 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-automatic definite description annotation: a first report
Dec 24, 2017

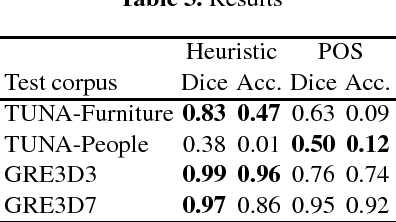
Studies in Referring Expression Generation (REG) often make use of corpora of definite descriptions produced by human subjects in controlled experiments. Experiments of this kind, which are essential for the study of reference phenomena and many others, may however include a considerable amount of noise. Human subjects may easily lack attention, or may simply misunderstand the task at hand and, as a result, the elicited data may include large proportions of ambiguous or ill-formed descriptions. In addition to that, REG corpora are usually collected for the study of semantics-related phenomena, and it is often the case that the elicited descriptions (and their input contexts) need to be annotated with their corresponding semantic properties. This, as in many other fields, may require considerable time and skilled annotators. As a means to tackle both kinds of difficulties - poor data quality and high annotation costs - this work discusses a semi-automatic method for the annotation of definite descriptions produced by human subjects in REG data collection experiments. The method makes use of simple rules to establish associations between words and meanings, and is intended to facilitate the design of experiments that produce REG corpora.