 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
Mar 18, 2024Diffusion models are the main driver of progress in image and video synthesis, but suffer from slow inference speed. Distillation methods, like the recently introduced adversarial diffusion distillation (ADD) aim to shift the model from many-shot to single-step inference, albeit at the cost of expensive and difficult optimization due to its reliance on a fixed pretrained DINOv2 discriminator. We introduce Latent Adversarial Diffusion Distillation (LADD), a novel distillation approach overcoming the limitations of ADD. In contrast to pixel-based ADD, LADD utilizes generative features from pretrained latent diffusion models. This approach simplifies training and enhances performance, enabling high-resolution multi-aspect ratio image synthesis. We apply LADD to Stable Diffusion 3 (8B) to obtain SD3-Turbo, a fast model that matches the performance of state-of-the-art text-to-image generators using only four unguided sampling steps. Moreover, we systematically investigate its scaling behavior and demonstrate LADD's effectiveness in various applications such as image editing and inpainting.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024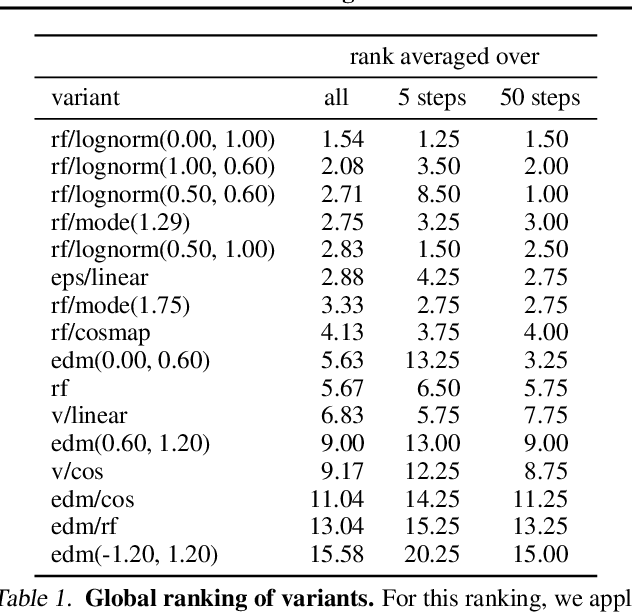
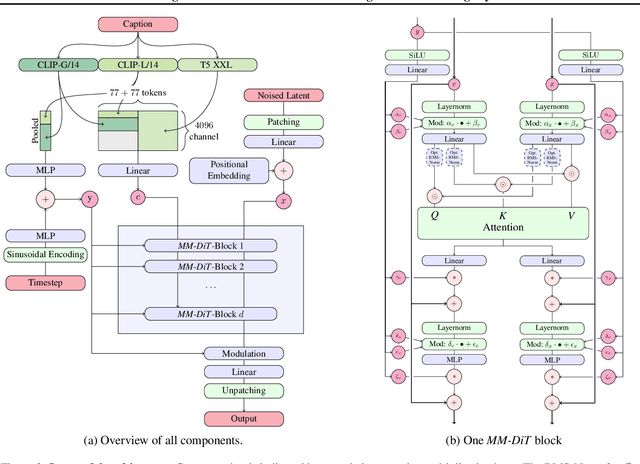
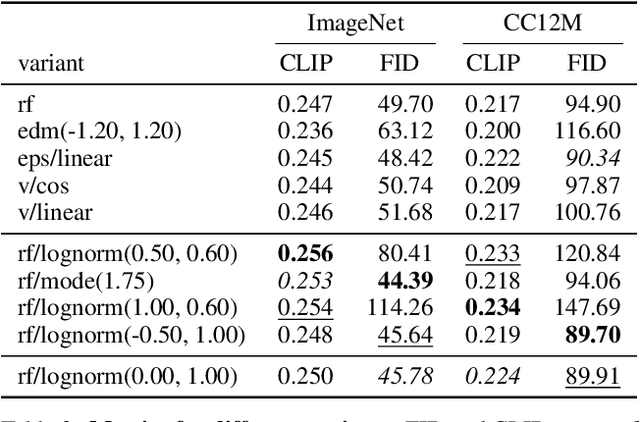
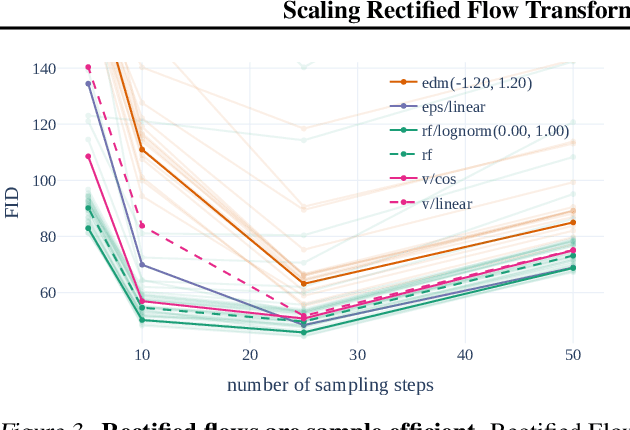
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.
Towards Unified Keyframe Propagation Models
May 19, 2022



