 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
Inkspire: Supporting Design Exploration with Generative AI through Analogical Sketching
Jan 30, 2025



With recent advancements in the capabilities of Text-to-Image (T2I) AI models, product designers have begun experimenting with them in their work. However, T2I models struggle to interpret abstract language and the current user experience of T2I tools can induce design fixation rather than a more iterative, exploratory process. To address these challenges, we developed Inkspire, a sketch-driven tool that supports designers in prototyping product design concepts with analogical inspirations and a complete sketch-to-design-to-sketch feedback loop. To inform the design of Inkspire, we conducted an exchange session with designers and distilled design goals for improving T2I interactions. In a within-subjects study comparing Inkspire to ControlNet, we found that Inkspire supported designers with more inspiration and exploration of design ideas, and improved aspects of the co-creative process by allowing designers to effectively grasp the current state of the AI to guide it towards novel design intentions.
Imitation of Life: A Search Engine for Biologically Inspired Design
Dec 20, 2023Biologically Inspired Design (BID), or Biomimicry, is a problem-solving methodology that applies analogies from nature to solve engineering challenges. For example, Speedo engineers designed swimsuits based on shark skin. Finding relevant biological solutions for real-world problems poses significant challenges, both due to the limited biological knowledge engineers and designers typically possess and to the limited BID resources. Existing BID datasets are hand-curated and small, and scaling them up requires costly human annotations. In this paper, we introduce BARcode (Biological Analogy Retriever), a search engine for automatically mining bio-inspirations from the web at scale. Using advances in natural language understanding and data programming, BARcode identifies potential inspirations for engineering challenges. Our experiments demonstrate that BARcode can retrieve inspirations that are valuable to engineers and designers tackling real-world problems, as well as recover famous historical BID examples. We release data and code; we view BARcode as a step towards addressing the challenges that have historically hindered the practical application of BID to engineering innovation.
Selenite: Scaffolding Decision Making with Comprehensive Overviews Elicited from Large Language Models
Oct 03, 2023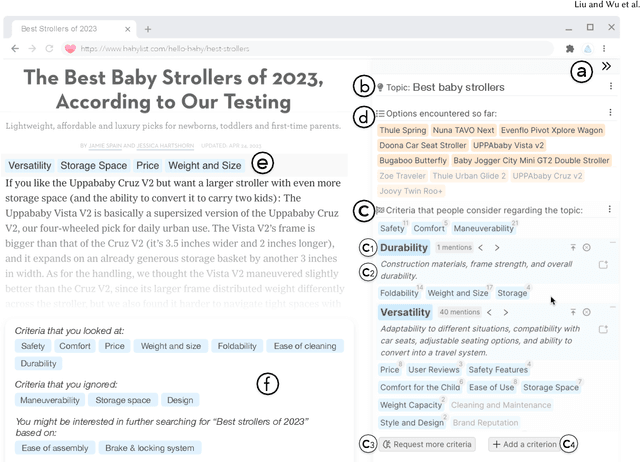



Decision-making in unfamiliar domains can be challenging, demanding considerable user effort to compare different options with respect to various criteria. Prior research and our formative study found that people would benefit from seeing an overview of the information space upfront, such as the criteria that others have previously found useful. However, existing sensemaking tools struggle with the "cold-start" problem -- it not only requires significant input from previous users to generate and share these overviews, but such overviews may also be biased and incomplete. In this work, we introduce a novel system, Selenite, which leverages LLMs as reasoning machines and knowledge retrievers to automatically produce a comprehensive overview of options and criteria to jumpstart users' sensemaking processes. Subsequently, Selenite also adapts as people use it, helping users find, read, and navigate unfamiliar information in a systematic yet personalized manner. Through three studies, we found that Selenite produced accurate and high-quality overviews reliably, significantly accelerated users' information processing, and effectively improved their overall comprehension and sensemaking experience.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Fuse: In-Situ Sensemaking Support in the Browser
Aug 31, 2022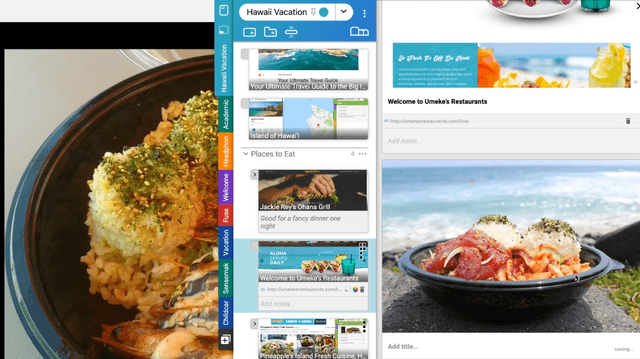

