 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining 3D Human Texture Estimation from a Single Image
Paper and Code

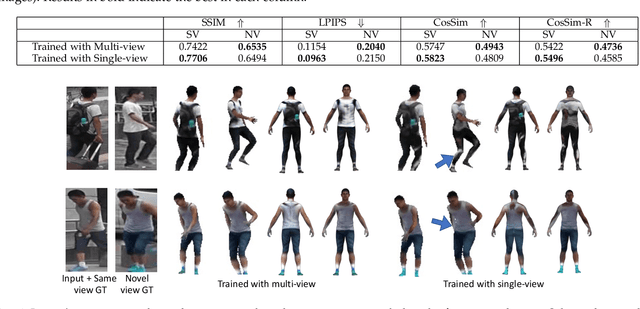
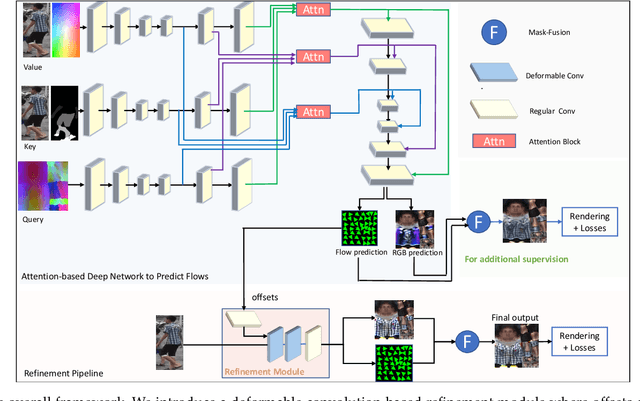
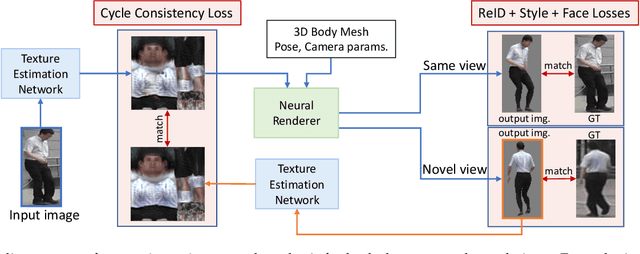
Estimating 3D human texture from a single image is essential in graphics and vision. It requires learning a mapping function from input images of humans with diverse poses into the parametric (UV) space and reasonably hallucinating invisible parts. To achieve a high-quality 3D human texture estimation, we propose a framework that adaptively samples the input by a deformable convolution where offsets are learned via a deep neural network. Additionally, we describe a novel cycle consistency loss that improves view generalization. We further propose to train our framework with an uncertainty-based pixel-level image reconstruction loss, which enhances color fidelity. We compare our method against the state-of-the-art approaches and show significant qualitative and quantitative improvements.