Many video editing tasks such as rotoscoping or object removal require the propagation of context across frames. While transformers and other attention-based approaches that aggregate features globally have demonstrated great success at propagating object masks from keyframes to the whole video, they struggle to propagate high-frequency details such as textures faithfully. We hypothesize that this is due to an inherent bias of global attention towards low-frequency features. To overcome this limitation, we present a two-stream approach, where high-frequency features interact locally and low-frequency features interact globally. The global interaction stream remains robust in difficult situations such as large camera motions, where explicit alignment fails. The local interaction stream propagates high-frequency details through deformable feature aggregation and, informed by the global interaction stream, learns to detect and correct errors of the deformation field. We evaluate our two-stream approach for inpainting tasks, where experiments show that it improves both the propagation of features within a single frame as required for image inpainting, as well as their propagation from keyframes to target frames. Applied to video inpainting, our approach leads to 44% and 26% improvements in FID and LPIPS scores. Code at https://github.com/runwayml/guided-inpainting
High-Resolution Image Synthesis with Latent Diffusion Models
Dec 20, 2021


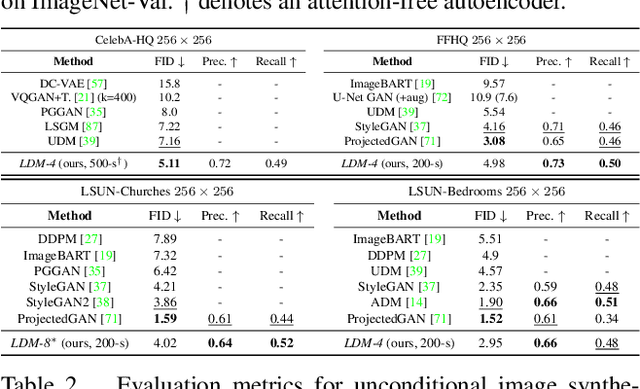
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs. Code is available at https://github.com/CompVis/latent-diffusion .
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.
Geometry-Free View Synthesis: Transformers and no 3D Priors
Apr 15, 2021
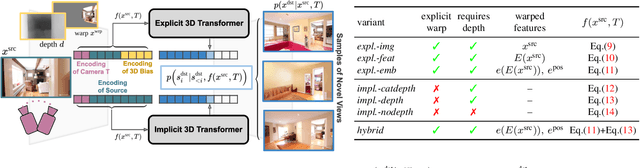
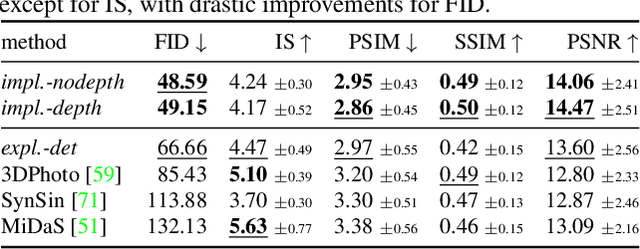

