 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetro-Rank-In: A Ranking-Based Approach for Inorganic Materials Synthesis Planning
Feb 07, 2025Retrosynthesis strategically plans the synthesis of a chemical target compound from simpler, readily available precursor compounds. This process is critical for synthesizing novel inorganic materials, yet traditional methods in inorganic chemistry continue to rely on trial-and-error experimentation. Emerging machine-learning approaches struggle to generalize to entirely new reactions due to their reliance on known precursors, as they frame retrosynthesis as a multi-label classification task. To address these limitations, we propose Retro-Rank-In, a novel framework that reformulates the retrosynthesis problem by embedding target and precursor materials into a shared latent space and learning a pairwise ranker on a bipartite graph of inorganic compounds. We evaluate Retro-Rank-In's generalizability on challenging retrosynthesis dataset splits designed to mitigate data duplicates and overlaps. For instance, for Cr2AlB2, it correctly predicts the verified precursor pair CrB + Al despite never seeing them in training, a capability absent in prior work. Extensive experiments show that Retro-Rank-In sets a new state-of-the-art, particularly in out-of-distribution generalization and candidate set ranking, offering a powerful tool for accelerating inorganic material synthesis.
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023
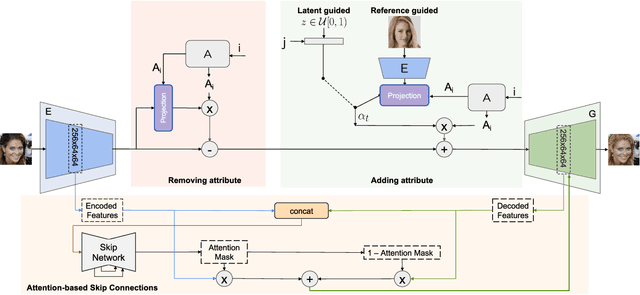
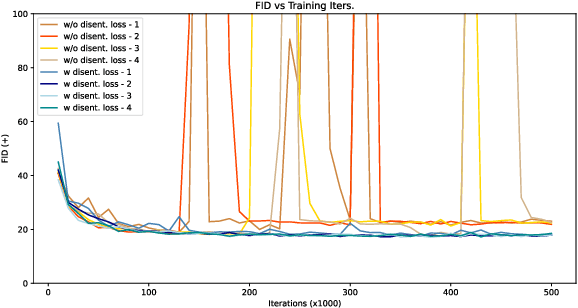

We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan