 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTG-Restore: Training-Free Diffusion Refinement for Generative Video Super-Resolution
May 28, 2026Recent progress in video diffusion models has enabled remarkable generative fidelity, yet leveraging these priors for restoration remains limited by the strong coupling between conditional and unconditional branches in standard classifier-free guidance. We introduce a training-free framework that enhances distorted and low-resolution videos by decoupling these signals in time. Our proposed Decoupled Time Guidance (DTG) evaluates the unconditional branch at a cleaner diffusion timestep, providing a lookahead prior that preserves geometry while suppressing replication of warped content. This temporal bias is annealed throughout sampling, allowing the model to transition from structure correction to detail refinement without retraining. Combined with any off-the-shelf restoration module in a plug-and-play manner, our approach improves perceptual coherence and restores plausible structure in AIgenerated and real-world videos alike. To facilitate evaluation, we curate GenWarp480, a benchmark of 4,400 distorted 480p videos synthesized from diverse text-to-video models. GenWarp480 focuses on characteristic generative degradations such as warped faces, body misalignments, and spatial artifacts, providing a purpose-built testbed for assessing robustness to generative errors. Extensive experiments demonstrate that our method achieves significant improvements in structural fidelity and temporal stability without any model training.
VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
May 28, 2026Long-rollout causal video diffusion has converged on a fixed-size sliding-window KV cache, with recent progress innovating within this layout by changing which tokens occupy the window or how their positions are encoded. The per-head KV layout itself, a dominant contributor to streaming memory and latency, has been mostly left unchanged. In this paper, we present the first study of Multi-Head Latent Attention (MLA) in video diffusion. VideoMLA replaces per-head keys and values with a shared low-rank content latent and a shared decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% at every cached layer. We further investigate why MLA succeeds in video diffusion even though the spectral assumption often used to motivate it in language models does not hold: pretrained video attention is not low-rank, with 99%-energy effective rank far above any practical latent dimension. VideoMLA retains quality at compression ratios where direct spectral approximation would predict large reconstruction error. We show that the MLA bottleneck, rather than the pretrained spectrum, determines the effective rank: both spectral and random initialization occupy nearly the full rank budget from initialization, and training preserves this budget while adapting within it. On VBench, VideoMLA matches short-horizon streaming video diffusion baselines, achieves the best overall score at long horizons among evaluated methods, and improves throughput by 1.23x on a single B200.
Aligning Latent Geometry for Spherical Flow Matching in Image Generation
May 14, 2026Latent flow matching for image generation usually transports Gaussian noise to variational autoencoder latents along linear paths. Both endpoints, however, concentrate in thin spherical shells, and a Euclidean chord leaves those shells even when preprocessing aligns their radii. By decomposing each latent token into radial and angular components, we show through component-swap probes that decoded perceptual and semantic content is carried predominantly by direction, with radius contributing much less. We therefore project data latents onto a fixed token radius, use the radial projection of Gaussian noise as the spherical prior, finetune the decoder with the encoder frozen, and replace linear interpolation with spherical linear interpolation. The resulting geodesic paths stay on the sphere at every timestep, and their velocity targets are purely angular by construction. Under matched training, the method consistently improves class-conditional ImageNet-256 FID across different image tokenizers, leaves the diffusion architecture unchanged, and requires no auxiliary encoder or representation-alignment objective.
Dynamic View Synthesis as an Inverse Problem
Jun 09, 2025



In this work, we address dynamic view synthesis from monocular videos as an inverse problem in a training-free setting. By redesigning the noise initialization phase of a pre-trained video diffusion model, we enable high-fidelity dynamic view synthesis without any weight updates or auxiliary modules. We begin by identifying a fundamental obstacle to deterministic inversion arising from zero-terminal signal-to-noise ratio (SNR) schedules and resolve it by introducing a novel noise representation, termed K-order Recursive Noise Representation. We derive a closed form expression for this representation, enabling precise and efficient alignment between the VAE-encoded and the DDIM inverted latents. To synthesize newly visible regions resulting from camera motion, we introduce Stochastic Latent Modulation, which performs visibility aware sampling over the latent space to complete occluded regions. Comprehensive experiments demonstrate that dynamic view synthesis can be effectively performed through structured latent manipulation in the noise initialization phase.
LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers
May 29, 2025We introduce LoRAShop, the first framework for multi-concept image editing with LoRA models. LoRAShop builds on a key observation about the feature interaction patterns inside Flux-style diffusion transformers: concept-specific transformer features activate spatially coherent regions early in the denoising process. We harness this observation to derive a disentangled latent mask for each concept in a prior forward pass and blend the corresponding LoRA weights only within regions bounding the concepts to be personalized. The resulting edits seamlessly integrate multiple subjects or styles into the original scene while preserving global context, lighting, and fine details. Our experiments demonstrate that LoRAShop delivers better identity preservation compared to baselines. By eliminating retraining and external constraints, LoRAShop turns personalized diffusion models into a practical `photoshop-with-LoRAs' tool and opens new avenues for compositional visual storytelling and rapid creative iteration.
MotionShop: Zero-Shot Motion Transfer in Video Diffusion Models with Mixture of Score Guidance
Dec 06, 2024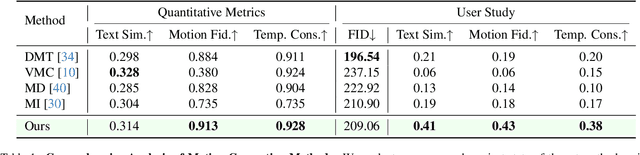


