 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Enable Data-Augmented Synthesis Planning for Inorganic Materials
Jun 14, 2025Inorganic synthesis planning currently relies primarily on heuristic approaches or machine-learning models trained on limited datasets, which constrains its generality. We demonstrate that language models, without task-specific fine-tuning, can recall synthesis conditions. Off-the-shelf models, such as GPT-4.1, Gemini 2.0 Flash and Llama 4 Maverick, achieve a Top-1 precursor-prediction accuracy of up to 53.8 % and a Top-5 performance of 66.1 % on a held-out set of 1,000 reactions. They also predict calcination and sintering temperatures with mean absolute errors below 126 {\deg}C, matching specialized regression methods. Ensembling these language models further enhances predictive accuracy and reduces inference cost per prediction by up to 70 %. We subsequently employ language models to generate 28,548 synthetic reaction recipes, which we combine with literature-mined examples to pretrain a transformer-based model, SyntMTE. After fine-tuning on the combined dataset, SyntMTE reduces mean-absolute error in sintering temperature prediction to 73 {\deg}C and in calcination temperature to 98 {\deg}C. This strategy improves models by up to 8.7 % compared with baselines trained exclusively on experimental data. Finally, in a case study on Li7La3Zr2O12 solid-state electrolytes, we demonstrate that SyntMTE reproduces the experimentally observed dopant-dependent sintering trends. Our hybrid workflow enables scalable, data-efficient inorganic synthesis planning.
Retro-Rank-In: A Ranking-Based Approach for Inorganic Materials Synthesis Planning
Feb 07, 2025Retrosynthesis strategically plans the synthesis of a chemical target compound from simpler, readily available precursor compounds. This process is critical for synthesizing novel inorganic materials, yet traditional methods in inorganic chemistry continue to rely on trial-and-error experimentation. Emerging machine-learning approaches struggle to generalize to entirely new reactions due to their reliance on known precursors, as they frame retrosynthesis as a multi-label classification task. To address these limitations, we propose Retro-Rank-In, a novel framework that reformulates the retrosynthesis problem by embedding target and precursor materials into a shared latent space and learning a pairwise ranker on a bipartite graph of inorganic compounds. We evaluate Retro-Rank-In's generalizability on challenging retrosynthesis dataset splits designed to mitigate data duplicates and overlaps. For instance, for Cr2AlB2, it correctly predicts the verified precursor pair CrB + Al despite never seeing them in training, a capability absent in prior work. Extensive experiments show that Retro-Rank-In sets a new state-of-the-art, particularly in out-of-distribution generalization and candidate set ranking, offering a powerful tool for accelerating inorganic material synthesis.
Regress, Don't Guess -- A Regression-like Loss on Number Tokens for Language Models
Nov 04, 2024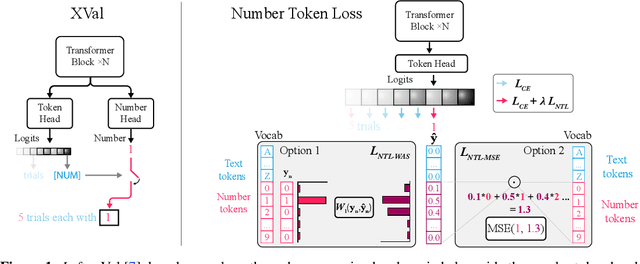
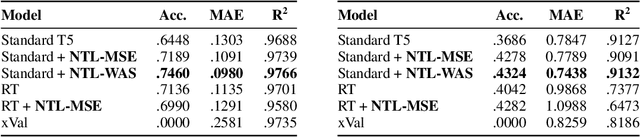
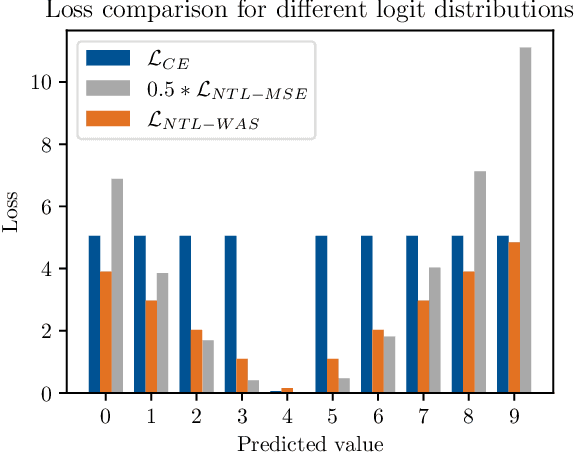
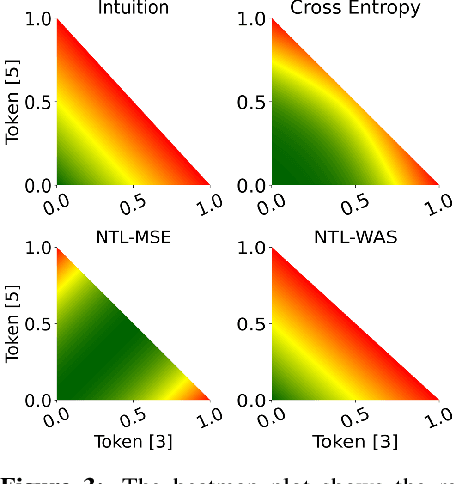
While language models have exceptional capabilities at text generation, they lack a natural inductive bias for emitting numbers and thus struggle in tasks involving reasoning over quantities, especially arithmetics. This has particular relevance in scientific datasets where combinations of text and numerical data are abundant. One fundamental limitation is the nature of the CE loss, which assumes a nominal (categorical) scale and thus cannot convey proximity between generated number tokens. As a remedy, we here present two versions of a number token loss. The first is based on an $L_p$ loss between the ground truth token value and the weighted sum of the predicted class probabilities. The second loss minimizes the Wasserstein-1 distance between the distribution of the predicted output probabilities and the ground truth distribution. These regression-like losses can easily be added to any language model and extend the CE objective during training. We compare the proposed schemes on a mathematics dataset against existing tokenization, encoding, and decoding schemes for improving number representation in language models. Our results reveal a significant improvement in numerical accuracy when equipping a standard T5 model with the proposed loss schemes.
Augmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022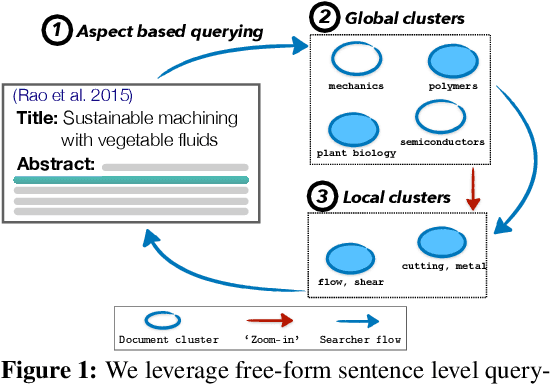
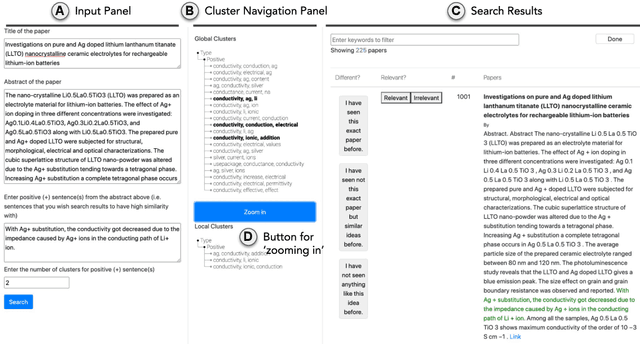

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.