 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond-order Optimization of Gaussian Splats with Importance Sampling
Apr 17, 2025



3D Gaussian Splatting (3DGS) is widely used for novel view synthesis due to its high rendering quality and fast inference time. However, 3DGS predominantly relies on first-order optimizers such as Adam, which leads to long training times. To address this limitation, we propose a novel second-order optimization strategy based on Levenberg-Marquardt (LM) and Conjugate Gradient (CG), which we specifically tailor towards Gaussian Splatting. Our key insight is that the Jacobian in 3DGS exhibits significant sparsity since each Gaussian affects only a limited number of pixels. We exploit this sparsity by proposing a matrix-free and GPU-parallelized LM optimization. To further improve its efficiency, we propose sampling strategies for both the camera views and loss function and, consequently, the normal equation, significantly reducing the computational complexity. In addition, we increase the convergence rate of the second-order approximation by introducing an effective heuristic to determine the learning rate that avoids the expensive computation cost of line search methods. As a result, our method achieves a $3\times$ speedup over standard LM and outperforms Adam by $~6\times$ when the Gaussian count is low while remaining competitive for moderate counts. Project Page: https://vcai.mpi-inf.mpg.de/projects/LM-IS
Warping the Residuals for Image Editing with StyleGAN
Dec 18, 2023
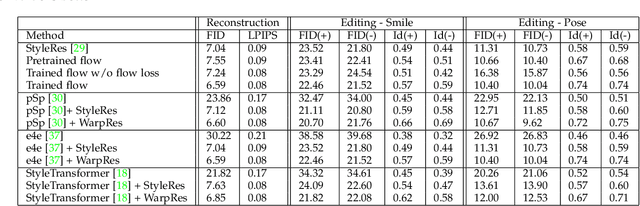
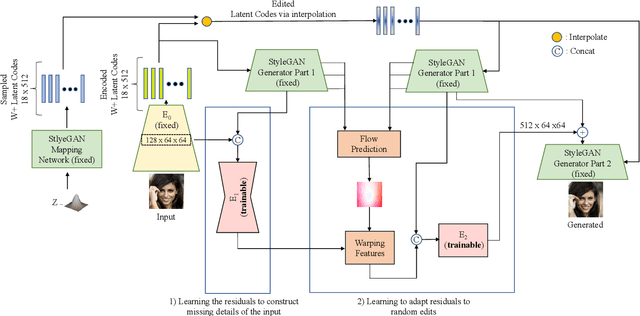
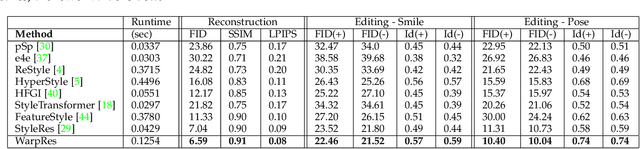
StyleGAN models show editing capabilities via their semantically interpretable latent organizations which require successful GAN inversion methods to edit real images. Many works have been proposed for inverting images into StyleGAN's latent space. However, their results either suffer from low fidelity to the input image or poor editing qualities, especially for edits that require large transformations. That is because low-rate latent spaces lose many image details due to the information bottleneck even though it provides an editable space. On the other hand, higher-rate latent spaces can pass all the image details to StyleGAN for perfect reconstruction of images but suffer from low editing qualities. In this work, we present a novel image inversion architecture that extracts high-rate latent features and includes a flow estimation module to warp these features to adapt them to edits. The flows are estimated from StyleGAN features of edited and unedited latent codes. By estimating the high-rate features and warping them for edits, we achieve both high-fidelity to the input image and high-quality edits. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements.
