 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsers Mispredict Their Own Preferences for AI Writing Assistance
Jan 08, 2026Proactive AI writing assistants need to predict when users want drafting help, yet we lack empirical understanding of what drives preferences. Through a factorial vignette study with 50 participants making 750 pairwise comparisons, we find compositional effort dominates decisions ($ρ= 0.597$) while urgency shows no predictive power ($ρ\approx 0$). More critically, users exhibit a striking perception-behavior gap: they rank urgency first in self-reports despite it being the weakest behavioral driver, representing a complete preference inversion. This misalignment has measurable consequences. Systems designed from users' stated preferences achieve only 57.7\% accuracy, underperforming even naive baselines, while systems using behavioral patterns reach significantly higher 61.3\% ($p < 0.05$). These findings demonstrate that relying on user introspection for system design actively misleads optimization, with direct implications for proactive natural language generation (NLG) systems.
Inkspire: Supporting Design Exploration with Generative AI through Analogical Sketching
Jan 30, 2025



With recent advancements in the capabilities of Text-to-Image (T2I) AI models, product designers have begun experimenting with them in their work. However, T2I models struggle to interpret abstract language and the current user experience of T2I tools can induce design fixation rather than a more iterative, exploratory process. To address these challenges, we developed Inkspire, a sketch-driven tool that supports designers in prototyping product design concepts with analogical inspirations and a complete sketch-to-design-to-sketch feedback loop. To inform the design of Inkspire, we conducted an exchange session with designers and distilled design goals for improving T2I interactions. In a within-subjects study comparing Inkspire to ControlNet, we found that Inkspire supported designers with more inspiration and exploration of design ideas, and improved aspects of the co-creative process by allowing designers to effectively grasp the current state of the AI to guide it towards novel design intentions.
PaperWeaver: Enriching Topical Paper Alerts by Contextualizing Recommended Papers with User-collected Papers
Mar 05, 2024With the rapid growth of scholarly archives, researchers subscribe to "paper alert" systems that periodically provide them with recommendations of recently published papers that are similar to previously collected papers. However, researchers sometimes struggle to make sense of nuanced connections between recommended papers and their own research context, as existing systems only present paper titles and abstracts. To help researchers spot these connections, we present PaperWeaver, an enriched paper alerts system that provides contextualized text descriptions of recommended papers based on user-collected papers. PaperWeaver employs a computational method based on Large Language Models (LLMs) to infer users' research interests from their collected papers, extract context-specific aspects of papers, and compare recommended and collected papers on these aspects. Our user study (N=15) showed that participants using PaperWeaver were able to better understand the relevance of recommended papers and triage them more confidently when compared to a baseline that presented the related work sections from recommended papers.
Augmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022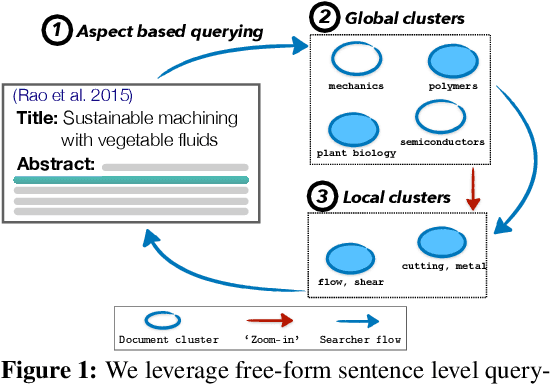
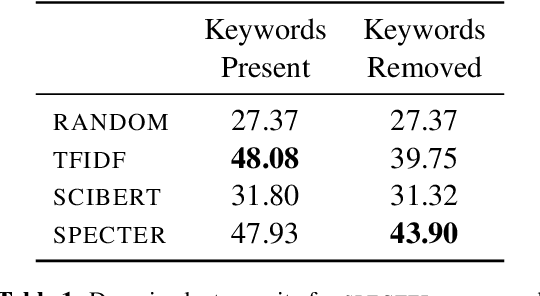
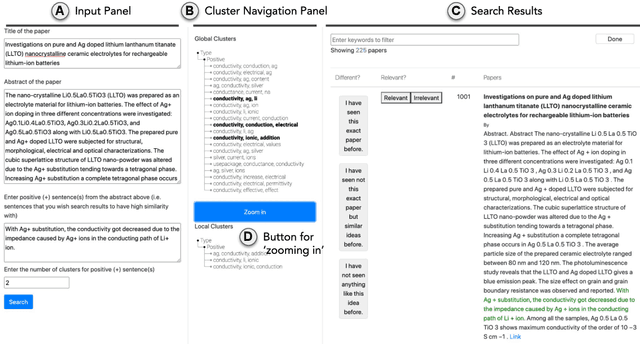

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.
From Who You Know to What You Read: Augmenting Scientific Recommendations with Implicit Social Networks
Apr 21, 2022



The ever-increasing pace of scientific publication necessitates methods for quickly identifying relevant papers. While neural recommenders trained on user interests can help, they still result in long, monotonous lists of suggested papers. To improve the discovery experience we introduce multiple new methods for \em augmenting recommendations with textual relevance messages that highlight knowledge-graph connections between recommended papers and a user's publication and interaction history. We explore associations mediated by author entities and those using citations alone. In a large-scale, real-world study, we show how our approach significantly increases engagement -- and future engagement when mediated by authors -- without introducing bias towards highly-cited authors. To expand message coverage for users with less publication or interaction history, we develop a novel method that highlights connections with proxy authors of interest to users and evaluate it in a controlled lab study. Finally, we synthesize design implications for future graph-based messages.