 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chronicles of RAG: The Retriever, the Chunk and the Generator
Jan 15, 2024



Retrieval Augmented Generation (RAG) has become one of the most popular paradigms for enabling LLMs to access external data, and also as a mechanism for grounding to mitigate against hallucinations. When implementing RAG you can face several challenges like effective integration of retrieval models, efficient representation learning, data diversity, computational efficiency optimization, evaluation, and quality of text generation. Given all these challenges, every day a new technique to improve RAG appears, making it unfeasible to experiment with all combinations for your problem. In this context, this paper presents good practices to implement, optimize, and evaluate RAG for the Brazilian Portuguese language, focusing on the establishment of a simple pipeline for inference and experiments. We explored a diverse set of methods to answer questions about the first Harry Potter book. To generate the answers we used the OpenAI's gpt-4, gpt-4-1106-preview, gpt-3.5-turbo-1106, and Google's Gemini Pro. Focusing on the quality of the retriever, our approach achieved an improvement of MRR@10 by 35.4% compared to the baseline. When optimizing the input size in the application, we observed that it is possible to further enhance it by 2.4%. Finally, we present the complete architecture of the RAG with our recommendations. As result, we moved from a baseline of 57.88% to a maximum relative score of 98.61%.
Portuguese FAQ for Financial Services
Nov 19, 2023
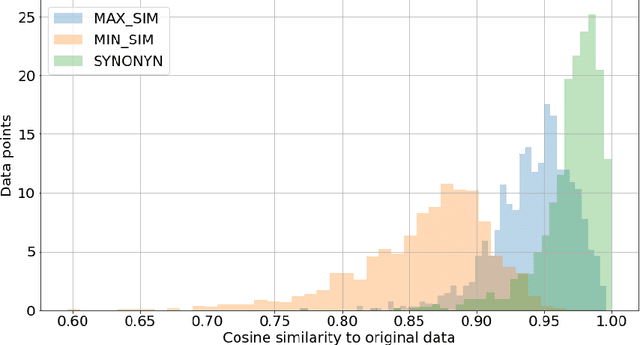


Scarcity of domain-specific data in the Portuguese financial domain has disfavored the development of Natural Language Processing (NLP) applications. To address this limitation, the present study advocates for the utilization of synthetic data generated through data augmentation techniques. The investigation focuses on the augmentation of a dataset sourced from the Central Bank of Brazil FAQ, employing techniques that vary in semantic similarity. Supervised and unsupervised tasks are conducted to evaluate the impact of augmented data on both low and high semantic similarity scenarios. Additionally, the resultant dataset will be publicly disseminated on the Hugging Face Datasets platform, thereby enhancing accessibility and fostering broader engagement within the NLP research community.
Cabrita: closing the gap for foreign languages
Aug 23, 2023



The strategy of training the model from scratch in a specific language or domain serves two essential purposes: i) enhancing performance in the particular linguistic or domain context, and ii) ensuring effective tokenization. The main limitation inherent to this approach lies in the associated cost, which can reach six to seven-digit dollar values, depending on the model size and the number of parameters involved. The main solution to overcome the cost challenge is to rely on available pre-trained models, which, despite recent advancements such as the LLaMA and LLaMA-2 models, still demonstrate inefficiency for certain specific domain problems or prove ineffective in scenarios involving conversational memory resources, given the large number of tokens required to represent text. To overcome this issue, we present a methodology named Cabrita, which, as our research demonstrates, successfully addresses the performance and efficient tokenization problem, all at an affordable cost. We believe that this methodology can be applied to any transformer-like architecture model. To validate the study, we conducted continuous pre-training exclusively using Portuguese text on a 3-billion-parameter model known as OpenLLaMA, resulting in a model named openCabrita 3B. The openCabrita 3B also features a new tokenizer that results in a significant reduction in the number of tokens required to represent the text. In our assessment, for few-shot learning tasks, we achieved similar results with this 3B model compared to a traditional continuous pre-training approach as well as to 7B models English pre-trained models.
BERTaú: Itaú BERT for digital customer service
Jan 28, 2021

