 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating stereotypical biases in text to image generative systems
Oct 10, 2023
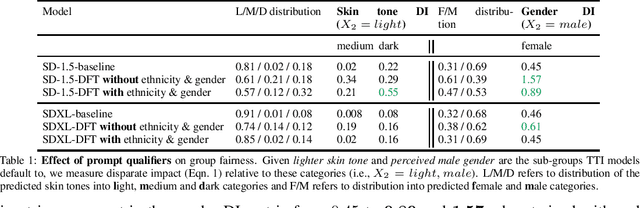


State-of-the-art generative text-to-image models are known to exhibit social biases and over-represent certain groups like people of perceived lighter skin tones and men in their outcomes. In this work, we propose a method to mitigate such biases and ensure that the outcomes are fair across different groups of people. We do this by finetuning text-to-image models on synthetic data that varies in perceived skin tones and genders constructed from diverse text prompts. These text prompts are constructed from multiplicative combinations of ethnicities, genders, professions, age groups, and so on, resulting in diverse synthetic data. Our diversity finetuned (DFT) model improves the group fairness metric by 150% for perceived skin tone and 97.7% for perceived gender. Compared to baselines, DFT models generate more people with perceived darker skin tone and more women. To foster open research, we will release all text prompts and code to generate training images.
Cabrita: closing the gap for foreign languages
Aug 23, 2023



The strategy of training the model from scratch in a specific language or domain serves two essential purposes: i) enhancing performance in the particular linguistic or domain context, and ii) ensuring effective tokenization. The main limitation inherent to this approach lies in the associated cost, which can reach six to seven-digit dollar values, depending on the model size and the number of parameters involved. The main solution to overcome the cost challenge is to rely on available pre-trained models, which, despite recent advancements such as the LLaMA and LLaMA-2 models, still demonstrate inefficiency for certain specific domain problems or prove ineffective in scenarios involving conversational memory resources, given the large number of tokens required to represent text. To overcome this issue, we present a methodology named Cabrita, which, as our research demonstrates, successfully addresses the performance and efficient tokenization problem, all at an affordable cost. We believe that this methodology can be applied to any transformer-like architecture model. To validate the study, we conducted continuous pre-training exclusively using Portuguese text on a 3-billion-parameter model known as OpenLLaMA, resulting in a model named openCabrita 3B. The openCabrita 3B also features a new tokenizer that results in a significant reduction in the number of tokens required to represent the text. In our assessment, for few-shot learning tasks, we achieved similar results with this 3B model compared to a traditional continuous pre-training approach as well as to 7B models English pre-trained models.