 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers
May 29, 2025We introduce LoRAShop, the first framework for multi-concept image editing with LoRA models. LoRAShop builds on a key observation about the feature interaction patterns inside Flux-style diffusion transformers: concept-specific transformer features activate spatially coherent regions early in the denoising process. We harness this observation to derive a disentangled latent mask for each concept in a prior forward pass and blend the corresponding LoRA weights only within regions bounding the concepts to be personalized. The resulting edits seamlessly integrate multiple subjects or styles into the original scene while preserving global context, lighting, and fine details. Our experiments demonstrate that LoRAShop delivers better identity preservation compared to baselines. By eliminating retraining and external constraints, LoRAShop turns personalized diffusion models into a practical `photoshop-with-LoRAs' tool and opens new avenues for compositional visual storytelling and rapid creative iteration.
Context Canvas: Enhancing Text-to-Image Diffusion Models with Knowledge Graph-Based RAG
Dec 12, 2024



We introduce a novel approach to enhance the capabilities of text-to-image models by incorporating a graph-based RAG. Our system dynamically retrieves detailed character information and relational data from the knowledge graph, enabling the generation of visually accurate and contextually rich images. This capability significantly improves upon the limitations of existing T2I models, which often struggle with the accurate depiction of complex or culturally specific subjects due to dataset constraints. Furthermore, we propose a novel self-correcting mechanism for text-to-image models to ensure consistency and fidelity in visual outputs, leveraging the rich context from the graph to guide corrections. Our qualitative and quantitative experiments demonstrate that Context Canvas significantly enhances the capabilities of popular models such as Flux, Stable Diffusion, and DALL-E, and improves the functionality of ControlNet for fine-grained image editing tasks. To our knowledge, Context Canvas represents the first application of graph-based RAG in enhancing T2I models, representing a significant advancement for producing high-fidelity, context-aware multi-faceted images.
FluxSpace: Disentangled Semantic Editing in Rectified Flow Transformers
Dec 12, 2024



Rectified flow models have emerged as a dominant approach in image generation, showcasing impressive capabilities in high-quality image synthesis. However, despite their effectiveness in visual generation, rectified flow models often struggle with disentangled editing of images. This limitation prevents the ability to perform precise, attribute-specific modifications without affecting unrelated aspects of the image. In this paper, we introduce FluxSpace, a domain-agnostic image editing method leveraging a representation space with the ability to control the semantics of images generated by rectified flow transformers, such as Flux. By leveraging the representations learned by the transformer blocks within the rectified flow models, we propose a set of semantically interpretable representations that enable a wide range of image editing tasks, from fine-grained image editing to artistic creation. This work offers a scalable and effective image editing approach, along with its disentanglement capabilities.
LayerFusion: Harmonized Multi-Layer Text-to-Image Generation with Generative Priors
Dec 05, 2024
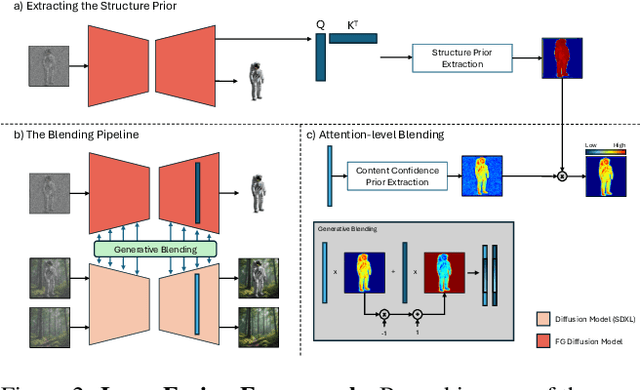

