 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInkspire: Supporting Design Exploration with Generative AI through Analogical Sketching
Jan 30, 2025



With recent advancements in the capabilities of Text-to-Image (T2I) AI models, product designers have begun experimenting with them in their work. However, T2I models struggle to interpret abstract language and the current user experience of T2I tools can induce design fixation rather than a more iterative, exploratory process. To address these challenges, we developed Inkspire, a sketch-driven tool that supports designers in prototyping product design concepts with analogical inspirations and a complete sketch-to-design-to-sketch feedback loop. To inform the design of Inkspire, we conducted an exchange session with designers and distilled design goals for improving T2I interactions. In a within-subjects study comparing Inkspire to ControlNet, we found that Inkspire supported designers with more inspiration and exploration of design ideas, and improved aspects of the co-creative process by allowing designers to effectively grasp the current state of the AI to guide it towards novel design intentions.
What Do I Hear? Generating Sounds for Visuals with ChatGPT
Nov 09, 2023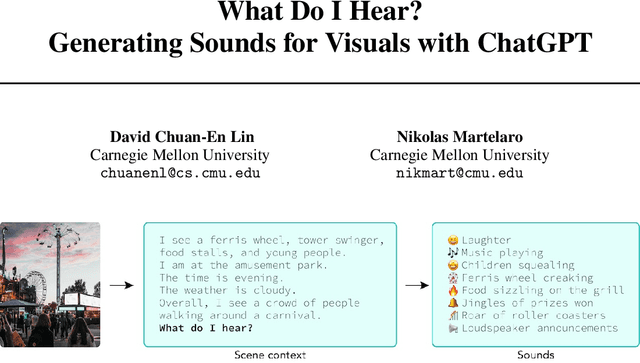
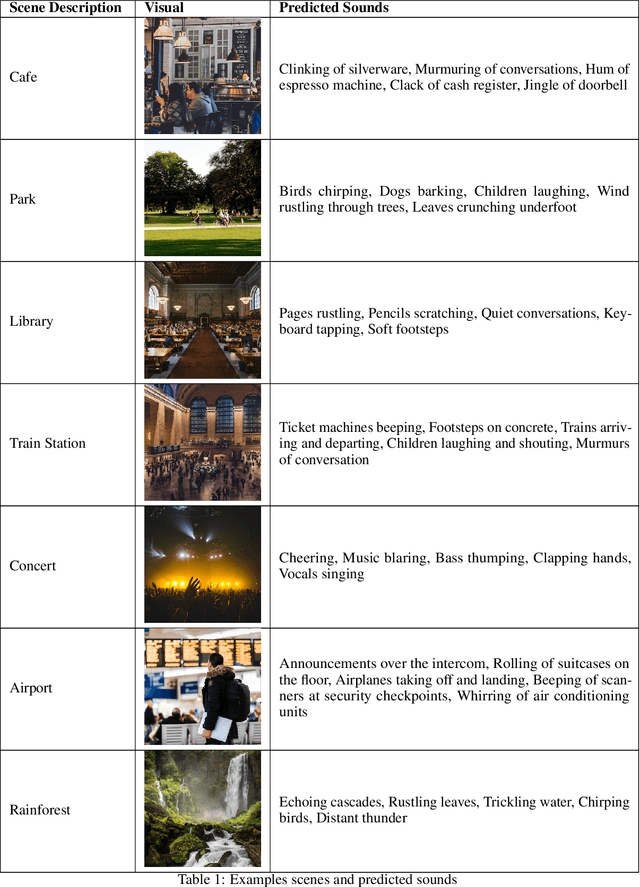
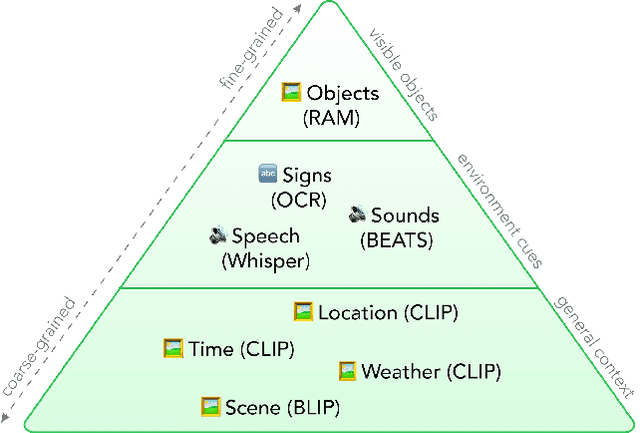

