 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating stereotypical biases in text to image generative systems
Paper and Code
Oct 10, 2023
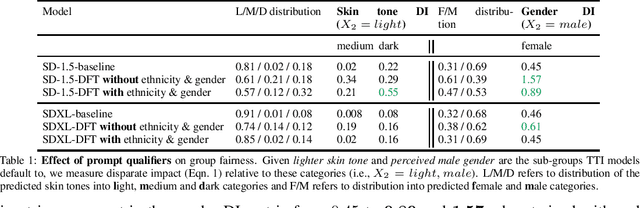


State-of-the-art generative text-to-image models are known to exhibit social biases and over-represent certain groups like people of perceived lighter skin tones and men in their outcomes. In this work, we propose a method to mitigate such biases and ensure that the outcomes are fair across different groups of people. We do this by finetuning text-to-image models on synthetic data that varies in perceived skin tones and genders constructed from diverse text prompts. These text prompts are constructed from multiplicative combinations of ethnicities, genders, professions, age groups, and so on, resulting in diverse synthetic data. Our diversity finetuned (DFT) model improves the group fairness metric by 150% for perceived skin tone and 97.7% for perceived gender. Compared to baselines, DFT models generate more people with perceived darker skin tone and more women. To foster open research, we will release all text prompts and code to generate training images.