 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFusionLRM: Geometry-Aware Self-Correction for Consistent 3D Reconstruction
Feb 15, 2026Single-image 3D reconstruction with large reconstruction models (LRMs) has advanced rapidly, yet reconstructions often exhibit geometric inconsistencies and misaligned details that limit fidelity. We introduce GeoFusionLRM, a geometry-aware self-correction framework that leverages the model's own normal and depth predictions to refine structural accuracy. Unlike prior approaches that rely solely on features extracted from the input image, GeoFusionLRM feeds back geometric cues through a dedicated transformer and fusion module, enabling the model to correct errors and enforce consistency with the conditioning image. This design improves the alignment between the reconstructed mesh and the input views without additional supervision or external signals. Extensive experiments demonstrate that GeoFusionLRM achieves sharper geometry, more consistent normals, and higher fidelity than state-of-the-art LRM baselines.
MD-ProjTex: Texturing 3D Shapes with Multi-Diffusion Projection
Apr 03, 2025We introduce MD-ProjTex, a method for fast and consistent text-guided texture generation for 3D shapes using pretrained text-to-image diffusion models. At the core of our approach is a multi-view consistency mechanism in UV space, which ensures coherent textures across different viewpoints. Specifically, MD-ProjTex fuses noise predictions from multiple views at each diffusion step and jointly updates the per-view denoising directions to maintain 3D consistency. In contrast to existing state-of-the-art methods that rely on optimization or sequential view synthesis, MD-ProjTex is computationally more efficient and achieves better quantitative and qualitative results.
CLIPAway: Harmonizing Focused Embeddings for Removing Objects via Diffusion Models
Jun 13, 2024
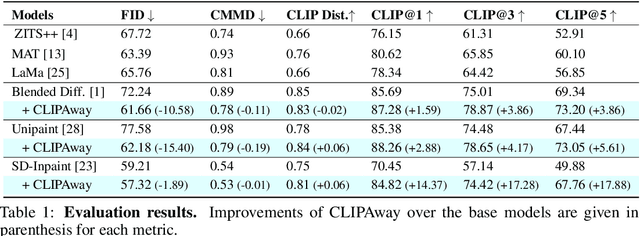


Advanced image editing techniques, particularly inpainting, are essential for seamlessly removing unwanted elements while preserving visual integrity. Traditional GAN-based methods have achieved notable success, but recent advancements in diffusion models have produced superior results due to their training on large-scale datasets, enabling the generation of remarkably realistic inpainted images. Despite their strengths, diffusion models often struggle with object removal tasks without explicit guidance, leading to unintended hallucinations of the removed object. To address this issue, we introduce CLIPAway, a novel approach leveraging CLIP embeddings to focus on background regions while excluding foreground elements. CLIPAway enhances inpainting accuracy and quality by identifying embeddings that prioritize the background, thus achieving seamless object removal. Unlike other methods that rely on specialized training datasets or costly manual annotations, CLIPAway provides a flexible, plug-and-play solution compatible with various diffusion-based inpainting techniques.
Warping the Residuals for Image Editing with StyleGAN
Dec 18, 2023
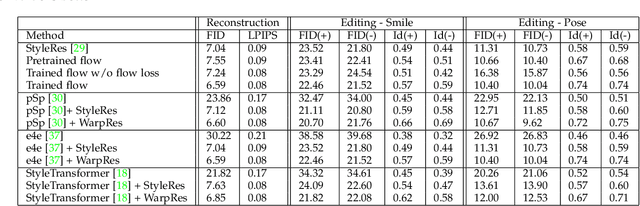
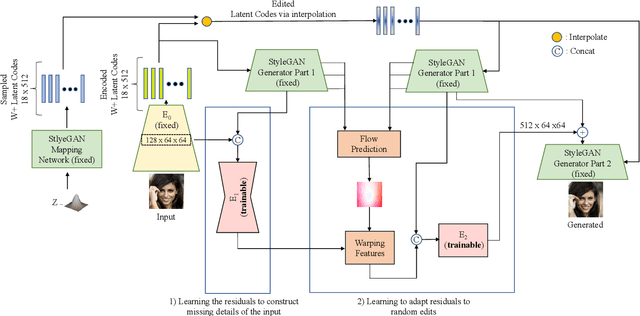
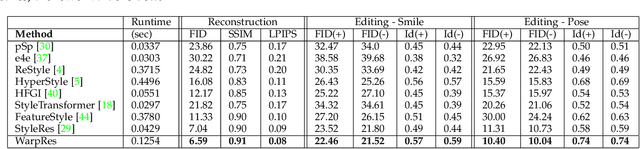
StyleGAN models show editing capabilities via their semantically interpretable latent organizations which require successful GAN inversion methods to edit real images. Many works have been proposed for inverting images into StyleGAN's latent space. However, their results either suffer from low fidelity to the input image or poor editing qualities, especially for edits that require large transformations. That is because low-rate latent spaces lose many image details due to the information bottleneck even though it provides an editable space. On the other hand, higher-rate latent spaces can pass all the image details to StyleGAN for perfect reconstruction of images but suffer from low editing qualities. In this work, we present a novel image inversion architecture that extracts high-rate latent features and includes a flow estimation module to warp these features to adapt them to edits. The flows are estimated from StyleGAN features of edited and unedited latent codes. By estimating the high-rate features and warping them for edits, we achieve both high-fidelity to the input image and high-quality edits. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements.