This short paper introduces a workflow for generating realistic soundscapes for visual media. In contrast to prior work, which primarily focus on matching sounds for on-screen visuals, our approach extends to suggesting sounds that may not be immediately visible but are essential to crafting a convincing and immersive auditory environment. Our key insight is leveraging the reasoning capabilities of language models, such as ChatGPT. In this paper, we describe our workflow, which includes creating a scene context, brainstorming sounds, and generating the sounds.
Jigsaw: Supporting Designers in Prototyping Multimodal Applications by Assembling AI Foundation Models
Oct 12, 2023



Recent advancements in AI foundation models have made it possible for them to be utilized off-the-shelf for creative tasks, including ideating design concepts or generating visual prototypes. However, integrating these models into the creative process can be challenging as they often exist as standalone applications tailored to specific tasks. To address this challenge, we introduce Jigsaw, a prototype system that employs puzzle pieces as metaphors to represent foundation models. Jigsaw allows designers to combine different foundation model capabilities across various modalities by assembling compatible puzzle pieces. To inform the design of Jigsaw, we interviewed ten designers and distilled design goals. In a user study, we showed that Jigsaw enhanced designers' understanding of available foundation model capabilities, provided guidance on combining capabilities across different modalities and tasks, and served as a canvas to support design exploration, prototyping, and documentation.
Videogenic: Video Highlights via Photogenic Moments
Nov 22, 2022This paper investigates the challenge of extracting highlight moments from videos. To perform this task, a system needs to understand what constitutes a highlight for arbitrary video domains while at the same time being able to scale across different domains. Our key insight is that photographs taken by photographers tend to capture the most remarkable or photogenic moments of an activity. Drawing on this insight, we present Videogenic, a system capable of creating domain-specific highlight videos for a wide range of domains. In a human evaluation study (N=50), we show that a high-quality photograph collection combined with CLIP-based retrieval (which uses a neural network with semantic knowledge of images) can serve as an excellent prior for finding video highlights. In a within-subjects expert study (N=12), we demonstrate the usefulness of Videogenic in helping video editors create highlight videos with lighter workload, shorter task completion time, and better usability.
VideoMap: Video Editing in Latent Space
Nov 22, 2022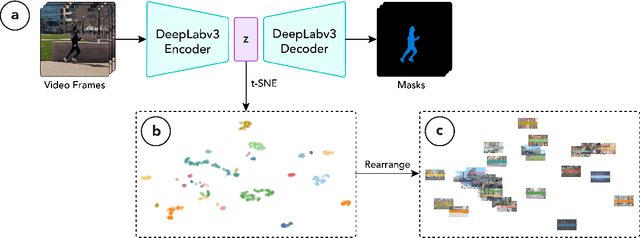


Video has become a dominant form of media. However, video editing interfaces have remained largely unchanged over the past two decades. Such interfaces typically consist of a grid-like asset management panel and a linear editing timeline. When working with a large number of video clips, it can be difficult to sort through them all and identify patterns within (e.g. opportunities for smooth transitions and storytelling). In this work, we imagine a new paradigm for video editing by mapping videos into a 2D latent space and building a proof-of-concept interface.
Soundify: Matching Sound Effects to Video
Dec 17, 2021
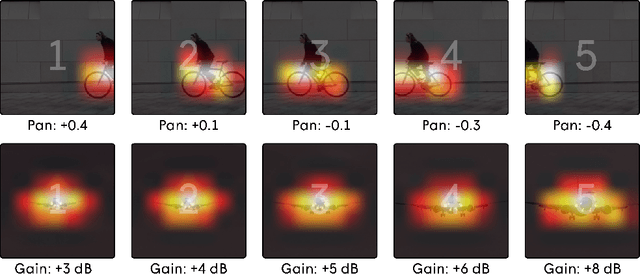
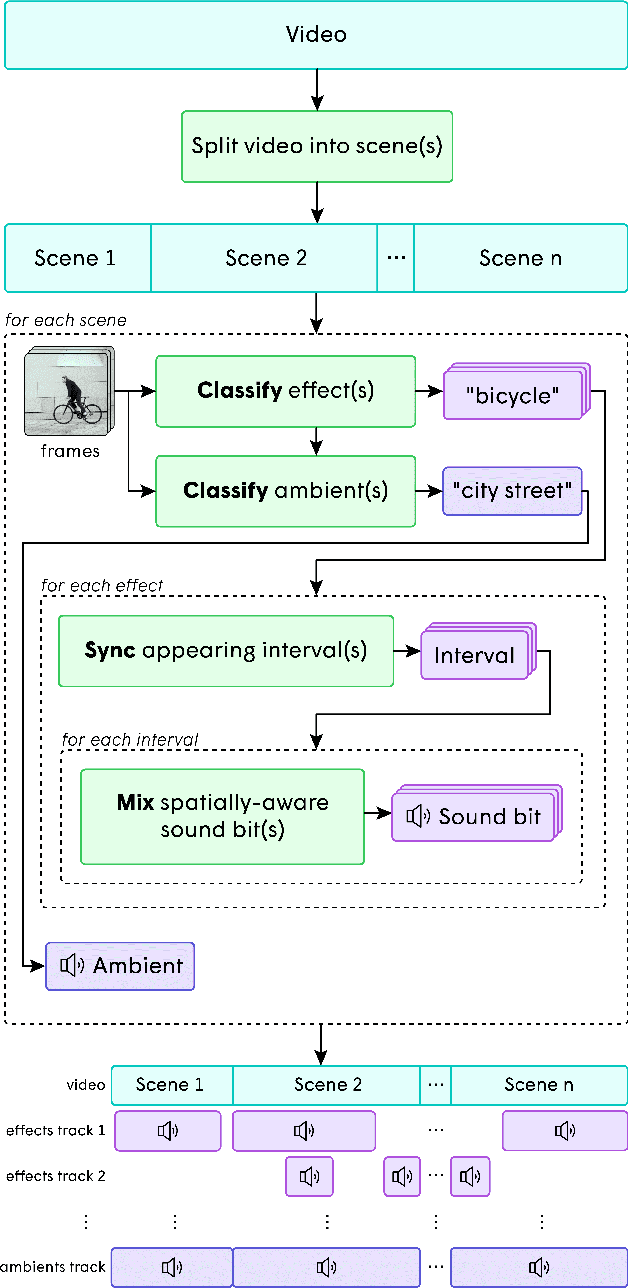
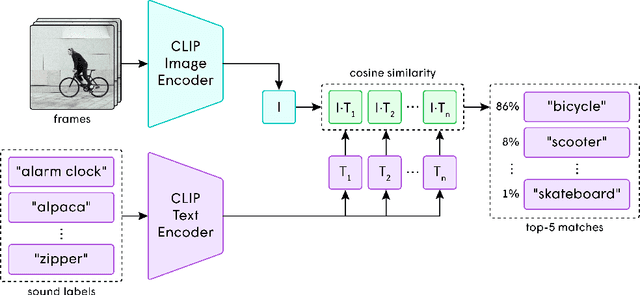
In the art of video editing, sound is really half the story. A skilled video editor overlays sounds, such as effects and ambients, over footage to add character to an object or immerse the viewer within a space. However, through formative interviews with professional video editors, we found that this process can be extremely tedious and time-consuming. We introduce Soundify, a system that matches sound effects to video. By leveraging labeled, studio-quality sound effects libraries and extending CLIP, a neural network with impressive zero-shot image classification capabilities, into a "zero-shot detector", we are able to produce high-quality results without resource-intensive correspondence learning or audio generation. We encourage you to have a look at, or better yet, have a listen to the results at https://chuanenlin.com/soundify.
Learning Personal Style from Few Examples
Jun 17, 2021
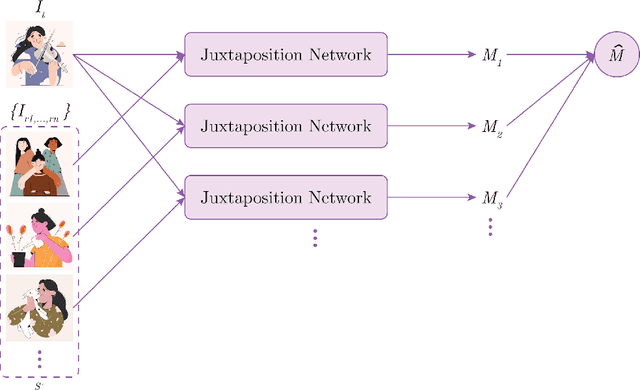


A key task in design work is grasping the client's implicit tastes. Designers often do this based on a set of examples from the client. However, recognizing a common pattern among many intertwining variables such as color, texture, and layout and synthesizing them into a composite preference can be challenging. In this paper, we leverage the pattern recognition capability of computational models to aid in this task. We offer a set of principles for computationally learning personal style. The principles are manifested in PseudoClient, a deep learning framework that learns a computational model for personal graphic design style from only a handful of examples. In several experiments, we found that PseudoClient achieves a 79.40% accuracy with only five positive and negative examples, outperforming several alternative methods. Finally, we discuss how PseudoClient can be utilized as a building block to support the development of future design applications.