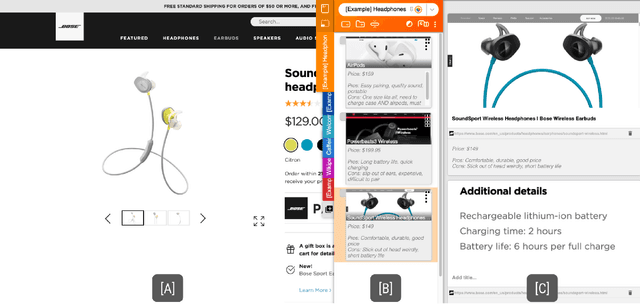
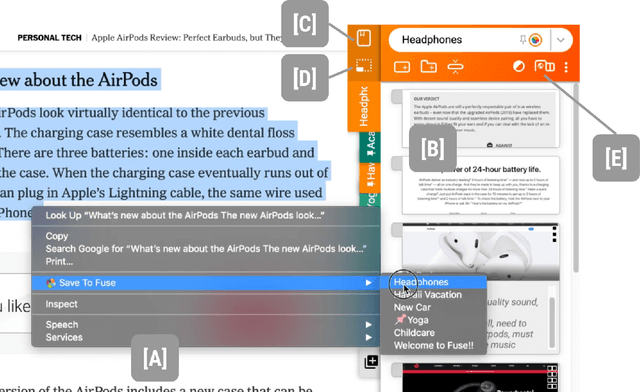
People spend a significant amount of time trying to make sense of the internet, collecting content from a variety of sources and organizing it to make decisions and achieve their goals. While humans are able to fluidly iterate on collecting and organizing information in their minds, existing tools and approaches introduce significant friction into the process. We introduce Fuse, a browser extension that externalizes users' working memory by combining low-cost collection with lightweight organization of content in a compact card-based sidebar that is always available. Fuse helps users simultaneously extract key web content and structure it in a lightweight and visual way. We discuss how these affordances help users externalize more of their mental model into the system (e.g., saving, annotating, and structuring items) and support fast reviewing and resumption of task contexts. Our 22-month public deployment and follow-up interviews provide longitudinal insights into the structuring behaviors of real-world users conducting information foraging tasks.
Augmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022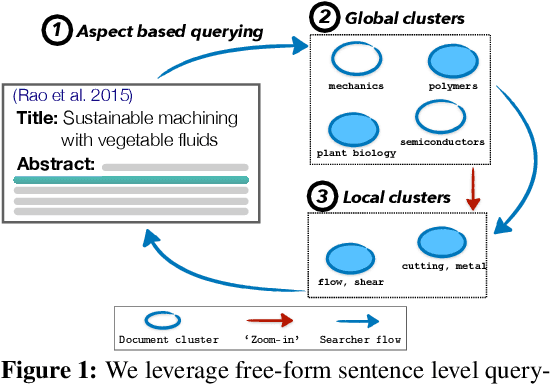
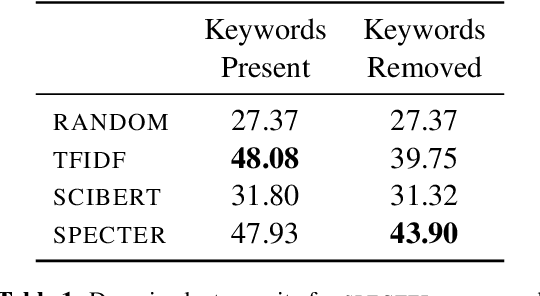
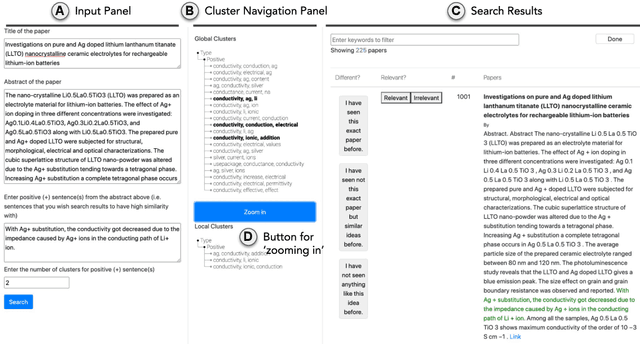

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.
From Who You Know to What You Read: Augmenting Scientific Recommendations with Implicit Social Networks
Apr 21, 2022



