 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Materials Knowledge in LLMs: From Latent Embeddings to Reliable Predictions
Mar 02, 2026Large language models are increasingly applied to materials science, yet fundamental questions remain about their reliability and knowledge encoding. Evaluating 25 LLMs across four materials science tasks -- over 200 base and fine-tuned configurations -- we find that output modality fundamentally determines model behavior. For symbolic tasks, fine-tuning converges to consistent, verifiable answers with reduced response entropy, while for numerical tasks, fine-tuning improves prediction accuracy but models remain inconsistent across repeated inference runs, limiting their reliability as quantitative predictors. For numerical regression, we find that better performance can be obtained by extracting embeddings directly from intermediate transformer layers than from model text output, revealing an ``LLM head bottleneck,'' though this effect is property- and dataset-dependent. Finally, we present a longitudinal study of GPT model performance in materials science, tracking four models over 18 months and observing 9--43\% performance variation that poses reproducibility challenges for scientific applications.
Masked Mineral Modeling: Continent-Scale Mineral Prospecting via Geospatial Infilling
Nov 12, 2025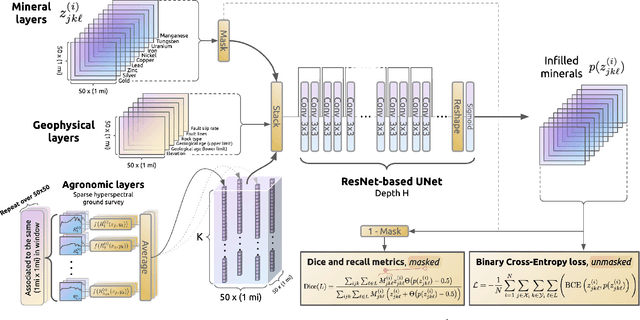
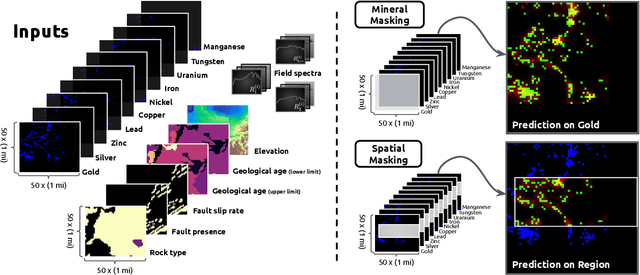


Minerals play a critical role in the advanced energy technologies necessary for decarbonization, but characterizing mineral deposits hidden underground remains costly and challenging. Inspired by recent progress in generative modeling, we develop a learning method which infers the locations of minerals by masking and infilling geospatial maps of resource availability. We demonstrate this technique using mineral data for the conterminous United States, and train performant models, with the best achieving Dice coefficients of $0.31 \pm 0.01$ and recalls of $0.22 \pm 0.02$ on test data at 1$\times$1 mi$^2$ spatial resolution. One major advantage of our approach is that it can easily incorporate auxiliary data sources for prediction which may be more abundant than mineral data. We highlight the capabilities of our model by adding input layers derived from geophysical sources, along with a nation-wide ground survey of soils originally intended for agronomic purposes. We find that employing such auxiliary features can improve inference performance, while also enabling model evaluation in regions with no recorded minerals.
Contrastive Learning of English Language and Crystal Graphs for Multimodal Representation of Materials Knowledge
Feb 23, 2025



