 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePortuguese FAQ for Financial Services
Paper and Code
Nov 19, 2023
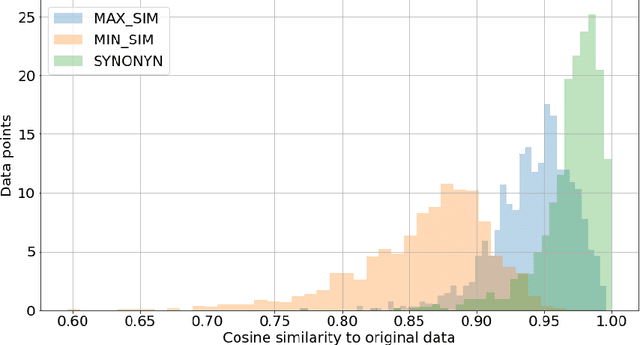


Scarcity of domain-specific data in the Portuguese financial domain has disfavored the development of Natural Language Processing (NLP) applications. To address this limitation, the present study advocates for the utilization of synthetic data generated through data augmentation techniques. The investigation focuses on the augmentation of a dataset sourced from the Central Bank of Brazil FAQ, employing techniques that vary in semantic similarity. Supervised and unsupervised tasks are conducted to evaluate the impact of augmented data on both low and high semantic similarity scenarios. Additionally, the resultant dataset will be publicly disseminated on the Hugging Face Datasets platform, thereby enhancing accessibility and fostering broader engagement within the NLP research community.