 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chronicles of RAG: The Retriever, the Chunk and the Generator
Jan 15, 2024



Retrieval Augmented Generation (RAG) has become one of the most popular paradigms for enabling LLMs to access external data, and also as a mechanism for grounding to mitigate against hallucinations. When implementing RAG you can face several challenges like effective integration of retrieval models, efficient representation learning, data diversity, computational efficiency optimization, evaluation, and quality of text generation. Given all these challenges, every day a new technique to improve RAG appears, making it unfeasible to experiment with all combinations for your problem. In this context, this paper presents good practices to implement, optimize, and evaluate RAG for the Brazilian Portuguese language, focusing on the establishment of a simple pipeline for inference and experiments. We explored a diverse set of methods to answer questions about the first Harry Potter book. To generate the answers we used the OpenAI's gpt-4, gpt-4-1106-preview, gpt-3.5-turbo-1106, and Google's Gemini Pro. Focusing on the quality of the retriever, our approach achieved an improvement of MRR@10 by 35.4% compared to the baseline. When optimizing the input size in the application, we observed that it is possible to further enhance it by 2.4%. Finally, we present the complete architecture of the RAG with our recommendations. As result, we moved from a baseline of 57.88% to a maximum relative score of 98.61%.
UstanceBR: a multimodal language resource for stance prediction
Jan 04, 2024
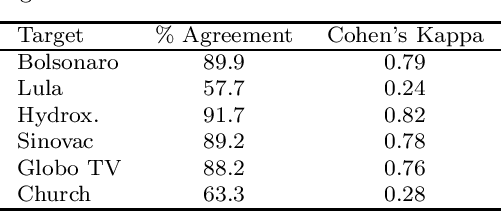
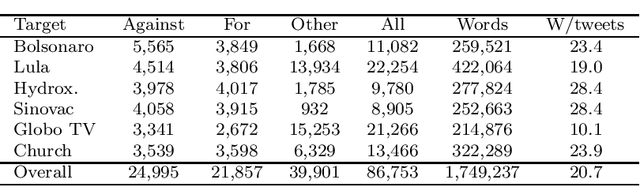
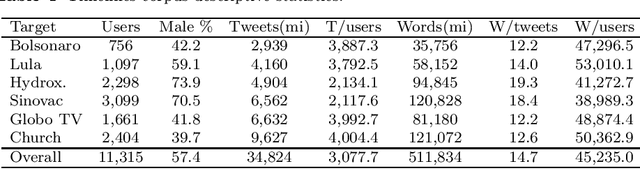
This work introduces UstanceBR, a multimodal corpus in the Brazilian Portuguese Twitter domain for target-based stance prediction. The corpus comprises 86.8 k labelled stances towards selected target topics, and extensive network information about the users who published these stances on social media. In this article we describe the corpus multimodal data, and a number of usage examples in both in-domain and zero-shot stance prediction based on text- and network-related information, which are intended to provide initial baseline results for future studies in the field.