 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chronicles of RAG: The Retriever, the Chunk and the Generator
Jan 15, 2024



Retrieval Augmented Generation (RAG) has become one of the most popular paradigms for enabling LLMs to access external data, and also as a mechanism for grounding to mitigate against hallucinations. When implementing RAG you can face several challenges like effective integration of retrieval models, efficient representation learning, data diversity, computational efficiency optimization, evaluation, and quality of text generation. Given all these challenges, every day a new technique to improve RAG appears, making it unfeasible to experiment with all combinations for your problem. In this context, this paper presents good practices to implement, optimize, and evaluate RAG for the Brazilian Portuguese language, focusing on the establishment of a simple pipeline for inference and experiments. We explored a diverse set of methods to answer questions about the first Harry Potter book. To generate the answers we used the OpenAI's gpt-4, gpt-4-1106-preview, gpt-3.5-turbo-1106, and Google's Gemini Pro. Focusing on the quality of the retriever, our approach achieved an improvement of MRR@10 by 35.4% compared to the baseline. When optimizing the input size in the application, we observed that it is possible to further enhance it by 2.4%. Finally, we present the complete architecture of the RAG with our recommendations. As result, we moved from a baseline of 57.88% to a maximum relative score of 98.61%.
Cabrita: closing the gap for foreign languages
Aug 23, 2023



The strategy of training the model from scratch in a specific language or domain serves two essential purposes: i) enhancing performance in the particular linguistic or domain context, and ii) ensuring effective tokenization. The main limitation inherent to this approach lies in the associated cost, which can reach six to seven-digit dollar values, depending on the model size and the number of parameters involved. The main solution to overcome the cost challenge is to rely on available pre-trained models, which, despite recent advancements such as the LLaMA and LLaMA-2 models, still demonstrate inefficiency for certain specific domain problems or prove ineffective in scenarios involving conversational memory resources, given the large number of tokens required to represent text. To overcome this issue, we present a methodology named Cabrita, which, as our research demonstrates, successfully addresses the performance and efficient tokenization problem, all at an affordable cost. We believe that this methodology can be applied to any transformer-like architecture model. To validate the study, we conducted continuous pre-training exclusively using Portuguese text on a 3-billion-parameter model known as OpenLLaMA, resulting in a model named openCabrita 3B. The openCabrita 3B also features a new tokenizer that results in a significant reduction in the number of tokens required to represent the text. In our assessment, for few-shot learning tasks, we achieved similar results with this 3B model compared to a traditional continuous pre-training approach as well as to 7B models English pre-trained models.
Semantic Sensitive TF-IDF to Determine Word Relevance in Documents
Jan 06, 2020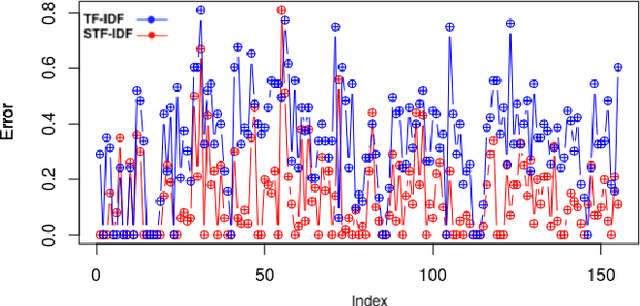
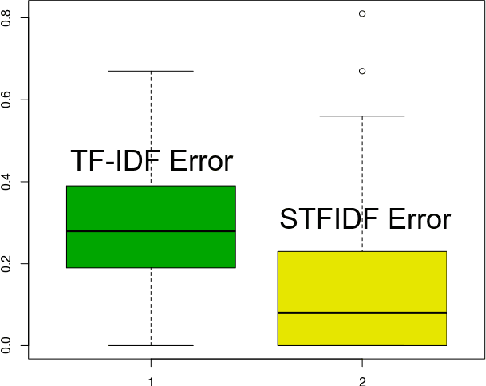
Keyword extraction has received an increasing attention as an important research topic which can lead to have advancements in diverse applications such as document context categorization, text indexing and document classification. In this paper we propose STF-IDF, a novel semantic method based on TF-IDF, for scoring word importance of informal documents in a corpus. A set of nearly four million documents from health-care social media was collected and was trained in order to draw semantic model and to find the word embeddings. Then, the features of semantic space were utilized to rearrange the original TF-IDF scores through an iterative solution so as to improve the moderate performance of this algorithm on informal texts. After testing the proposed method with 200 randomly chosen documents, our method managed to decrease the TF-IDF mean error rate by a factor of 50% and reaching the mean error of 13.7%, as opposed to 27.2% of the original TF-IDF.
Can NetGAN be improved by short random walks originated from dense vertices?
May 13, 2019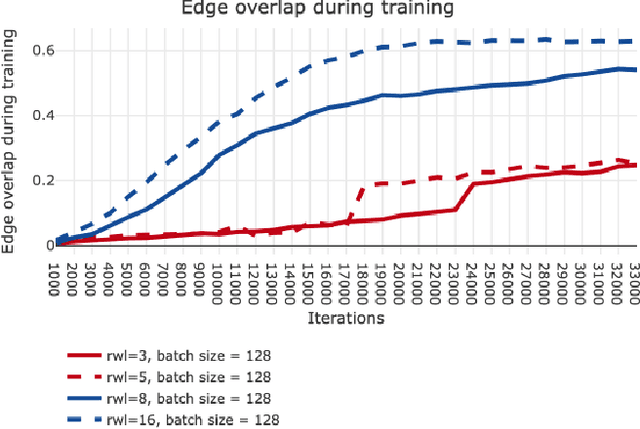
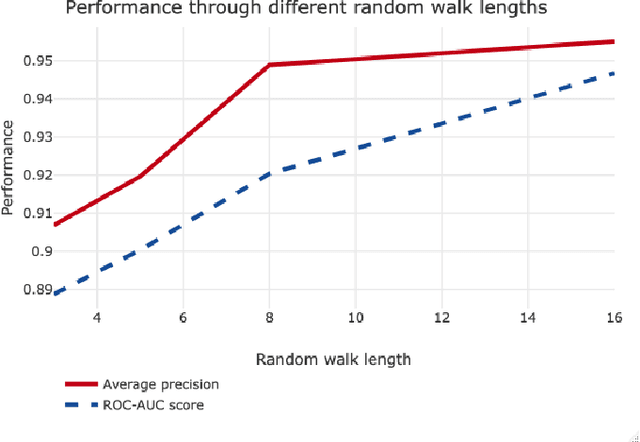
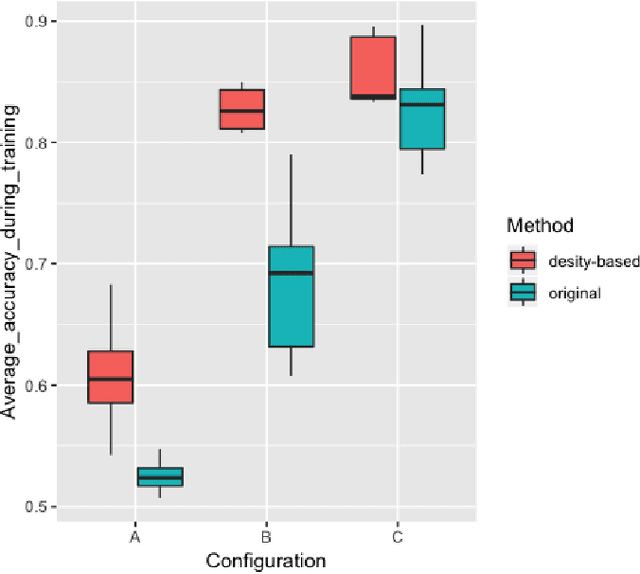
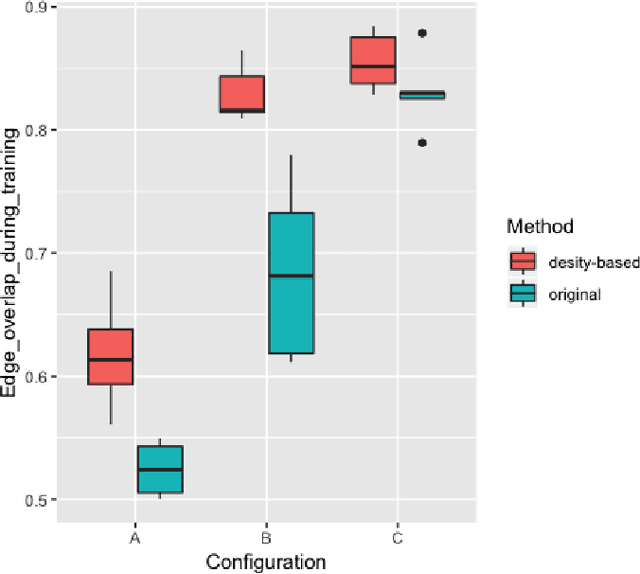
Graphs are useful structures that can model several important real-world problems. Recently, learning graphs have drawn considerable attention, leading to the proposal of new methods for learning these data structures. One of these studies produced NetGAN, a new approach for generating graphs via random walks. Although NetGAN has shown promising results in terms of accuracy in the tasks of generating graphs and link prediction, the choice of vertices from which it starts random walks can lead to inconsistent and highly variable results, especially when the length of walks is short. As an alternative to random starting, this study aims to establish a new method for initializing random walks from a set of dense vertices. We purpose estimating the importance of a node based on the inverse of its influence over the whole vertices of its neighborhood through random walks of different sizes. The proposed method manages to achieve significantly better accuracy, less variance and lesser outliers.