Diverse Inpainting and Editing with GAN Inversion
Jul 27, 2023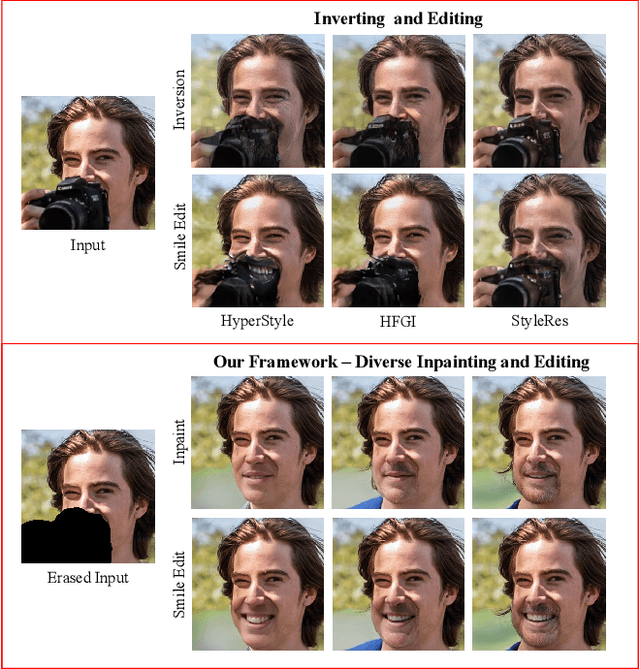
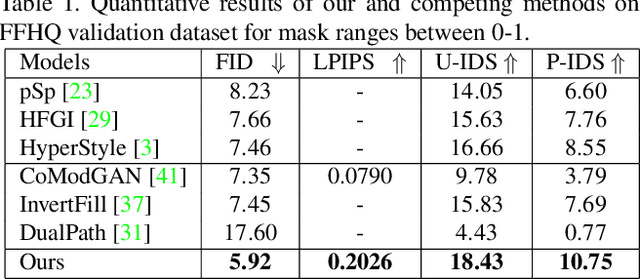
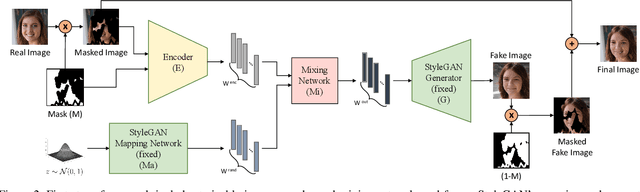
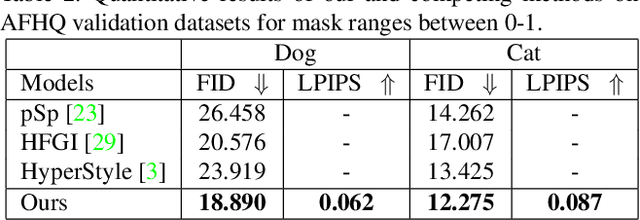
Recent inversion methods have shown that real images can be inverted into StyleGAN's latent space and numerous edits can be achieved on those images thanks to the semantically rich feature representations of well-trained GAN models. However, extensive research has also shown that image inversion is challenging due to the trade-off between high-fidelity reconstruction and editability. In this paper, we tackle an even more difficult task, inverting erased images into GAN's latent space for realistic inpaintings and editings. Furthermore, by augmenting inverted latent codes with different latent samples, we achieve diverse inpaintings. Specifically, we propose to learn an encoder and mixing network to combine encoded features from erased images with StyleGAN's mapped features from random samples. To encourage the mixing network to utilize both inputs, we train the networks with generated data via a novel set-up. We also utilize higher-rate features to prevent color inconsistencies between the inpainted and unerased parts. We run extensive experiments and compare our method with state-of-the-art inversion and inpainting methods. Qualitative metrics and visual comparisons show significant improvements.
Inst-Inpaint: Instructing to Remove Objects with Diffusion Models
Apr 06, 2023



Image inpainting task refers to erasing unwanted pixels from images and filling them in a semantically consistent and realistic way. Traditionally, the pixels that are wished to be erased are defined with binary masks. From the application point of view, a user needs to generate the masks for the objects they would like to remove which can be time-consuming and prone to errors. In this work, we are interested in an image inpainting algorithm that estimates which object to be removed based on natural language input and also removes it, simultaneously. For this purpose, first, we construct a dataset named GQA-Inpaint for this task which will be released soon. Second, we present a novel inpainting framework, Inst-Inpaint, that can remove objects from images based on the instructions given as text prompts. We set various GAN and diffusion-based baselines and run experiments on synthetic and real image datasets. We compare methods with different evaluation metrics that measure the quality and accuracy of the models and show significant quantitative and qualitative improvements.