 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes your model understand genes? A benchmark of gene properties for biological and text models
Dec 05, 2024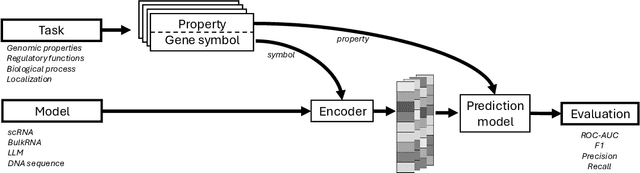
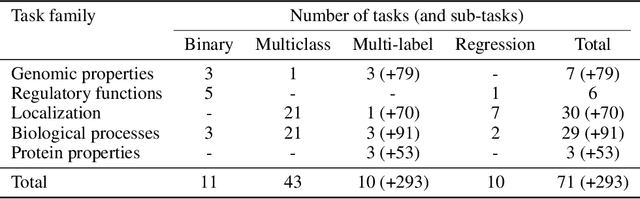
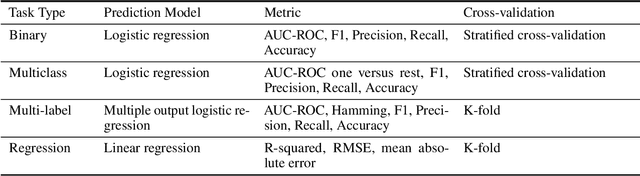

The application of deep learning methods, particularly foundation models, in biological research has surged in recent years. These models can be text-based or trained on underlying biological data, especially omics data of various types. However, comparing the performance of these models consistently has proven to be a challenge due to differences in training data and downstream tasks. To tackle this problem, we developed an architecture-agnostic benchmarking approach that, instead of evaluating the models directly, leverages entity representation vectors from each model and trains simple predictive models for each benchmarking task. This ensures that all types of models are evaluated using the same input and output types. Here we focus on gene properties collected from professionally curated bioinformatics databases. These gene properties are categorized into five major groups: genomic properties, regulatory functions, localization, biological processes, and protein properties. Overall, we define hundreds of tasks based on these databases, which include binary, multi-label, and multi-class classification tasks. We apply these benchmark tasks to evaluate expression-based models, large language models, protein language models, DNA-based models, and traditional baselines. Our findings suggest that text-based models and protein language models generally outperform expression-based models in genomic properties and regulatory functions tasks, whereas expression-based models demonstrate superior performance in localization tasks. These results should aid in the development of more informed artificial intelligence strategies for biological understanding and therapeutic discovery. To ensure the reproducibility and transparency of our findings, we have made the source code and benchmark data publicly accessible for further investigation and expansion at github.com/BiomedSciAI/gene-benchmark.
Regress, Don't Guess -- A Regression-like Loss on Number Tokens for Language Models
Nov 04, 2024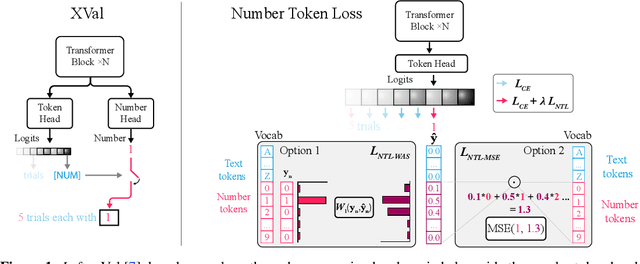
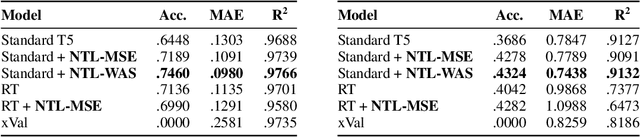
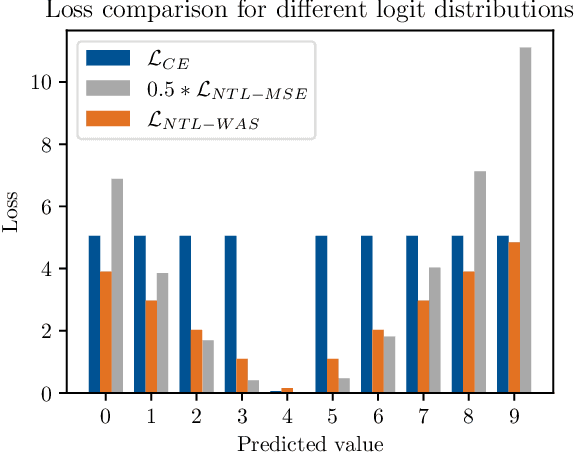
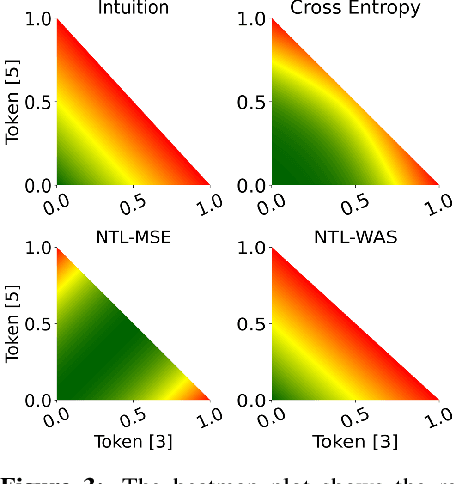
While language models have exceptional capabilities at text generation, they lack a natural inductive bias for emitting numbers and thus struggle in tasks involving reasoning over quantities, especially arithmetics. This has particular relevance in scientific datasets where combinations of text and numerical data are abundant. One fundamental limitation is the nature of the CE loss, which assumes a nominal (categorical) scale and thus cannot convey proximity between generated number tokens. As a remedy, we here present two versions of a number token loss. The first is based on an $L_p$ loss between the ground truth token value and the weighted sum of the predicted class probabilities. The second loss minimizes the Wasserstein-1 distance between the distribution of the predicted output probabilities and the ground truth distribution. These regression-like losses can easily be added to any language model and extend the CE objective during training. We compare the proposed schemes on a mathematics dataset against existing tokenization, encoding, and decoding schemes for improving number representation in language models. Our results reveal a significant improvement in numerical accuracy when equipping a standard T5 model with the proposed loss schemes.