 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Models, Big Results: Achieving Superior Intent Extraction through Decomposition
Sep 15, 2025Understanding user intents from UI interaction trajectories remains a challenging, yet crucial, frontier in intelligent agent development. While massive, datacenter-based, multi-modal large language models (MLLMs) possess greater capacity to handle the complexities of such sequences, smaller models which can run on-device to provide a privacy-preserving, low-cost, and low-latency user experience, struggle with accurate intent inference. We address these limitations by introducing a novel decomposed approach: first, we perform structured interaction summarization, capturing key information from each user action. Second, we perform intent extraction using a fine-tuned model operating on the aggregated summaries. This method improves intent understanding in resource-constrained models, even surpassing the base performance of large MLLMs.
Identifying User Goals from UI Trajectories
Jun 20, 2024
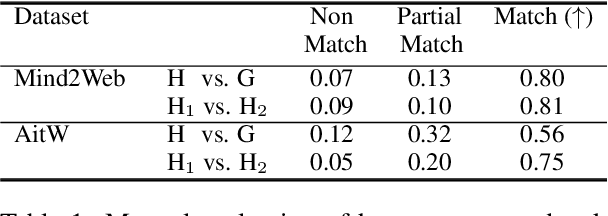
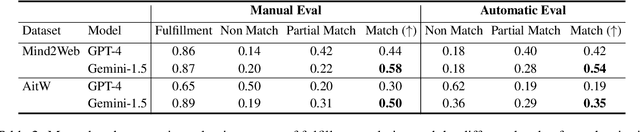
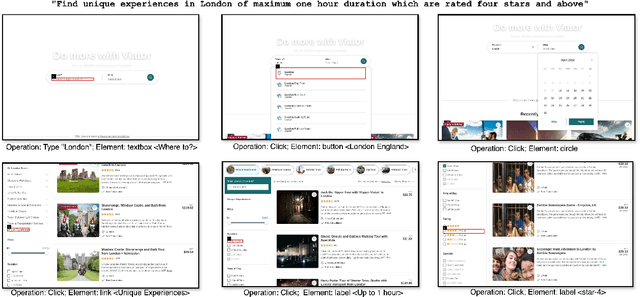
Autonomous agents that interact with graphical user interfaces (GUIs) hold significant potential for enhancing user experiences. To further improve these experiences, agents need to be personalized and proactive. By effectively comprehending user intentions through their actions and interactions with GUIs, agents will be better positioned to achieve these goals. This paper introduces the task of goal identification from observed UI trajectories, aiming to infer the user's intended task based on their GUI interactions. We propose a novel evaluation metric to assess whether two task descriptions are paraphrases within a specific UI environment. By Leveraging the inverse relation with the UI automation task, we utilized the Android-In-The-Wild and Mind2Web datasets for our experiments. Using our metric and these datasets, we conducted several experiments comparing the performance of humans and state-of-the-art models, specifically GPT-4 and Gemini-1.5 Pro. Our results show that Gemini performs better than GPT but still underperforms compared to humans, indicating significant room for improvement.