Artificial intelligence (AI) is increasingly used for the inverse design of materials, such as crystals and molecules. Existing AI research on molecules has integrated chemical structures of molecules with textual knowledge to adapt to complex instructions. However, this approach has been unattainable for crystals due to data scarcity from the biased distribution of investigated crystals and the lack of semantic supervision in peer-reviewed literature. In this work, we introduce a contrastive language-crystals model (CLaC) pre-trained on a newly synthesized dataset of 126k crystal structure-text pairs. To demonstrate the advantage of using synthetic data to overcome data scarcity, we constructed a comparable dataset extracted from academic papers. We evaluate CLaC's generalization ability through various zero-shot cross-modal tasks and downstream applications. In experiments, CLaC achieves state-of-the-art zero-shot generalization performance in understanding crystal structures, surpassing latest large language models.
Retro-Rank-In: A Ranking-Based Approach for Inorganic Materials Synthesis Planning
Feb 07, 2025Retrosynthesis strategically plans the synthesis of a chemical target compound from simpler, readily available precursor compounds. This process is critical for synthesizing novel inorganic materials, yet traditional methods in inorganic chemistry continue to rely on trial-and-error experimentation. Emerging machine-learning approaches struggle to generalize to entirely new reactions due to their reliance on known precursors, as they frame retrosynthesis as a multi-label classification task. To address these limitations, we propose Retro-Rank-In, a novel framework that reformulates the retrosynthesis problem by embedding target and precursor materials into a shared latent space and learning a pairwise ranker on a bipartite graph of inorganic compounds. We evaluate Retro-Rank-In's generalizability on challenging retrosynthesis dataset splits designed to mitigate data duplicates and overlaps. For instance, for Cr2AlB2, it correctly predicts the verified precursor pair CrB + Al despite never seeing them in training, a capability absent in prior work. Extensive experiments show that Retro-Rank-In sets a new state-of-the-art, particularly in out-of-distribution generalization and candidate set ranking, offering a powerful tool for accelerating inorganic material synthesis.
Augmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022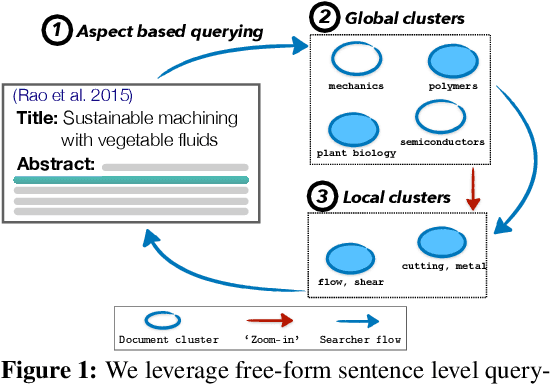
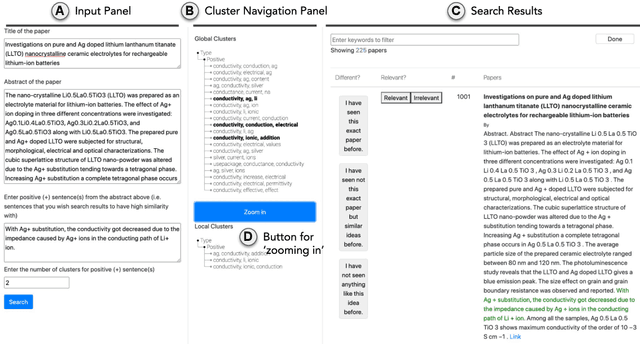

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.
The Materials Science Procedural Text Corpus: Annotating Materials Synthesis Procedures with Shallow Semantic Structures
May 16, 2019
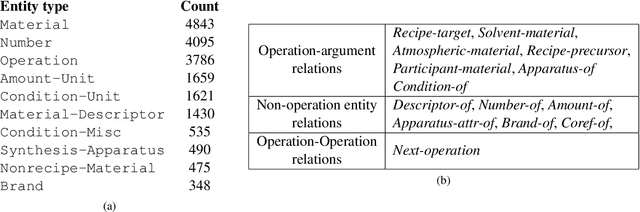
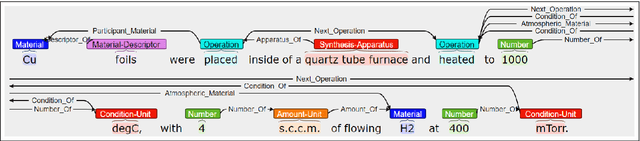

