 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining 3D Human Texture Estimation from a Single Image
Mar 06, 2023
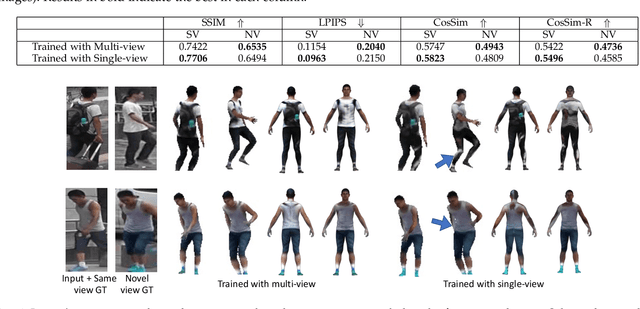
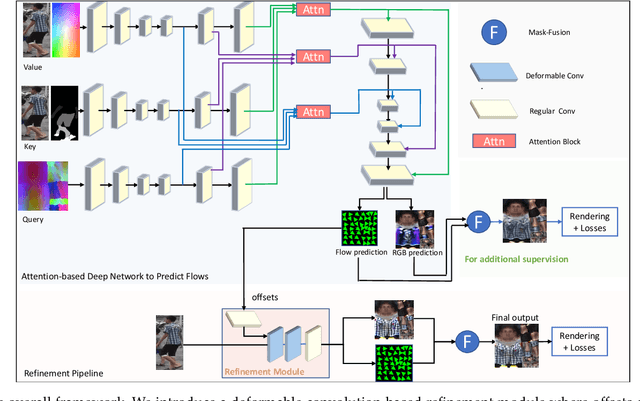
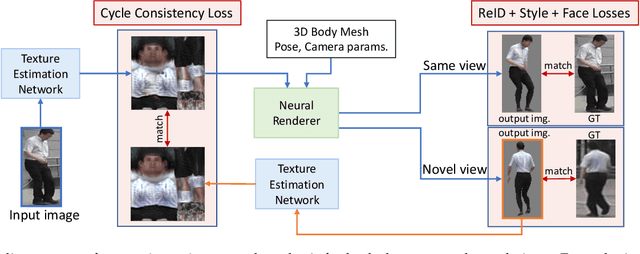
Estimating 3D human texture from a single image is essential in graphics and vision. It requires learning a mapping function from input images of humans with diverse poses into the parametric (UV) space and reasonably hallucinating invisible parts. To achieve a high-quality 3D human texture estimation, we propose a framework that adaptively samples the input by a deformable convolution where offsets are learned via a deep neural network. Additionally, we describe a novel cycle consistency loss that improves view generalization. We further propose to train our framework with an uncertainty-based pixel-level image reconstruction loss, which enhances color fidelity. We compare our method against the state-of-the-art approaches and show significant qualitative and quantitative improvements.
VecGAN: Image-to-Image Translation with Interpretable Latent Directions
Jul 07, 2022

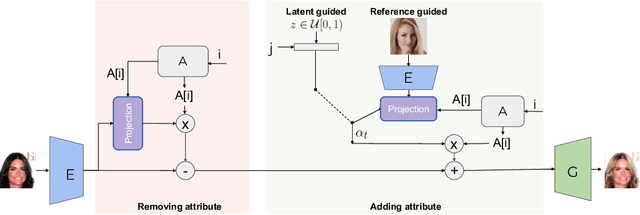

We propose VecGAN, an image-to-image translation framework for facial attribute editing with interpretable latent directions. Facial attribute editing task faces the challenges of precise attribute editing with controllable strength and preservation of the other attributes of an image. For this goal, we design the attribute editing by latent space factorization and for each attribute, we learn a linear direction that is orthogonal to the others. The other component is the controllable strength of the change, a scalar value. In our framework, this scalar can be either sampled or encoded from a reference image by projection. Our work is inspired by the latent space factorization works of fixed pretrained GANs. However, while those models cannot be trained end-to-end and struggle to edit encoded images precisely, VecGAN is end-to-end trained for image translation task and successful at editing an attribute while preserving the others. Our extensive experiments show that VecGAN achieves significant improvements over state-of-the-arts for both local and global edits.
Benchmarking the Robustness of Instance Segmentation Models
Sep 02, 2021
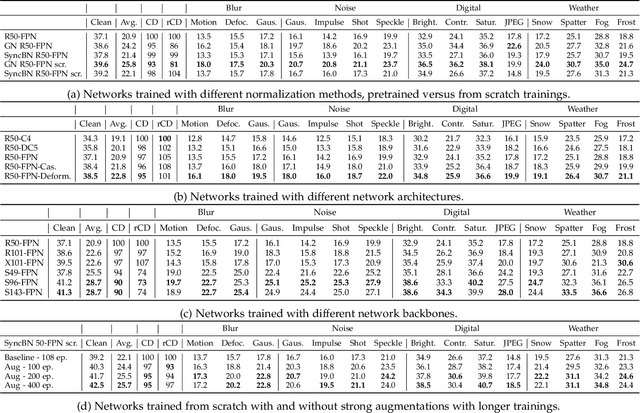

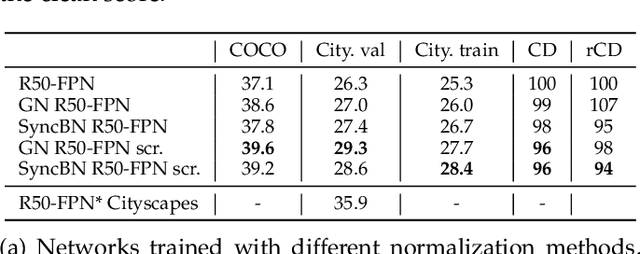
This paper presents a comprehensive evaluation of instance segmentation models with respect to real-world image corruptions and out-of-domain image collections, e.g. datasets collected with different set-ups than the training datasets the models learned from. The out-of-domain image evaluation shows the generalization capability of models, an essential aspect of real-world applications, and an extensively studied topic of domain adaptation. These presented robustness and generalization evaluations are important when designing instance segmentation models for real-world applications and picking an off-the-shelf pretrained model to directly use for the task at hand. Specifically, this benchmark study includes state-of-the-art network architectures, network backbones, normalization layers, models trained starting from scratch or ImageNet pretrained networks, and the effect of multi-task training on robustness and generalization. Through this study, we gain several insights e.g. we find that normalization layers play an essential role in robustness, ImageNet pretraining does not help the robustness and the generalization of models, excluding JPEG corruption, and network backbones and copy-paste augmentations affect robustness significantly.