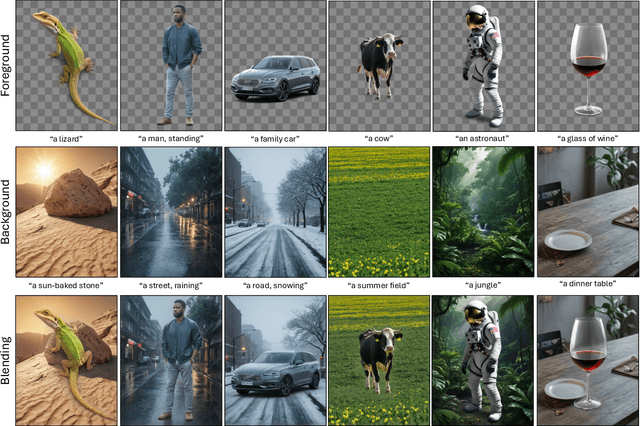
Large-scale diffusion models have achieved remarkable success in generating high-quality images from textual descriptions, gaining popularity across various applications. However, the generation of layered content, such as transparent images with foreground and background layers, remains an under-explored area. Layered content generation is crucial for creative workflows in fields like graphic design, animation, and digital art, where layer-based approaches are fundamental for flexible editing and composition. In this paper, we propose a novel image generation pipeline based on Latent Diffusion Models (LDMs) that generates images with two layers: a foreground layer (RGBA) with transparency information and a background layer (RGB). Unlike existing methods that generate these layers sequentially, our approach introduces a harmonized generation mechanism that enables dynamic interactions between the layers for more coherent outputs. We demonstrate the effectiveness of our method through extensive qualitative and quantitative experiments, showing significant improvements in visual coherence, image quality, and layer consistency compared to baseline methods.
The Curious Case of End Token: A Zero-Shot Disentangled Image Editing using CLIP
Jun 01, 2024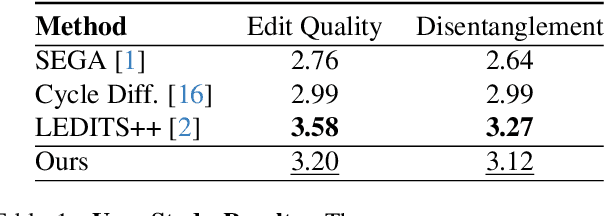
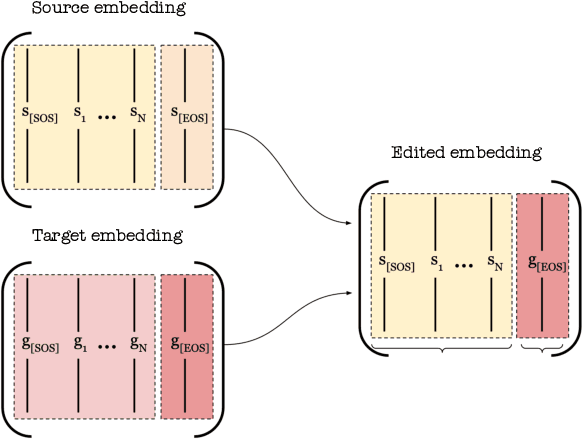


Diffusion models have become prominent in creating high-quality images. However, unlike GAN models celebrated for their ability to edit images in a disentangled manner, diffusion-based text-to-image models struggle to achieve the same level of precise attribute manipulation without compromising image coherence. In this paper, CLIP which is often used in popular text-to-image diffusion models such as Stable Diffusion is capable of performing disentangled editing in a zero-shot manner. Through both qualitative and quantitative comparisons with state-of-the-art editing methods, we show that our approach yields competitive results. This insight may open opportunities for applying this method to various tasks, including image and video editing, providing a lightweight and efficient approach for disentangled editing.
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models
Mar 28, 2024



