 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based mental health screening from social media text
Jan 11, 2024



This article presents a method for prompt-based mental health screening from a large and noisy dataset of social media text. Our method uses GPT 3.5. prompting to distinguish publications that may be more relevant to the task, and then uses a straightforward bag-of-words text classifier to predict actual user labels. Results are found to be on pair with a BERT mixture of experts classifier, and incurring only a fraction of its computational costs.
UstanceBR: a multimodal language resource for stance prediction
Jan 04, 2024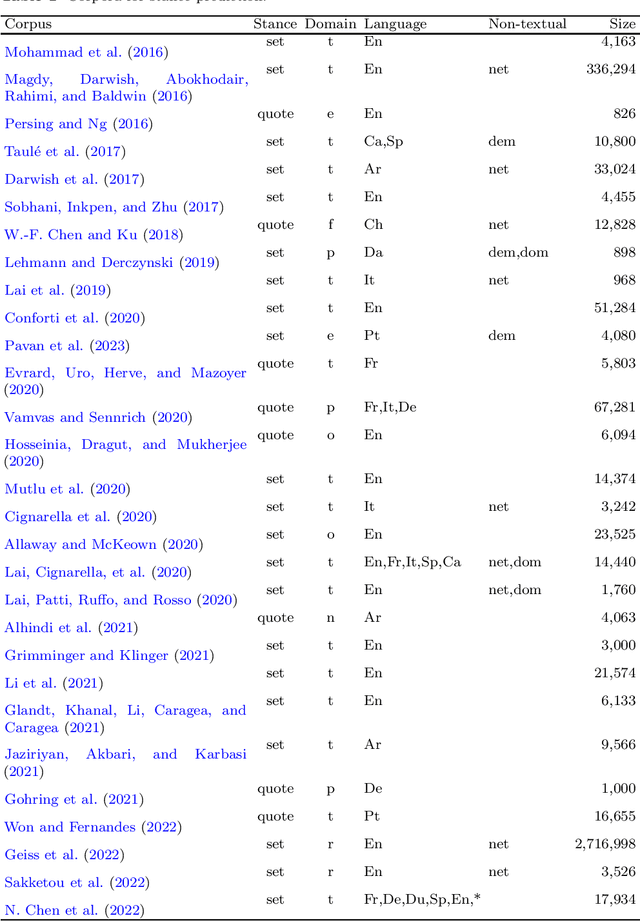
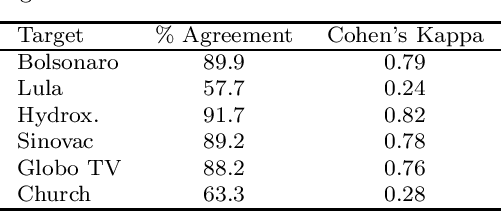
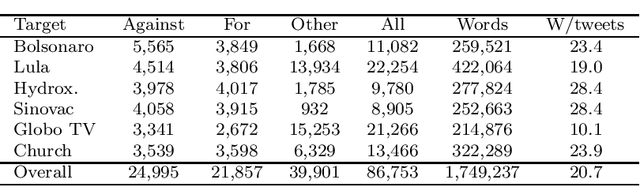
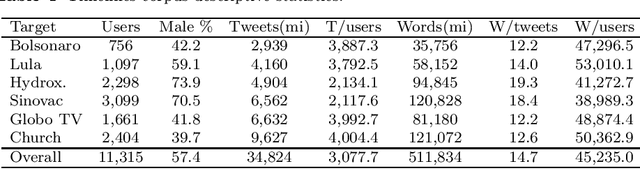
This work introduces UstanceBR, a multimodal corpus in the Brazilian Portuguese Twitter domain for target-based stance prediction. The corpus comprises 86.8 k labelled stances towards selected target topics, and extensive network information about the users who published these stances on social media. In this article we describe the corpus multimodal data, and a number of usage examples in both in-domain and zero-shot stance prediction based on text- and network-related information, which are intended to provide initial baseline results for future studies in the field.
Text and author-level political inference using heterogeneous knowledge representations
Jun 24, 2022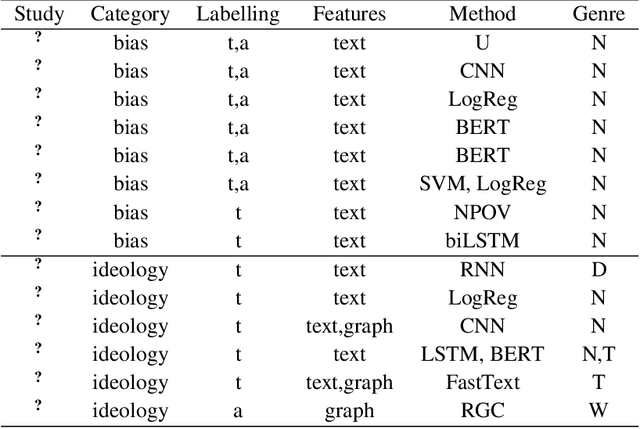
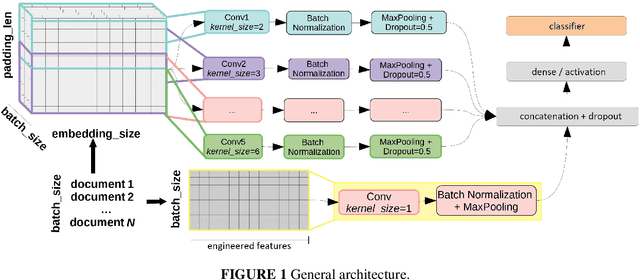


The inference of politically-charged information from text data is a popular research topic in Natural Language Processing (NLP) at both text- and author-level. In recent years, studies of this kind have been implemented with the aid of representations from transformers such as BERT. Despite considerable success, however, we may ask whether results may be improved even further by combining transformed-based models with additional knowledge representations. To shed light on this issue, the present work describes a series of experiments to compare alternative model configurations for political inference from text in both English and Portuguese languages. Results suggest that certain text representations - in particular, the combined use of BERT pre-trained language models with a syntactic dependency model - may outperform the alternatives across multiple experimental settings, making a potentially strong case for further research in the use of heterogeneous text representations in these and possibly other NLP tasks.
Semi-automatic definite description annotation: a first report
Dec 24, 2017

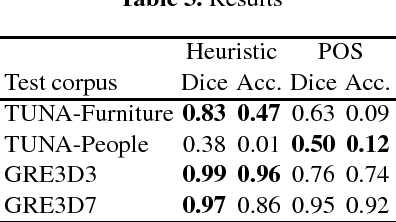
Studies in Referring Expression Generation (REG) often make use of corpora of definite descriptions produced by human subjects in controlled experiments. Experiments of this kind, which are essential for the study of reference phenomena and many others, may however include a considerable amount of noise. Human subjects may easily lack attention, or may simply misunderstand the task at hand and, as a result, the elicited data may include large proportions of ambiguous or ill-formed descriptions. In addition to that, REG corpora are usually collected for the study of semantics-related phenomena, and it is often the case that the elicited descriptions (and their input contexts) need to be annotated with their corresponding semantic properties. This, as in many other fields, may require considerable time and skilled annotators. As a means to tackle both kinds of difficulties - poor data quality and high annotation costs - this work discusses a semi-automatic method for the annotation of definite descriptions produced by human subjects in REG data collection experiments. The method makes use of simple rules to establish associations between words and meanings, and is intended to facilitate the design of experiments that produce REG corpora.
Trainable Referring Expression Generation using Overspecification Preferences
Apr 12, 2017


Referring expression generation (REG) models that use speaker-dependent information require a considerable amount of training data produced by every individual speaker, or may otherwise perform poorly. In this work we present a simple REG experiment that allows the use of larger training data sets by grouping speakers according to their overspecification preferences. Intrinsic evaluation shows that this method generally outperforms the personalised method found in previous work.