Is a geometric model required to synthesize novel views from a single image? Being bound to local convolutions, CNNs need explicit 3D biases to model geometric transformations. In contrast, we demonstrate that a transformer-based model can synthesize entirely novel views without any hand-engineered 3D biases. This is achieved by (i) a global attention mechanism for implicitly learning long-range 3D correspondences between source and target views, and (ii) a probabilistic formulation necessary to capture the ambiguity inherent in predicting novel views from a single image, thereby overcoming the limitations of previous approaches that are restricted to relatively small viewpoint changes. We evaluate various ways to integrate 3D priors into a transformer architecture. However, our experiments show that no such geometric priors are required and that the transformer is capable of implicitly learning 3D relationships between images. Furthermore, this approach outperforms the state of the art in terms of visual quality while covering the full distribution of possible realizations. Code is available at https://git.io/JOnwn
Shape or Texture: Understanding Discriminative Features in CNNs
Jan 27, 2021
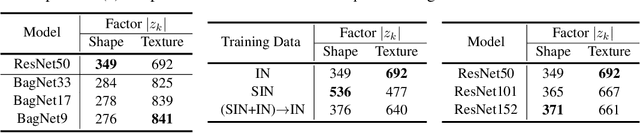

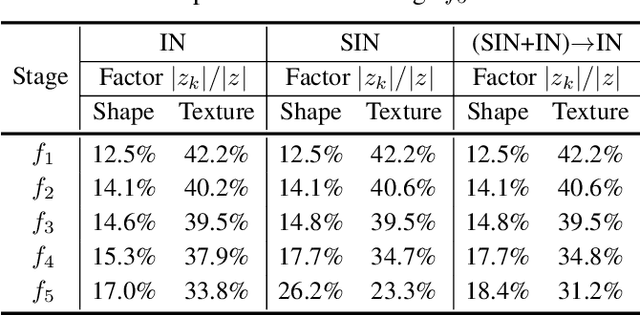
Contrasting the previous evidence that neurons in the later layers of a Convolutional Neural Network (CNN) respond to complex object shapes, recent studies have shown that CNNs actually exhibit a `texture bias': given an image with both texture and shape cues (e.g., a stylized image), a CNN is biased towards predicting the category corresponding to the texture. However, these previous studies conduct experiments on the final classification output of the network, and fail to robustly evaluate the bias contained (i) in the latent representations, and (ii) on a per-pixel level. In this paper, we design a series of experiments that overcome these issues. We do this with the goal of better understanding what type of shape information contained in the network is discriminative, where shape information is encoded, as well as when the network learns about object shape during training. We show that a network learns the majority of overall shape information at the first few epochs of training and that this information is largely encoded in the last few layers of a CNN. Finally, we show that the encoding of shape does not imply the encoding of localized per-pixel semantic information. The experimental results and findings provide a more accurate understanding of the behaviour of current CNNs, thus helping to inform future design choices.
Taming Transformers for High-Resolution Image Synthesis
Dec 17, 2020



Designed to learn long-range interactions on sequential data, transformers continue to show state-of-the-art results on a wide variety of tasks. In contrast to CNNs, they contain no inductive bias that prioritizes local interactions. This makes them expressive, but also computationally infeasible for long sequences, such as high-resolution images. We demonstrate how combining the effectiveness of the inductive bias of CNNs with the expressivity of transformers enables them to model and thereby synthesize high-resolution images. We show how to (i) use CNNs to learn a context-rich vocabulary of image constituents, and in turn (ii) utilize transformers to efficiently model their composition within high-resolution images. Our approach is readily applied to conditional synthesis tasks, where both non-spatial information, such as object classes, and spatial information, such as segmentations, can control the generated image. In particular, we present the first results on semantically-guided synthesis of megapixel images with transformers. Project page at https://compvis.github.io/taming-transformers/ .
A Note on Data Biases in Generative Models
Dec 04, 2020



It is tempting to think that machines are less prone to unfairness and prejudice. However, machine learning approaches compute their outputs based on data. While biases can enter at any stage of the development pipeline, models are particularly receptive to mirror biases of the datasets they are trained on and therefore do not necessarily reflect truths about the world but, primarily, truths about the data. To raise awareness about the relationship between modern algorithms and the data that shape them, we use a conditional invertible neural network to disentangle the dataset-specific information from the information which is shared across different datasets. In this way, we can project the same image onto different datasets, thereby revealing their inherent biases. We use this methodology to (i) investigate the impact of dataset quality on the performance of generative models, (ii) show how societal biases of datasets are replicated by generative models, and (iii) present creative applications through unpaired transfer between diverse datasets such as photographs, oil portraits, and animes. Our code and an interactive demonstration are available at https://github.com/CompVis/net2net .