 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving AI-generated music with user-guided training
Jun 05, 2025AI music generation has advanced rapidly, with models like diffusion and autoregressive algorithms enabling high-fidelity outputs. These tools can alter styles, mix instruments, or isolate them. Since sound can be visualized as spectrograms, image-generation algorithms can be applied to generate novel music. However, these algorithms are typically trained on fixed datasets, which makes it challenging for them to interpret and respond to user input accurately. This is especially problematic because music is highly subjective and requires a level of personalization that image generation does not provide. In this work, we propose a human-computation approach to gradually improve the performance of these algorithms based on user interactions. The human-computation element involves aggregating and selecting user ratings to use as the loss function for fine-tuning the model. We employ a genetic algorithm that incorporates user feedback to enhance the baseline performance of a model initially trained on a fixed dataset. The effectiveness of this approach is measured by the average increase in user ratings with each iteration. In the pilot test, the first iteration showed an average rating increase of 0.2 compared to the baseline. The second iteration further improved upon this, achieving an additional increase of 0.39 over the first iteration.
An Interpretable Representation Learning Approach for Diffusion Tensor Imaging
May 25, 2025


Diffusion Tensor Imaging (DTI) tractography offers detailed insights into the structural connectivity of the brain, but presents challenges in effective representation and interpretation in deep learning models. In this work, we propose a novel 2D representation of DTI tractography that encodes tract-level fractional anisotropy (FA) values into a 9x9 grayscale image. This representation is processed through a Beta-Total Correlation Variational Autoencoder with a Spatial Broadcast Decoder to learn a disentangled and interpretable latent embedding. We evaluate the quality of this embedding using supervised and unsupervised representation learning strategies, including auxiliary classification, triplet loss, and SimCLR-based contrastive learning. Compared to the 1D Group deep neural network (DNN) baselines, our approach improves the F1 score in a downstream sex classification task by 15.74% and shows a better disentanglement than the 3D representation.
Regress, Don't Guess -- A Regression-like Loss on Number Tokens for Language Models
Nov 04, 2024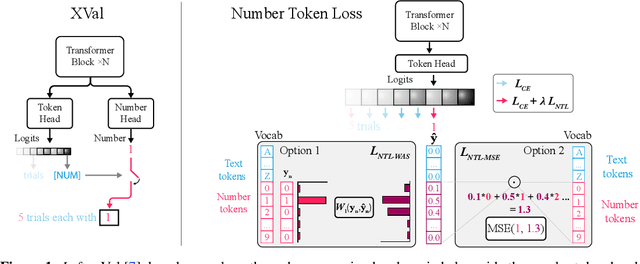
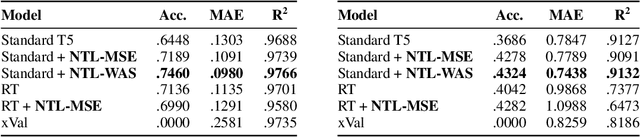
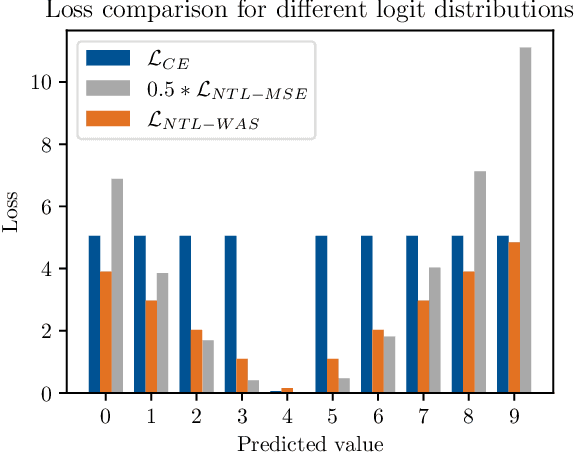
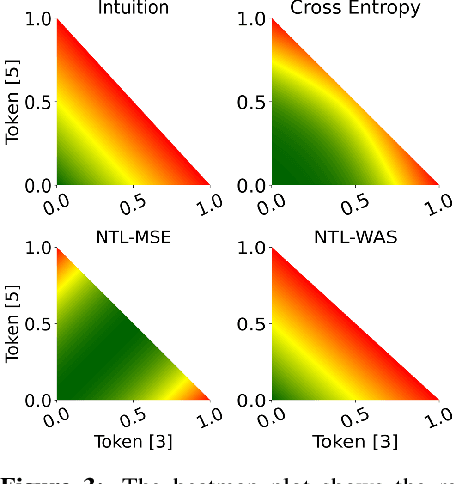
While language models have exceptional capabilities at text generation, they lack a natural inductive bias for emitting numbers and thus struggle in tasks involving reasoning over quantities, especially arithmetics. This has particular relevance in scientific datasets where combinations of text and numerical data are abundant. One fundamental limitation is the nature of the CE loss, which assumes a nominal (categorical) scale and thus cannot convey proximity between generated number tokens. As a remedy, we here present two versions of a number token loss. The first is based on an $L_p$ loss between the ground truth token value and the weighted sum of the predicted class probabilities. The second loss minimizes the Wasserstein-1 distance between the distribution of the predicted output probabilities and the ground truth distribution. These regression-like losses can easily be added to any language model and extend the CE objective during training. We compare the proposed schemes on a mathematics dataset against existing tokenization, encoding, and decoding schemes for improving number representation in language models. Our results reveal a significant improvement in numerical accuracy when equipping a standard T5 model with the proposed loss schemes.
Remembering Everything Makes You Vulnerable: A Limelight on Machine Unlearning for Personalized Healthcare Sector
Jul 05, 2024As the prevalence of data-driven technologies in healthcare continues to rise, concerns regarding data privacy and security become increasingly paramount. This thesis aims to address the vulnerability of personalized healthcare models, particularly in the context of ECG monitoring, to adversarial attacks that compromise patient privacy. We propose an approach termed "Machine Unlearning" to mitigate the impact of exposed data points on machine learning models, thereby enhancing model robustness against adversarial attacks while preserving individual privacy. Specifically, we investigate the efficacy of Machine Unlearning in the context of personalized ECG monitoring, utilizing a dataset of clinical ECG recordings. Our methodology involves training a deep neural classifier on ECG data and fine-tuning the model for individual patients. We demonstrate the susceptibility of fine-tuned models to adversarial attacks, such as the Fast Gradient Sign Method (FGSM), which can exploit additional data points in personalized models. To address this vulnerability, we propose a Machine Unlearning algorithm that selectively removes sensitive data points from fine-tuned models, effectively enhancing model resilience against adversarial manipulation. Experimental results demonstrate the effectiveness of our approach in mitigating the impact of adversarial attacks while maintaining the pre-trained model accuracy.