The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models
Dec 08, 2023Generative models have been very popular in the recent years for their image generation capabilities. GAN-based models are highly regarded for their disentangled latent space, which is a key feature contributing to their success in controlled image editing. On the other hand, diffusion models have emerged as powerful tools for generating high-quality images. However, the latent space of diffusion models is not as thoroughly explored or understood. Existing methods that aim to explore the latent space of diffusion models usually relies on text prompts to pinpoint specific semantics. However, this approach may be restrictive in areas such as art, fashion, or specialized fields like medicine, where suitable text prompts might not be available or easy to conceive thus limiting the scope of existing work. In this paper, we propose an unsupervised method to discover latent semantics in text-to-image diffusion models without relying on text prompts. Our method takes a small set of unlabeled images from specific domains, such as faces or cats, and a pre-trained diffusion model, and discovers diverse semantics in unsupervised fashion using a contrastive learning objective. Moreover, the learned directions can be applied simultaneously, either within the same domain (such as various types of facial edits) or across different domains (such as applying cat and face edits within the same image) without interfering with each other. Our extensive experiments show that our method achieves highly disentangled edits, outperforming existing approaches in both diffusion-based and GAN-based latent space editing methods.
Refining 3D Human Texture Estimation from a Single Image
Mar 06, 2023
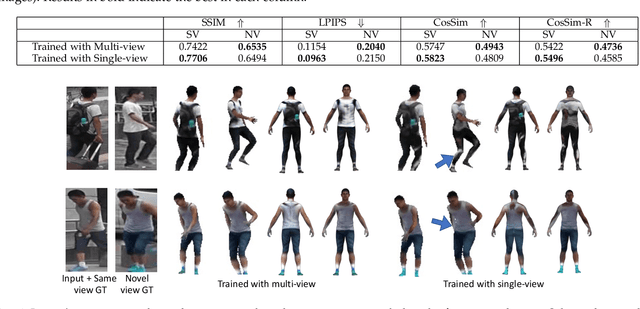
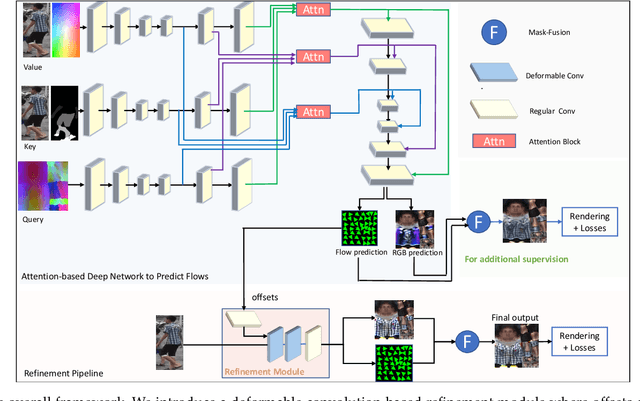
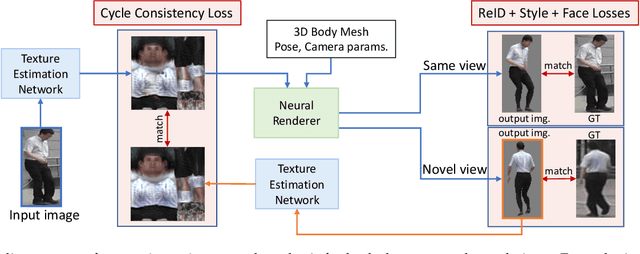
Estimating 3D human texture from a single image is essential in graphics and vision. It requires learning a mapping function from input images of humans with diverse poses into the parametric (UV) space and reasonably hallucinating invisible parts. To achieve a high-quality 3D human texture estimation, we propose a framework that adaptively samples the input by a deformable convolution where offsets are learned via a deep neural network. Additionally, we describe a novel cycle consistency loss that improves view generalization. We further propose to train our framework with an uncertainty-based pixel-level image reconstruction loss, which enhances color fidelity. We compare our method against the state-of-the-art approaches and show significant qualitative and quantitative improvements.
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023
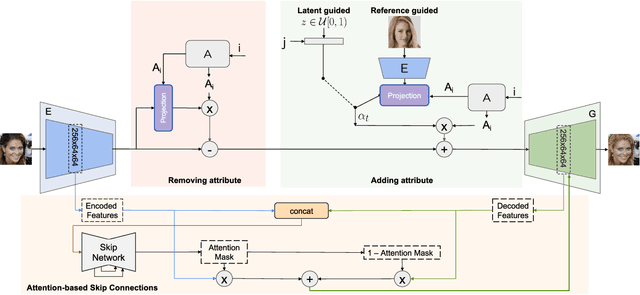
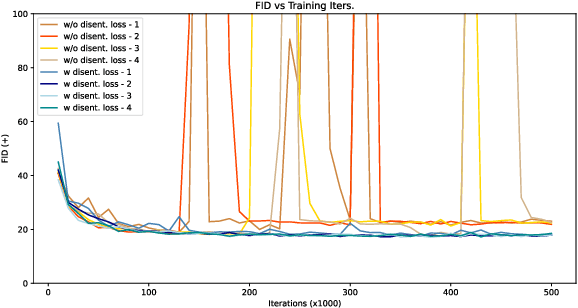

We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan