Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do I Hear? Generating Sounds for Visuals with ChatGPT
Paper and Code
Nov 09, 2023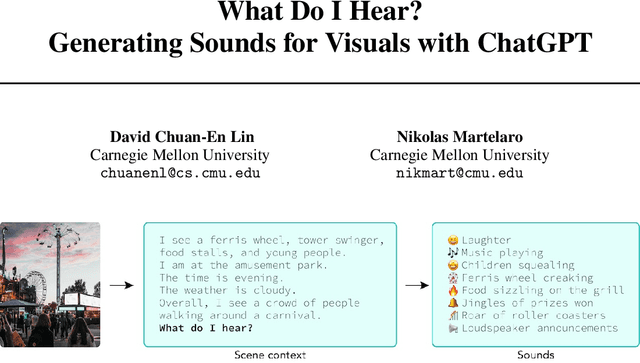
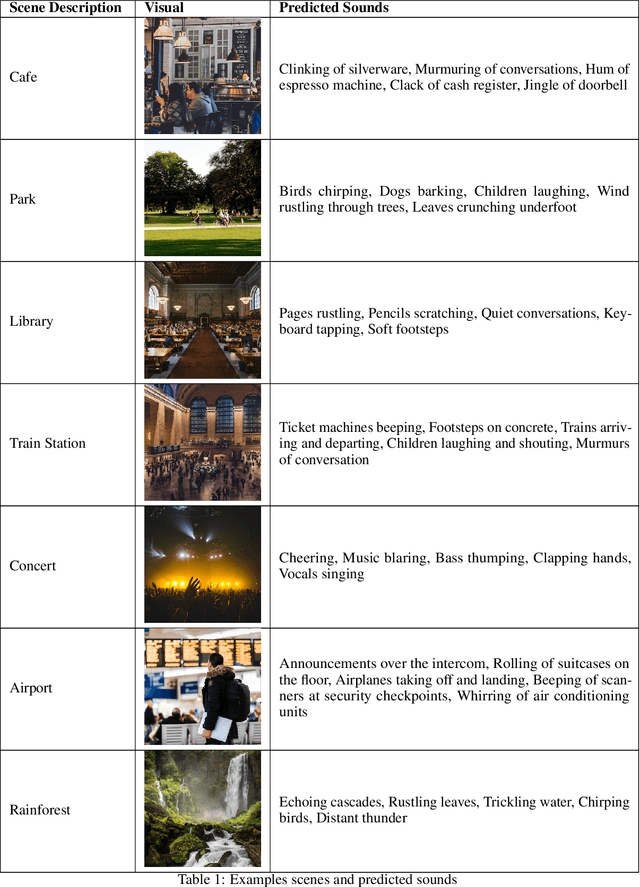
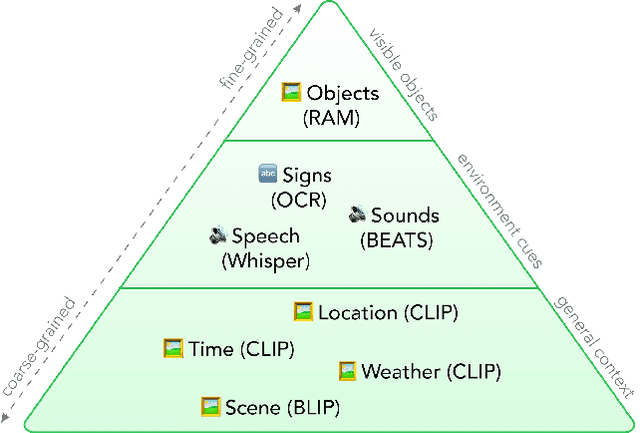

This short paper introduces a workflow for generating realistic soundscapes for visual media. In contrast to prior work, which primarily focus on matching sounds for on-screen visuals, our approach extends to suggesting sounds that may not be immediately visible but are essential to crafting a convincing and immersive auditory environment. Our key insight is leveraging the reasoning capabilities of language models, such as ChatGPT. In this paper, we describe our workflow, which includes creating a scene context, brainstorming sounds, and generating the sounds.
* Demo: http://soundify.cc
View paper on