 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Sensitive TF-IDF to Determine Word Relevance in Documents
Jan 06, 2020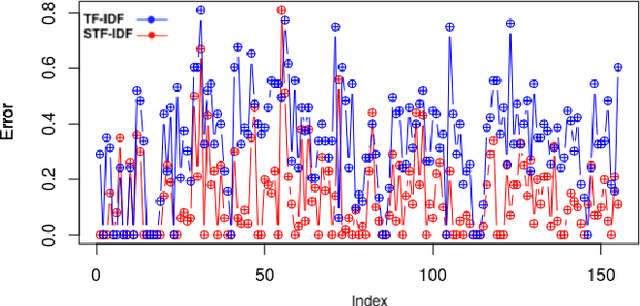
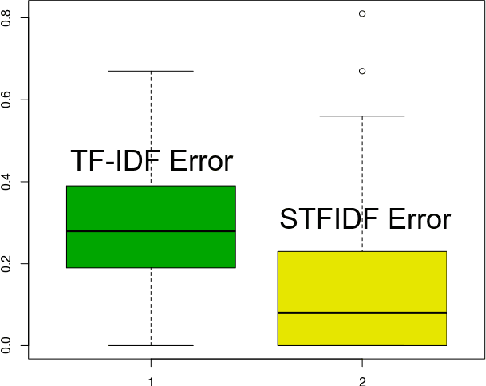
Keyword extraction has received an increasing attention as an important research topic which can lead to have advancements in diverse applications such as document context categorization, text indexing and document classification. In this paper we propose STF-IDF, a novel semantic method based on TF-IDF, for scoring word importance of informal documents in a corpus. A set of nearly four million documents from health-care social media was collected and was trained in order to draw semantic model and to find the word embeddings. Then, the features of semantic space were utilized to rearrange the original TF-IDF scores through an iterative solution so as to improve the moderate performance of this algorithm on informal texts. After testing the proposed method with 200 randomly chosen documents, our method managed to decrease the TF-IDF mean error rate by a factor of 50% and reaching the mean error of 13.7%, as opposed to 27.2% of the original TF-IDF.
Can NetGAN be improved by short random walks originated from dense vertices?
May 13, 2019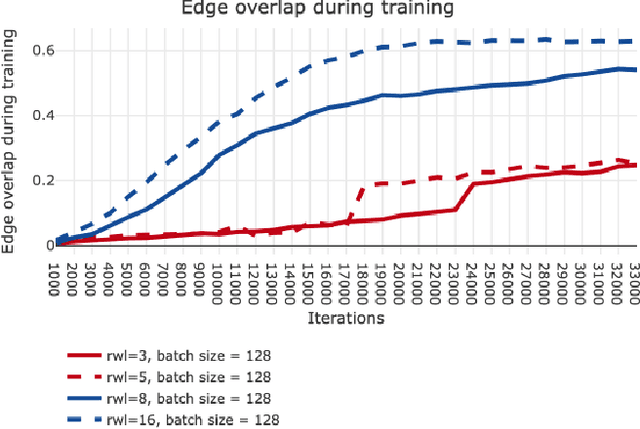
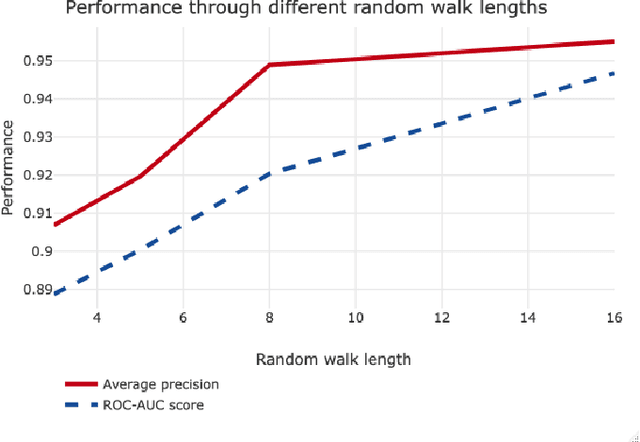
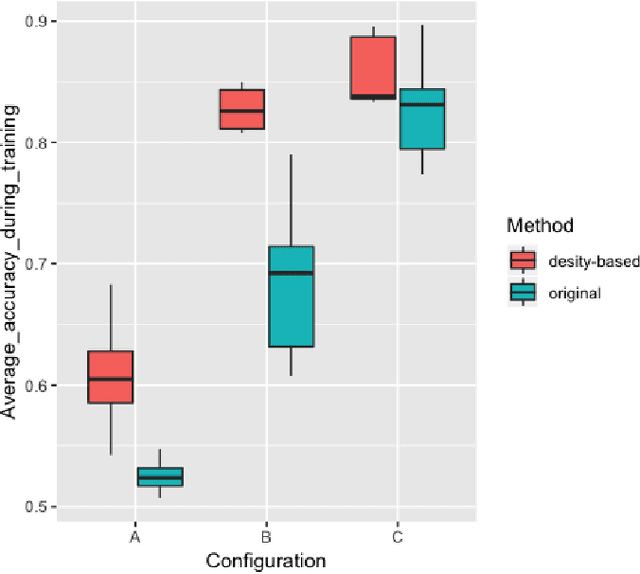
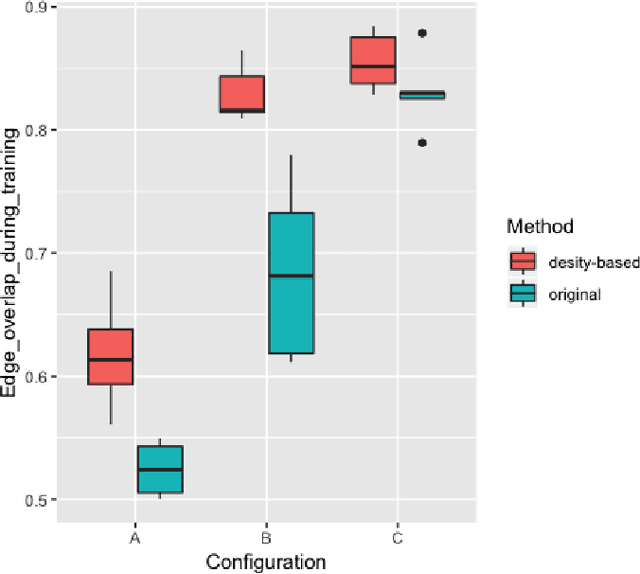
Graphs are useful structures that can model several important real-world problems. Recently, learning graphs have drawn considerable attention, leading to the proposal of new methods for learning these data structures. One of these studies produced NetGAN, a new approach for generating graphs via random walks. Although NetGAN has shown promising results in terms of accuracy in the tasks of generating graphs and link prediction, the choice of vertices from which it starts random walks can lead to inconsistent and highly variable results, especially when the length of walks is short. As an alternative to random starting, this study aims to establish a new method for initializing random walks from a set of dense vertices. We purpose estimating the importance of a node based on the inverse of its influence over the whole vertices of its neighborhood through random walks of different sizes. The proposed method manages to achieve significantly better accuracy, less variance and lesser outliers.