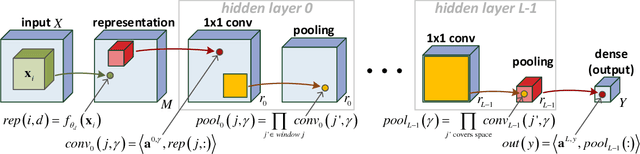
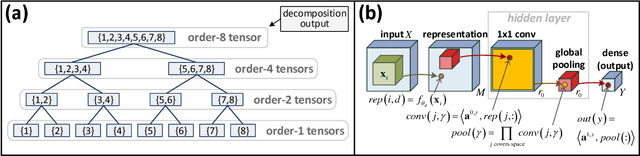
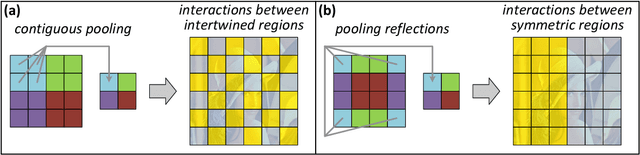
The driving force behind convolutional networks - the most successful deep learning architecture to date, is their expressive power. Despite its wide acceptance and vast empirical evidence, formal analyses supporting this belief are scarce. The primary notions for formally reasoning about expressiveness are efficiency and inductive bias. Expressive efficiency refers to the ability of a network architecture to realize functions that require an alternative architecture to be much larger. Inductive bias refers to the prioritization of some functions over others given prior knowledge regarding a task at hand. In this paper we overview a series of works written by the authors, that through an equivalence to hierarchical tensor decompositions, analyze the expressive efficiency and inductive bias of various convolutional network architectural features (depth, width, strides and more). The results presented shed light on the demonstrated effectiveness of convolutional networks, and in addition, provide new tools for network design.