 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
Paper and Code
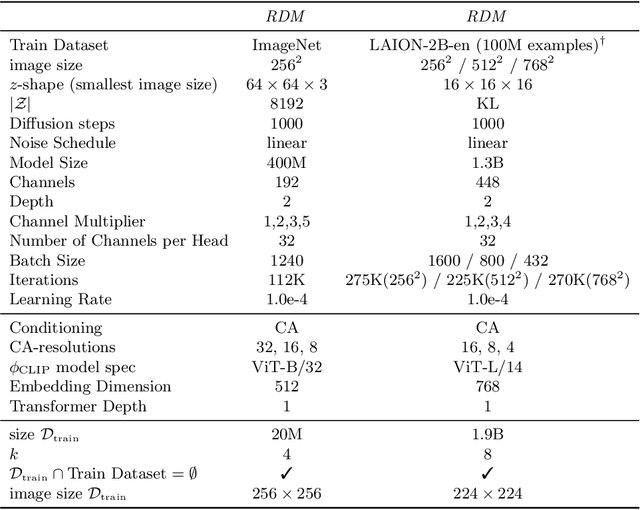
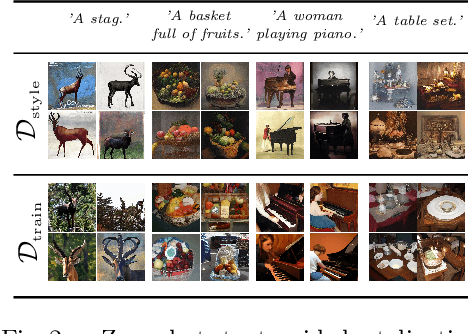

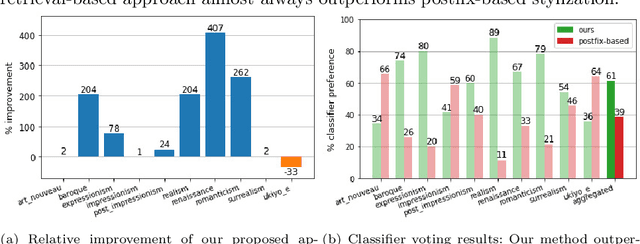
Novel architectures have recently improved generative image synthesis leading to excellent visual quality in various tasks. Of particular note is the field of ``AI-Art'', which has seen unprecedented growth with the emergence of powerful multimodal models such as CLIP. By combining speech and image synthesis models, so-called ``prompt-engineering'' has become established, in which carefully selected and composed sentences are used to achieve a certain visual style in the synthesized image. In this note, we present an alternative approach based on retrieval-augmented diffusion models (RDMs). In RDMs, a set of nearest neighbors is retrieved from an external database during training for each training instance, and the diffusion model is conditioned on these informative samples. During inference (sampling), we replace the retrieval database with a more specialized database that contains, for example, only images of a particular visual style. This provides a novel way to prompt a general trained model after training and thereby specify a particular visual style. As shown by our experiments, this approach is superior to specifying the visual style within the text prompt. We open-source code and model weights at https://github.com/CompVis/latent-diffusion .