 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
Mar 18, 2024Diffusion models are the main driver of progress in image and video synthesis, but suffer from slow inference speed. Distillation methods, like the recently introduced adversarial diffusion distillation (ADD) aim to shift the model from many-shot to single-step inference, albeit at the cost of expensive and difficult optimization due to its reliance on a fixed pretrained DINOv2 discriminator. We introduce Latent Adversarial Diffusion Distillation (LADD), a novel distillation approach overcoming the limitations of ADD. In contrast to pixel-based ADD, LADD utilizes generative features from pretrained latent diffusion models. This approach simplifies training and enhances performance, enabling high-resolution multi-aspect ratio image synthesis. We apply LADD to Stable Diffusion 3 (8B) to obtain SD3-Turbo, a fast model that matches the performance of state-of-the-art text-to-image generators using only four unguided sampling steps. Moreover, we systematically investigate its scaling behavior and demonstrate LADD's effectiveness in various applications such as image editing and inpainting.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024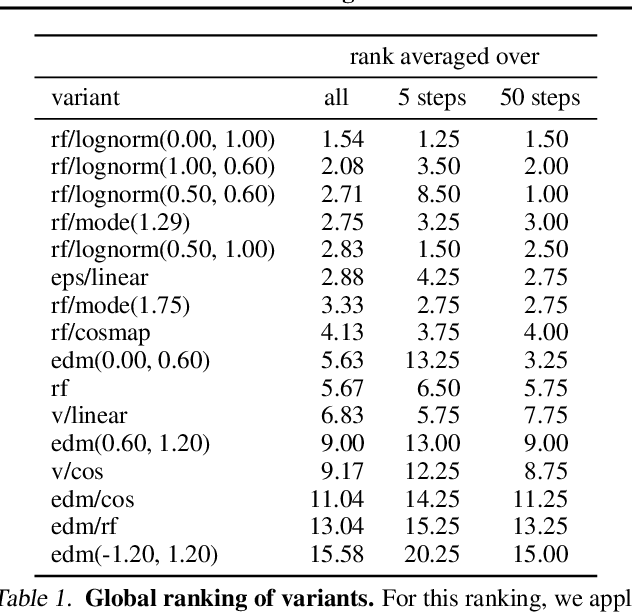
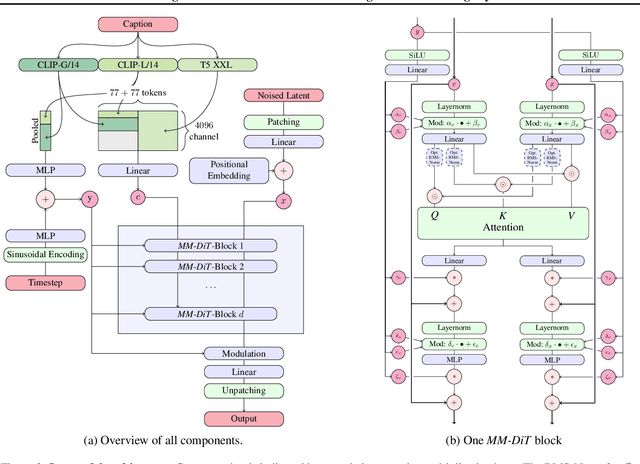
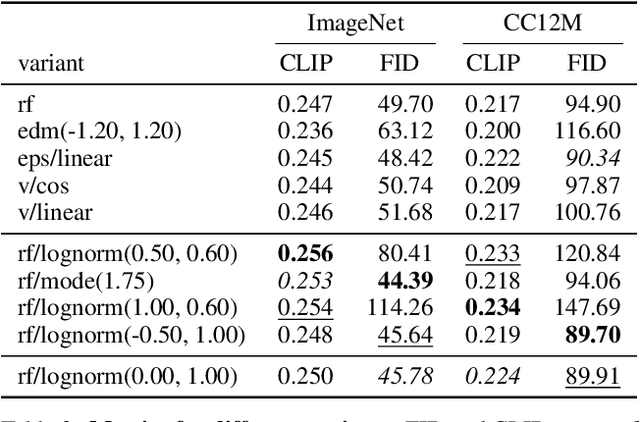
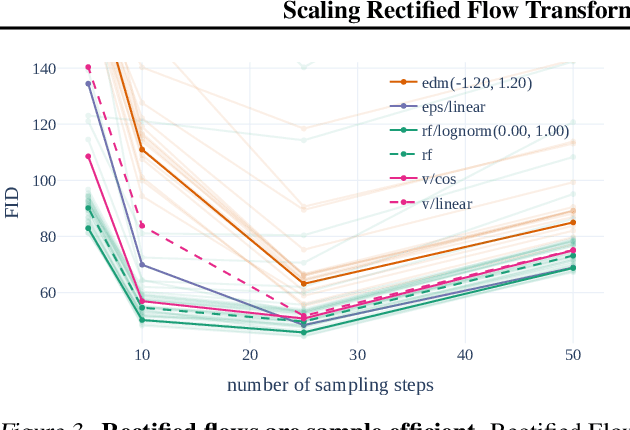
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
Adversarial Diffusion Distillation
Nov 28, 2023We introduce Adversarial Diffusion Distillation (ADD), a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1-4 steps while maintaining high image quality. We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps. Our analyses show that our model clearly outperforms existing few-step methods (GANs, Latent Consistency Models) in a single step and reaches the performance of state-of-the-art diffusion models (SDXL) in only four steps. ADD is the first method to unlock single-step, real-time image synthesis with foundation models. Code and weights available under https://github.com/Stability-AI/generative-models and https://huggingface.co/stabilityai/ .
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Nov 25, 2023



