 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating stereotypical biases in text to image generative systems
Oct 10, 2023
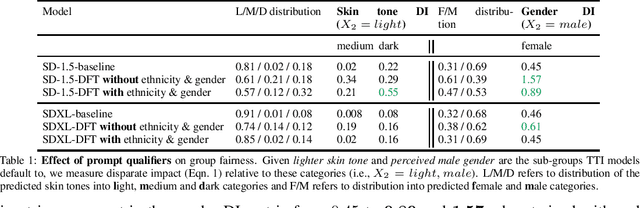


State-of-the-art generative text-to-image models are known to exhibit social biases and over-represent certain groups like people of perceived lighter skin tones and men in their outcomes. In this work, we propose a method to mitigate such biases and ensure that the outcomes are fair across different groups of people. We do this by finetuning text-to-image models on synthetic data that varies in perceived skin tones and genders constructed from diverse text prompts. These text prompts are constructed from multiplicative combinations of ethnicities, genders, professions, age groups, and so on, resulting in diverse synthetic data. Our diversity finetuned (DFT) model improves the group fairness metric by 150% for perceived skin tone and 97.7% for perceived gender. Compared to baselines, DFT models generate more people with perceived darker skin tone and more women. To foster open research, we will release all text prompts and code to generate training images.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.
Soundify: Matching Sound Effects to Video
Dec 17, 2021
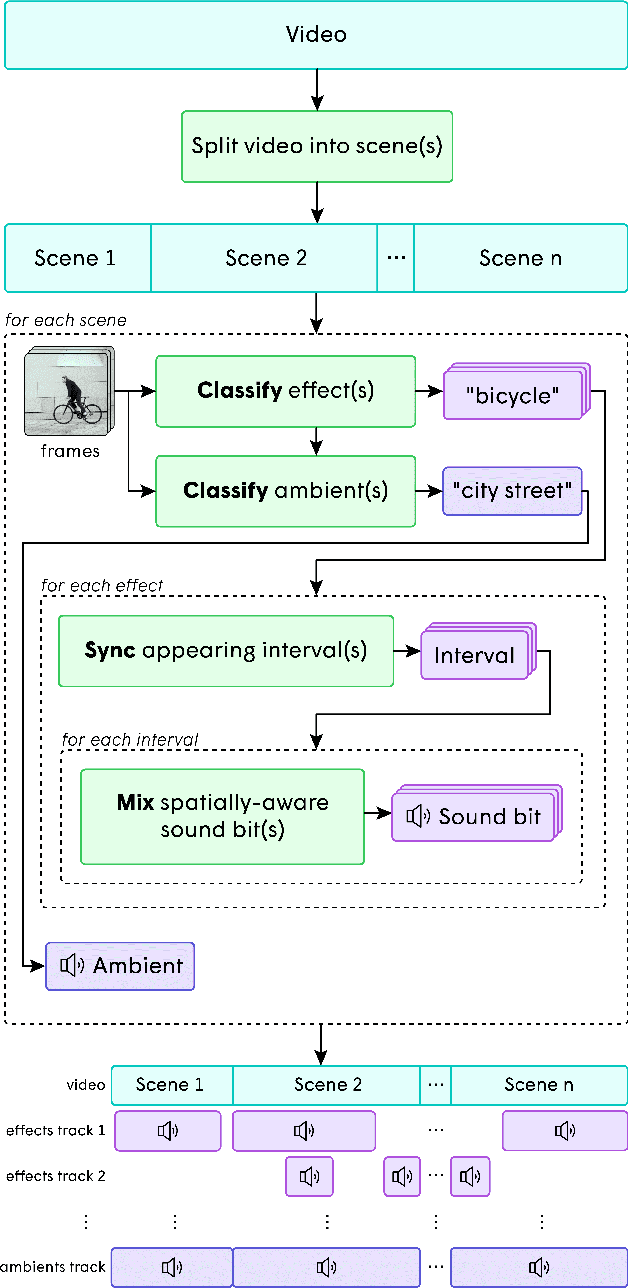
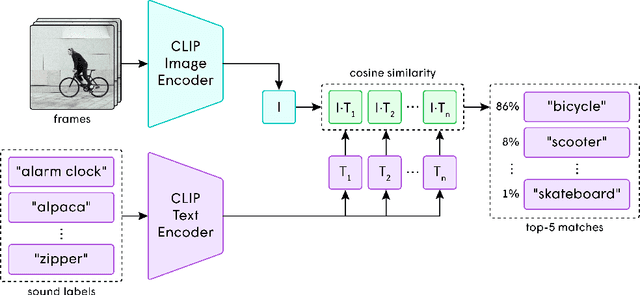
In the art of video editing, sound is really half the story. A skilled video editor overlays sounds, such as effects and ambients, over footage to add character to an object or immerse the viewer within a space. However, through formative interviews with professional video editors, we found that this process can be extremely tedious and time-consuming. We introduce Soundify, a system that matches sound effects to video. By leveraging labeled, studio-quality sound effects libraries and extending CLIP, a neural network with impressive zero-shot image classification capabilities, into a "zero-shot detector", we are able to produce high-quality results without resource-intensive correspondence learning or audio generation. We encourage you to have a look at, or better yet, have a listen to the results at https://chuanenlin.com/soundify.