Materials science literature contains millions of materials synthesis procedures described in unstructured natural language text. Large-scale analysis of these synthesis procedures would facilitate deeper scientific understanding of materials synthesis and enable automated synthesis planning. Such analysis requires extracting structured representations of synthesis procedures from the raw text as a first step. To facilitate the training and evaluation of synthesis extraction models, we introduce a dataset of 230 synthesis procedures annotated by domain experts with labeled graphs that express the semantics of the synthesis sentences. The nodes in this graph are synthesis operations and their typed arguments, and labeled edges specify relations between the nodes. We describe this new resource in detail and highlight some specific challenges to annotating scientific text with shallow semantic structure. We make the corpus available to the community to promote further research and development of scientific information extraction systems.
Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks
Dec 31, 2018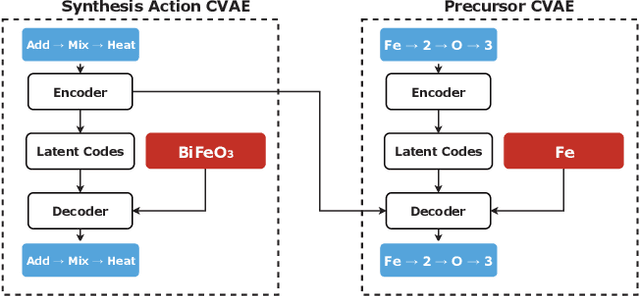
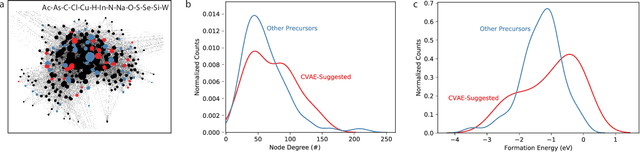
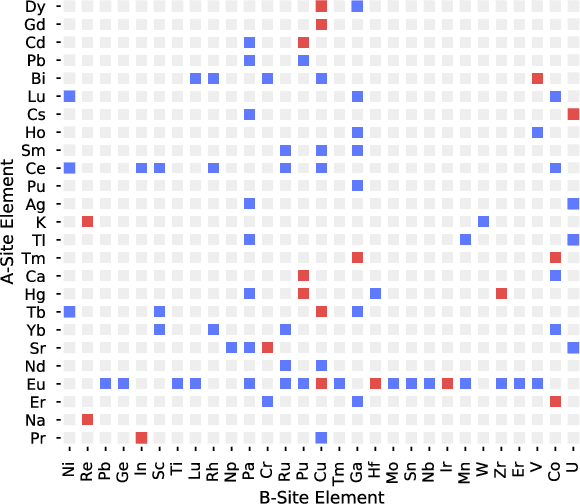

Leveraging new data sources is a key step in accelerating the pace of materials design and discovery. To complement the strides in synthesis planning driven by historical, experimental, and computed data, we present an automated method for connecting scientific literature to synthesis insights. Starting from natural language text, we apply word embeddings from language models, which are fed into a named entity recognition model, upon which a conditional variational autoencoder is trained to generate syntheses for arbitrary materials. We show the potential of this technique by predicting precursors for two perovskite materials, using only training data published over a decade prior to their first reported syntheses. We demonstrate that the model learns representations of materials corresponding to synthesis-related properties, and that the model's behavior complements existing thermodynamic knowledge. Finally, we apply the model to perform synthesizability screening for proposed novel perovskite compounds.
Automatically Extracting Action Graphs from Materials Science Synthesis Procedures
Nov 28, 2017
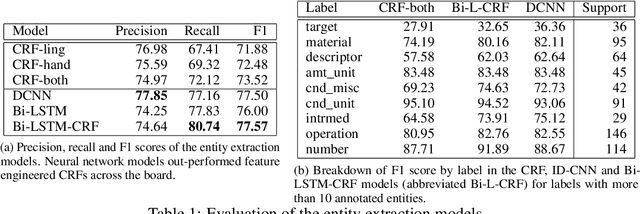
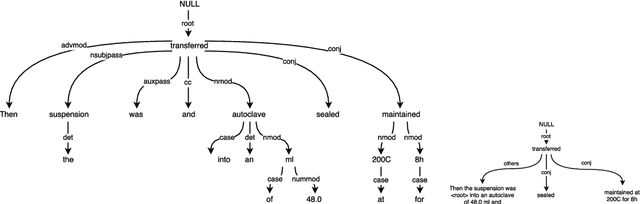
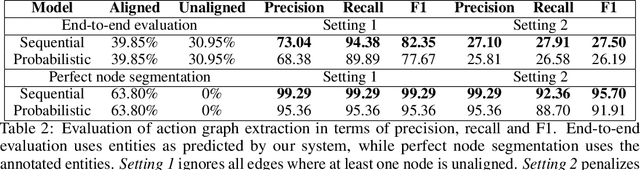
Computational synthesis planning approaches have achieved recent success in organic chemistry, where tabulated synthesis procedures are readily available for supervised learning. The syntheses of inorganic materials, however, exist primarily as natural language narratives contained within scientific journal articles. This synthesis information must first be extracted from the text in order to enable analogous synthesis planning methods for inorganic materials. In this work, we present a system for automatically extracting structured representations of synthesis procedures from the texts of materials science journal articles that describe explicit, experimental syntheses of inorganic compounds. We define the structured representation as a set of linked events made up of extracted scientific entities and evaluate two unsupervised approaches for extracting these structures on expert-annotated articles: a strong heuristic baseline and a generative model of procedural text. We also evaluate a variety of supervised models for extracting scientific entities. Our results provide insight into the nature of the data and directions for further work in this exciting new area of research.