We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Jul 04, 2023

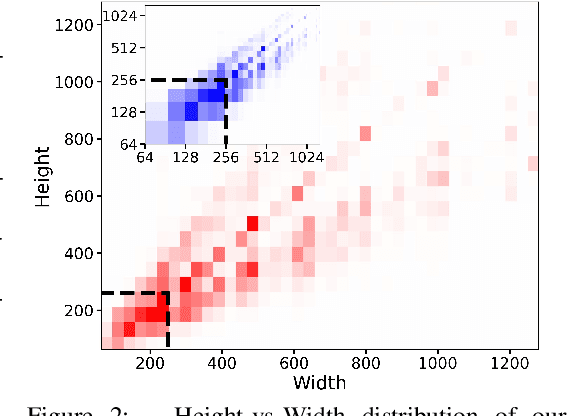
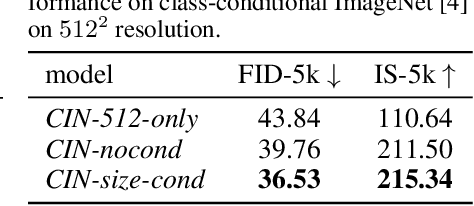
We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators. In the spirit of promoting open research and fostering transparency in large model training and evaluation, we provide access to code and model weights at https://github.com/Stability-AI/generative-models
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Apr 18, 2023Latent Diffusion Models (LDMs) enable high-quality image synthesis while avoiding excessive compute demands by training a diffusion model in a compressed lower-dimensional latent space. Here, we apply the LDM paradigm to high-resolution video generation, a particularly resource-intensive task. We first pre-train an LDM on images only; then, we turn the image generator into a video generator by introducing a temporal dimension to the latent space diffusion model and fine-tuning on encoded image sequences, i.e., videos. Similarly, we temporally align diffusion model upsamplers, turning them into temporally consistent video super resolution models. We focus on two relevant real-world applications: Simulation of in-the-wild driving data and creative content creation with text-to-video modeling. In particular, we validate our Video LDM on real driving videos of resolution 512 x 1024, achieving state-of-the-art performance. Furthermore, our approach can easily leverage off-the-shelf pre-trained image LDMs, as we only need to train a temporal alignment model in that case. Doing so, we turn the publicly available, state-of-the-art text-to-image LDM Stable Diffusion into an efficient and expressive text-to-video model with resolution up to 1280 x 2048. We show that the temporal layers trained in this way generalize to different fine-tuned text-to-image LDMs. Utilizing this property, we show the first results for personalized text-to-video generation, opening exciting directions for future content creation. Project page: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
Jul 26, 2022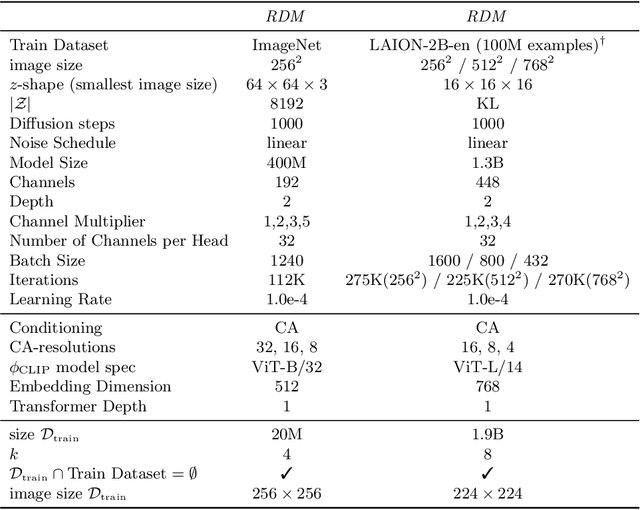
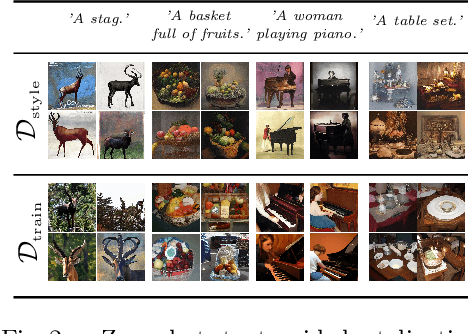