The ever-increasing pace of scientific publication necessitates methods for quickly identifying relevant papers. While neural recommenders trained on user interests can help, they still result in long, monotonous lists of suggested papers. To improve the discovery experience we introduce multiple new methods for \em augmenting recommendations with textual relevance messages that highlight knowledge-graph connections between recommended papers and a user's publication and interaction history. We explore associations mediated by author entities and those using citations alone. In a large-scale, real-world study, we show how our approach significantly increases engagement -- and future engagement when mediated by authors -- without introducing bias towards highly-cited authors. To expand message coverage for users with less publication or interaction history, we develop a novel method that highlights connections with proxy authors of interest to users and evaluate it in a controlled lab study. Finally, we synthesize design implications for future graph-based messages.
Scaling Creative Inspiration with Fine-Grained Functional Facets of Product Ideas
Feb 19, 2021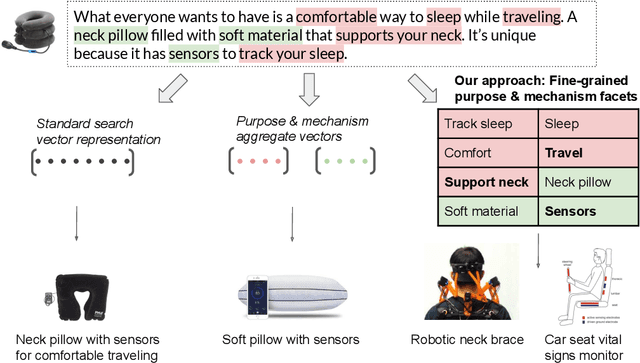
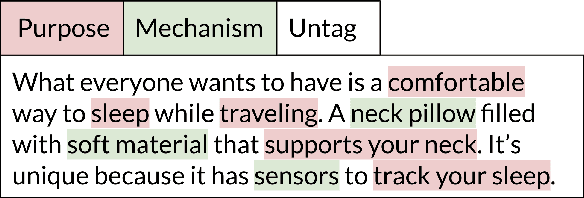

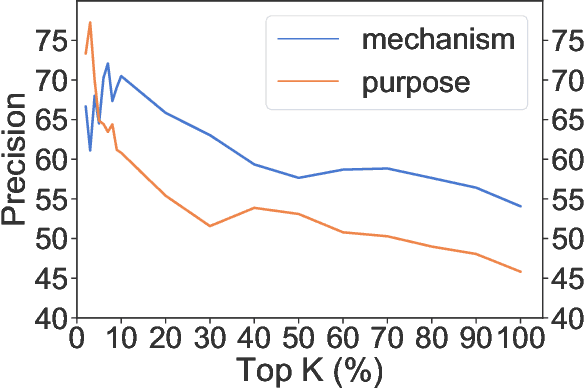
Web-scale repositories of products, patents and scientific papers offer an opportunity for creating automated systems that scour millions of ideas and assist users in discovering inspirations and solutions. Yet the common representation of ideas is in the form of raw textual descriptions, lacking important structure that is required for supporting creative innovation. Prior work has pointed to the importance of functional structure -- capturing the mechanisms and purposes of inventions -- for allowing users to discover structural connections across ideas and creatively adapt existing technologies. However, the use of functional representations was either coarse and limited in expressivity, or dependent on curated knowledge bases with poor coverage and significant manual effort from users. To help bridge this gap and unlock the potential of large-scale idea mining, we propose a novel computational representation that automatically breaks up products into fine-grained functional facets. We train a model to extract these facets from a challenging real-world corpus of invention descriptions, and represent each product as a set of facet embeddings. We design similarity metrics that support granular matching between functional facets across ideas, and use them to build a novel functional search capability that enables expressive queries for mechanisms and purposes. We construct a graph capturing hierarchical relations between purposes and mechanisms across an entire corpus of products, and use the graph to help problem-solvers explore the design space around a focal problem and view related problem perspectives. In empirical user studies, our approach leads to a significant boost in search accuracy and in the quality of creative inspirations, outperforming strong baselines and state-of-art representations of product texts by 50-60%.
Analogy Mining for Specific Design Needs
Dec 19, 2017
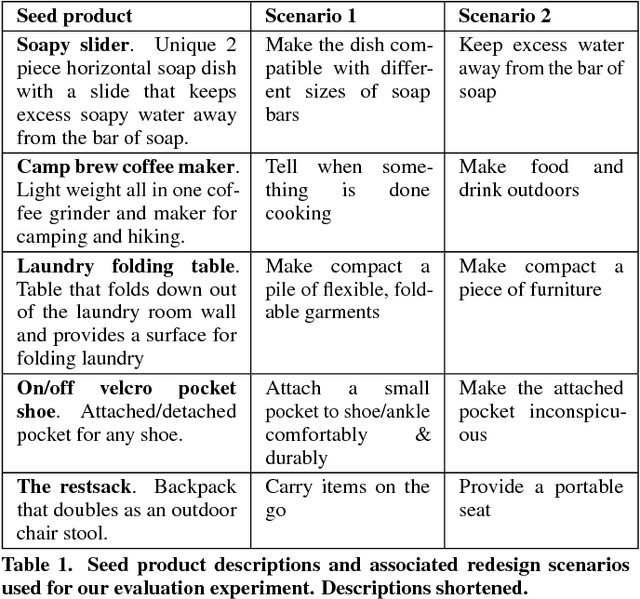


Finding analogical inspirations in distant domains is a powerful way of solving problems. However, as the number of inspirations that could be matched and the dimensions on which that matching could occur grow, it becomes challenging for designers to find inspirations relevant to their needs. Furthermore, designers are often interested in exploring specific aspects of a product-- for example, one designer might be interested in improving the brewing capability of an outdoor coffee maker, while another might wish to optimize for portability. In this paper we introduce a novel system for targeting analogical search for specific needs. Specifically, we contribute a novel analogical search engine for expressing and abstracting specific design needs that returns more distant yet relevant inspirations than alternate approaches.