Dyna-bAbI: unlocking bAbI's potential with dynamic synthetic benchmarking
Nov 30, 2021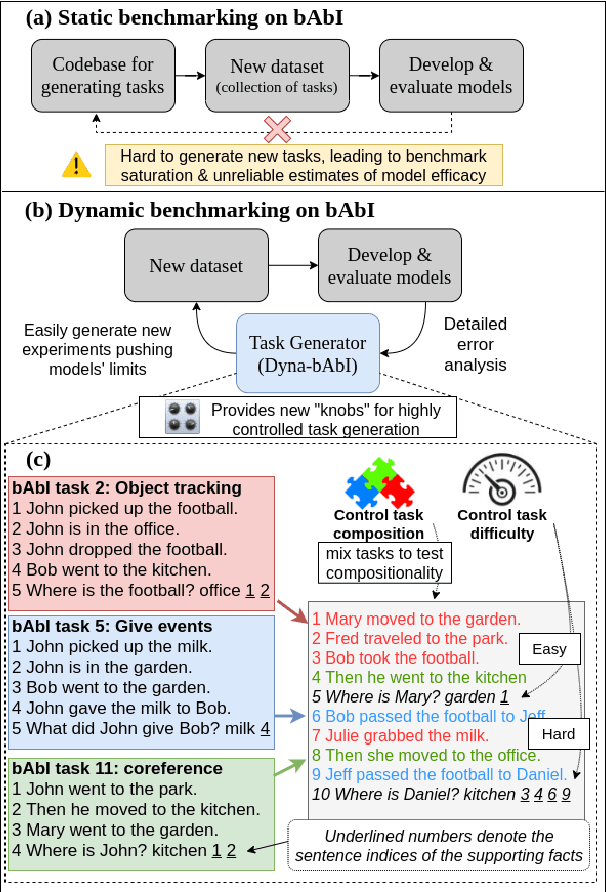
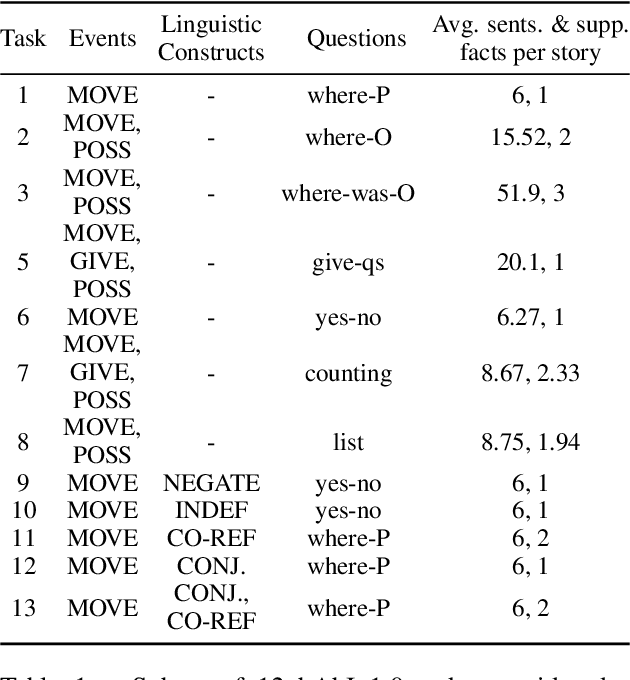
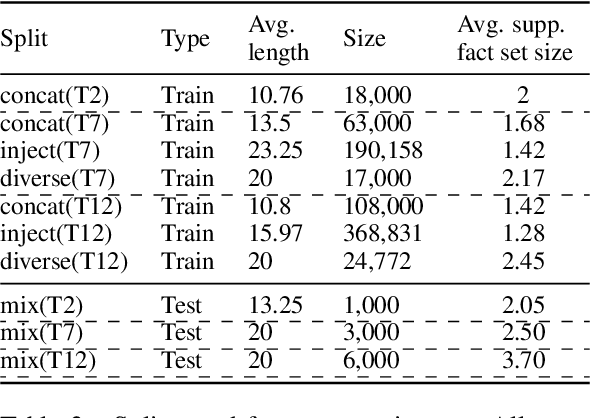
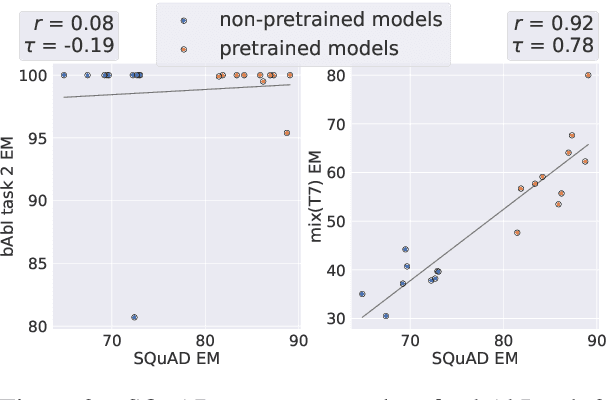
While neural language models often perform surprisingly well on natural language understanding (NLU) tasks, their strengths and limitations remain poorly understood. Controlled synthetic tasks are thus an increasingly important resource for diagnosing model behavior. In this work we focus on story understanding, a core competency for NLU systems. However, the main synthetic resource for story understanding, the bAbI benchmark, lacks such a systematic mechanism for controllable task generation. We develop Dyna-bAbI, a dynamic framework providing fine-grained control over task generation in bAbI. We demonstrate our ideas by constructing three new tasks requiring compositional generalization, an important evaluation setting absent from the original benchmark. We tested both special-purpose models developed for bAbI as well as state-of-the-art pre-trained methods, and found that while both approaches solve the original tasks (>99% accuracy), neither approach succeeded in the compositional generalization setting, indicating the limitations of the original training data. We explored ways to augment the original data, and found that though diversifying training data was far more useful than simply increasing dataset size, it was still insufficient for driving robust compositional generalization (with <70% accuracy for complex compositions). Our results underscore the importance of highly controllable task generators for creating robust NLU systems through a virtuous cycle of model and data development.