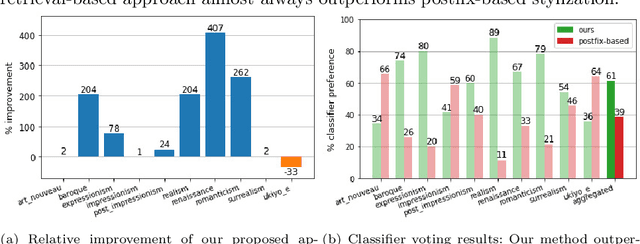
Novel architectures have recently improved generative image synthesis leading to excellent visual quality in various tasks. Of particular note is the field of ``AI-Art'', which has seen unprecedented growth with the emergence of powerful multimodal models such as CLIP. By combining speech and image synthesis models, so-called ``prompt-engineering'' has become established, in which carefully selected and composed sentences are used to achieve a certain visual style in the synthesized image. In this note, we present an alternative approach based on retrieval-augmented diffusion models (RDMs). In RDMs, a set of nearest neighbors is retrieved from an external database during training for each training instance, and the diffusion model is conditioned on these informative samples. During inference (sampling), we replace the retrieval database with a more specialized database that contains, for example, only images of a particular visual style. This provides a novel way to prompt a general trained model after training and thereby specify a particular visual style. As shown by our experiments, this approach is superior to specifying the visual style within the text prompt. We open-source code and model weights at https://github.com/CompVis/latent-diffusion .
Retrieval-Augmented Diffusion Models
Apr 26, 2022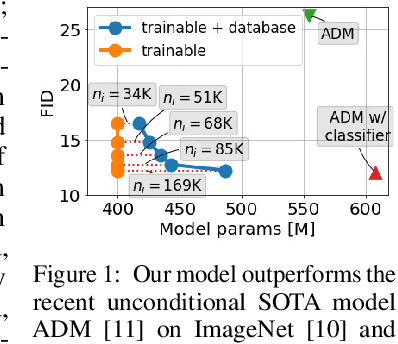
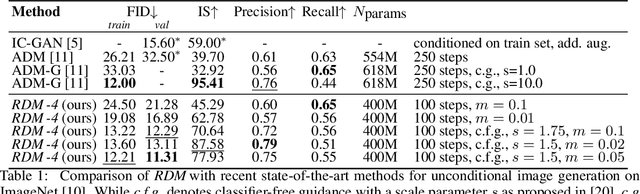


Generative image synthesis with diffusion models has recently achieved excellent visual quality in several tasks such as text-based or class-conditional image synthesis. Much of this success is due to a dramatic increase in the computational capacity invested in training these models. This work presents an alternative approach: inspired by its successful application in natural language processing, we propose to complement the diffusion model with a retrieval-based approach and to introduce an explicit memory in the form of an external database. During training, our diffusion model is trained with similar visual features retrieved via CLIP and from the neighborhood of each training instance. By leveraging CLIP's joint image-text embedding space, our model achieves highly competitive performance on tasks for which it has not been explicitly trained, such as class-conditional or text-image synthesis, and can be conditioned on both text and image embeddings. Moreover, we can apply our approach to unconditional generation, where it achieves state-of-the-art performance. Our approach incurs low computational and memory overheads and is easy to implement. We discuss its relationship to concurrent work and will publish code and pretrained models soon.
High-Resolution Image Synthesis with Latent Diffusion Models
Dec 20, 2021


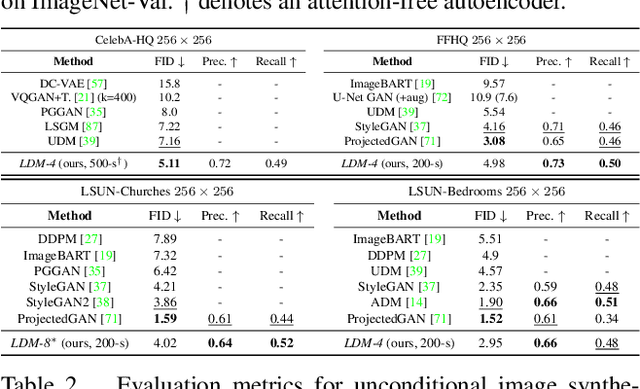
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs. Code is available at https://github.com/CompVis/latent-diffusion .
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.