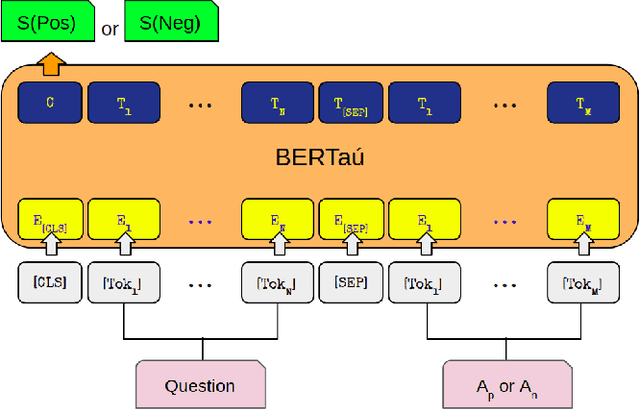
In the last few years, three major topics received increased interest: deep learning, NLP and conversational agents. Bringing these three topics together to create an amazing digital customer experience and indeed deploy in production and solve real-world problems is something innovative and disruptive. We introduce a new Portuguese financial domain language representation model called BERTa\'u. BERTa\'u is an uncased BERT-base trained from scratch with data from the Ita\'u virtual assistant chatbot solution. Our novel contribution is that BERTa\'u pretrained language model requires less data, reached state-of-the-art performance in three NLP tasks, and generates a smaller and lighter model that makes the deployment feasible. We developed three tasks to validate our model: information retrieval with Frequently Asked Questions (FAQ) from Ita\'u bank, sentiment analysis from our virtual assistant data, and a NER solution. All proposed tasks are real-world solutions in production on our environment and the usage of a specialist model proved to be effective when compared to Google BERT multilingual and the DPRQuestionEncoder from Facebook, available at Hugging Face. The BERTa\'u improves the performance in 22% of FAQ Retrieval MRR metric, 2.1% in Sentiment Analysis F1 score, 4.4% in NER F1 score and can also represent the same sequence in up to 66% fewer tokens when compared to "shelf models".
Normalizador Neural de Datas e Endereços
Jul 09, 2020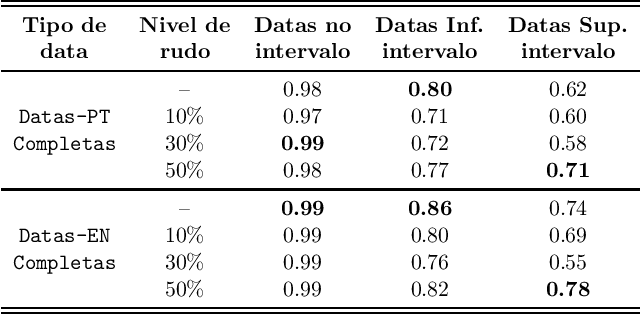



Documents of any kind present a wide variety of date and address formats, in some cases dates can be written entirely in full or even have different types of separators. The pattern disorder in addresses is even greater due to the greater possibility of interchanging between streets, neighborhoods, cities and states. In the context of natural language processing, problems of this nature are handled by rigid tools such as ReGex or DateParser, which are efficient as long as the expected input is pre-configured. When these algorithms are given an unexpected format, errors and unwanted outputs happen. To circumvent this challenge, we present a solution with deep neural networks state of art T5 that treats non-preconfigured formats of dates and addresses with accuracy above 90% in some cases. With this model, our proposal brings generalization to the task of normalizing dates and addresses. We also deal with this problem with noisy data that simulates possible errors in the text.
Electricity Theft Detection with self-attention
Feb 14, 2020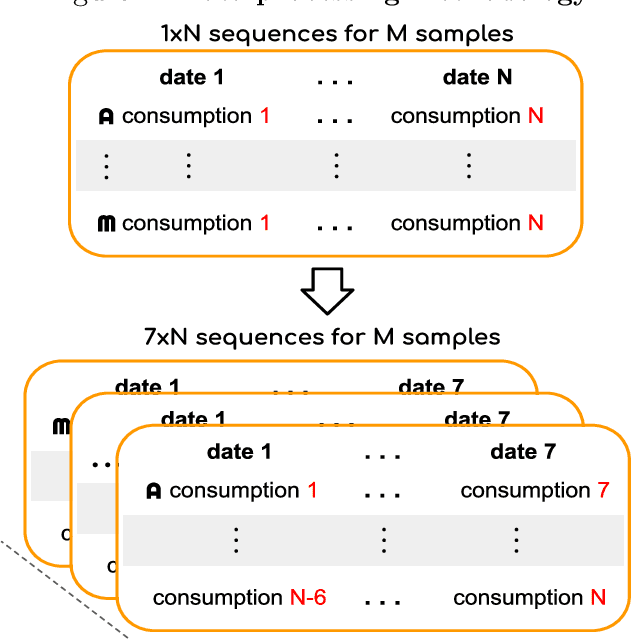



In this work we propose a novel self-attention mechanism model to address electricity theft detection on an imbalanced realistic dataset that presents a daily electricity consumption provided by State Grid Corporation of China. Our key contribution is the introduction of a multi-head self-attention mechanism concatenated with dilated convolutions and unified by a convolution of kernel size $1$. Moreover, we introduce a binary input channel (Binary Mask) to identify the position of the missing values, allowing the network to learn how to deal with these values. Our model achieves an AUC of $0.926$ which is an improvement in more than $17\%$ with respect to previous baseline work. The code is available on GitHub at https://github.com/neuralmind-ai/electricity-theft-detection-with-self-attention.