Diverse Inpainting and Editing with GAN Inversion
Jul 27, 2023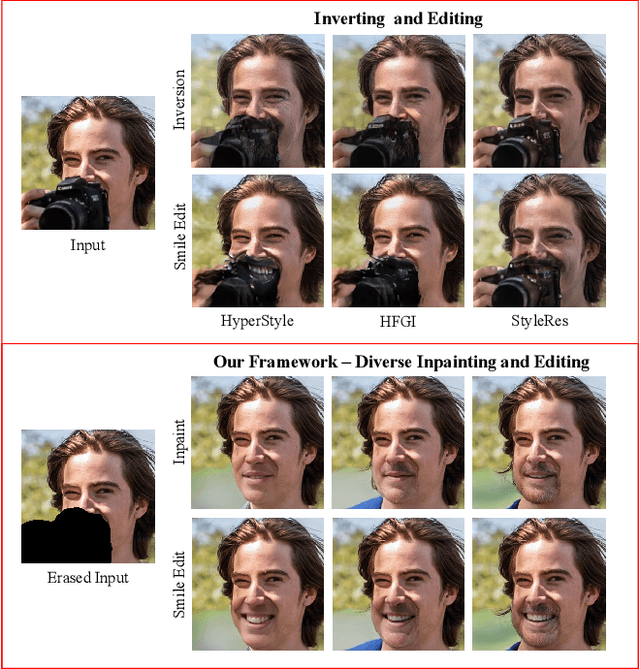
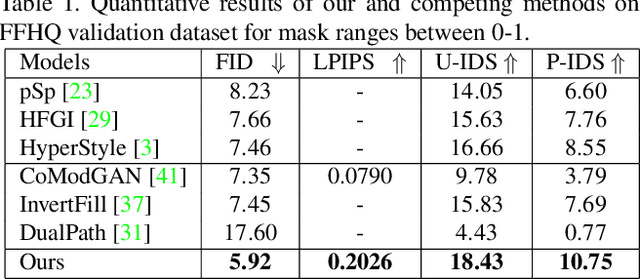
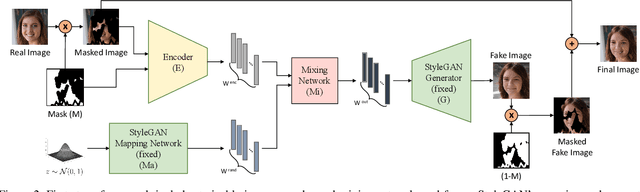
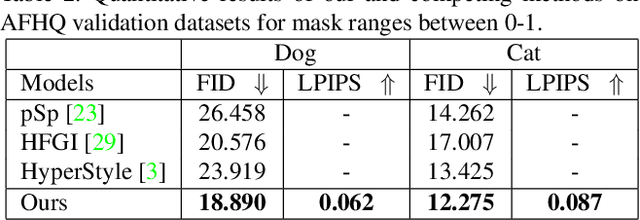
Recent inversion methods have shown that real images can be inverted into StyleGAN's latent space and numerous edits can be achieved on those images thanks to the semantically rich feature representations of well-trained GAN models. However, extensive research has also shown that image inversion is challenging due to the trade-off between high-fidelity reconstruction and editability. In this paper, we tackle an even more difficult task, inverting erased images into GAN's latent space for realistic inpaintings and editings. Furthermore, by augmenting inverted latent codes with different latent samples, we achieve diverse inpaintings. Specifically, we propose to learn an encoder and mixing network to combine encoded features from erased images with StyleGAN's mapped features from random samples. To encourage the mixing network to utilize both inputs, we train the networks with generated data via a novel set-up. We also utilize higher-rate features to prevent color inconsistencies between the inpainted and unerased parts. We run extensive experiments and compare our method with state-of-the-art inversion and inpainting methods. Qualitative metrics and visual comparisons show significant improvements.
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023
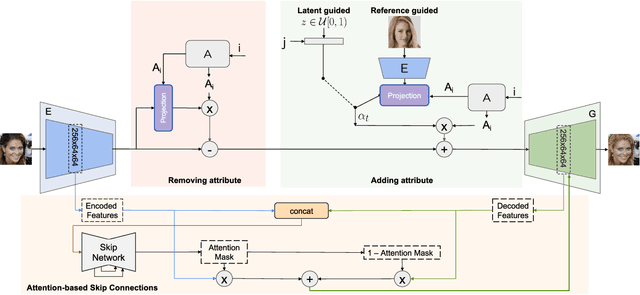
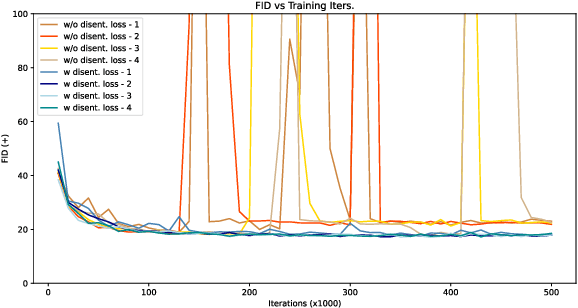

We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan
StyleRes: Transforming the Residuals for Real Image Editing with StyleGAN
Dec 29, 2022We present a novel image inversion framework and a training pipeline to achieve high-fidelity image inversion with high-quality attribute editing. Inverting real images into StyleGAN's latent space is an extensively studied problem, yet the trade-off between the image reconstruction fidelity and image editing quality remains an open challenge. The low-rate latent spaces are limited in their expressiveness power for high-fidelity reconstruction. On the other hand, high-rate latent spaces result in degradation in editing quality. In this work, to achieve high-fidelity inversion, we learn residual features in higher latent codes that lower latent codes were not able to encode. This enables preserving image details in reconstruction. To achieve high-quality editing, we learn how to transform the residual features for adapting to manipulations in latent codes. We train the framework to extract residual features and transform them via a novel architecture pipeline and cycle consistency losses. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements. Code: https://github.com/hamzapehlivan/StyleRes