 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePortuguese FAQ for Financial Services
Nov 19, 2023
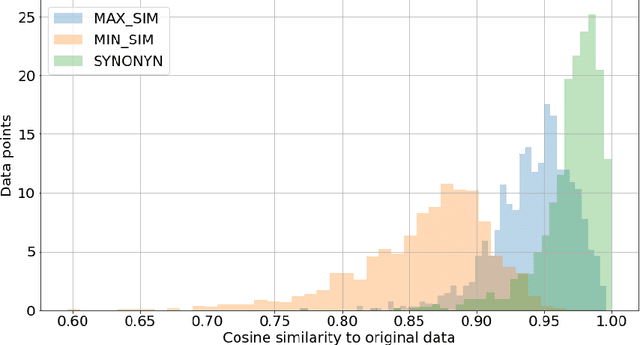


Scarcity of domain-specific data in the Portuguese financial domain has disfavored the development of Natural Language Processing (NLP) applications. To address this limitation, the present study advocates for the utilization of synthetic data generated through data augmentation techniques. The investigation focuses on the augmentation of a dataset sourced from the Central Bank of Brazil FAQ, employing techniques that vary in semantic similarity. Supervised and unsupervised tasks are conducted to evaluate the impact of augmented data on both low and high semantic similarity scenarios. Additionally, the resultant dataset will be publicly disseminated on the Hugging Face Datasets platform, thereby enhancing accessibility and fostering broader engagement within the NLP research community.
BERTaú: Itaú BERT for digital customer service
Jan 28, 2021
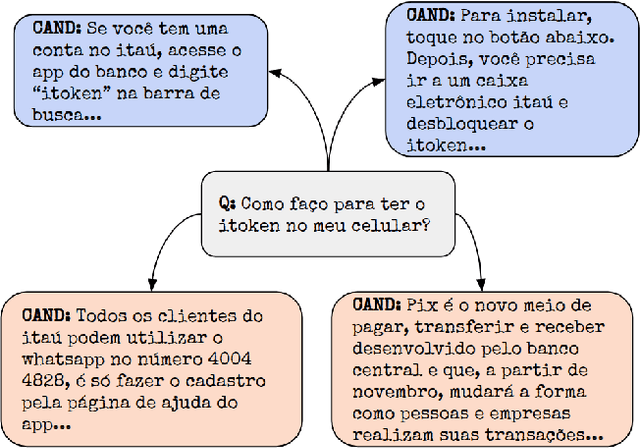

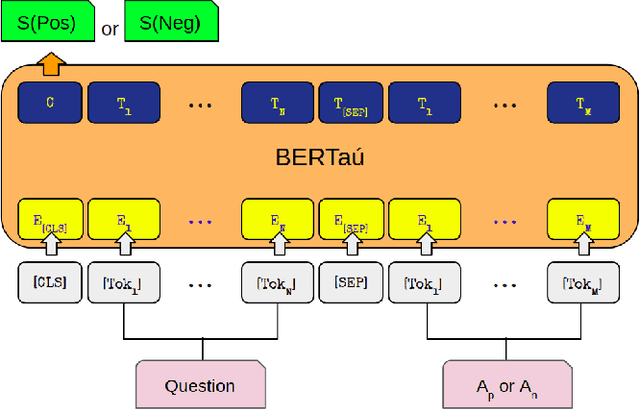
In the last few years, three major topics received increased interest: deep learning, NLP and conversational agents. Bringing these three topics together to create an amazing digital customer experience and indeed deploy in production and solve real-world problems is something innovative and disruptive. We introduce a new Portuguese financial domain language representation model called BERTa\'u. BERTa\'u is an uncased BERT-base trained from scratch with data from the Ita\'u virtual assistant chatbot solution. Our novel contribution is that BERTa\'u pretrained language model requires less data, reached state-of-the-art performance in three NLP tasks, and generates a smaller and lighter model that makes the deployment feasible. We developed three tasks to validate our model: information retrieval with Frequently Asked Questions (FAQ) from Ita\'u bank, sentiment analysis from our virtual assistant data, and a NER solution. All proposed tasks are real-world solutions in production on our environment and the usage of a specialist model proved to be effective when compared to Google BERT multilingual and the DPRQuestionEncoder from Facebook, available at Hugging Face. The BERTa\'u improves the performance in 22% of FAQ Retrieval MRR metric, 2.1% in Sentiment Analysis F1 score, 4.4% in NER F1 score and can also represent the same sequence in up to 66% fewer tokens when compared to "shelf models".