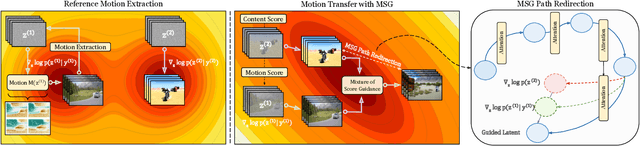
In this work, we propose the first motion transfer approach in diffusion transformer through Mixture of Score Guidance (MSG), a theoretically-grounded framework for motion transfer in diffusion models. Our key theoretical contribution lies in reformulating conditional score to decompose motion score and content score in diffusion models. By formulating motion transfer as a mixture of potential energies, MSG naturally preserves scene composition and enables creative scene transformations while maintaining the integrity of transferred motion patterns. This novel sampling operates directly on pre-trained video diffusion models without additional training or fine-tuning. Through extensive experiments, MSG demonstrates successful handling of diverse scenarios including single object, multiple objects, and cross-object motion transfer as well as complex camera motion transfer. Additionally, we introduce MotionBench, the first motion transfer dataset consisting of 200 source videos and 1000 transferred motions, covering single/multi-object transfers, and complex camera motions.
MotionFlow: Attention-Driven Motion Transfer in Video Diffusion Models
Dec 06, 2024Text-to-video models have demonstrated impressive capabilities in producing diverse and captivating video content, showcasing a notable advancement in generative AI. However, these models generally lack fine-grained control over motion patterns, limiting their practical applicability. We introduce MotionFlow, a novel framework designed for motion transfer in video diffusion models. Our method utilizes cross-attention maps to accurately capture and manipulate spatial and temporal dynamics, enabling seamless motion transfers across various contexts. Our approach does not require training and works on test-time by leveraging the inherent capabilities of pre-trained video diffusion models. In contrast to traditional approaches, which struggle with comprehensive scene changes while maintaining consistent motion, MotionFlow successfully handles such complex transformations through its attention-based mechanism. Our qualitative and quantitative experiments demonstrate that MotionFlow significantly outperforms existing models in both fidelity and versatility even during drastic scene alterations.
Stylebreeder: Exploring and Democratizing Artistic Styles through Text-to-Image Models
Jun 20, 2024


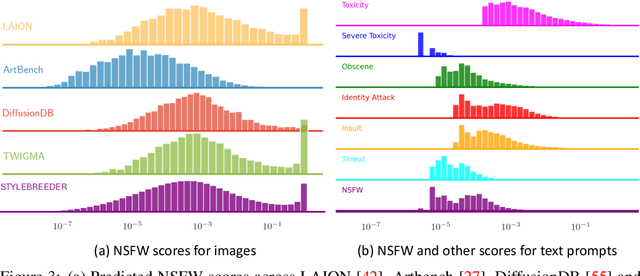
Text-to-image models are becoming increasingly popular, revolutionizing the landscape of digital art creation by enabling highly detailed and creative visual content generation. These models have been widely employed across various domains, particularly in art generation, where they facilitate a broad spectrum of creative expression and democratize access to artistic creation. In this paper, we introduce \texttt{STYLEBREEDER}, a comprehensive dataset of 6.8M images and 1.8M prompts generated by 95K users on Artbreeder, a platform that has emerged as a significant hub for creative exploration with over 13M users. We introduce a series of tasks with this dataset aimed at identifying diverse artistic styles, generating personalized content, and recommending styles based on user interests. By documenting unique, user-generated styles that transcend conventional categories like 'cyberpunk' or 'Picasso,' we explore the potential for unique, crowd-sourced styles that could provide deep insights into the collective creative psyche of users worldwide. We also evaluate different personalization methods to enhance artistic expression and introduce a style atlas, making these models available in LoRA format for public use. Our research demonstrates the potential of text-to-image diffusion models to uncover and promote unique artistic expressions, further democratizing AI in art and fostering a more diverse and inclusive artistic community. The dataset, code and models are available at https://stylebreeder.github.io under a Public Domain (CC0) license.
The Curious Case of End Token: A Zero-Shot Disentangled Image Editing using CLIP
Jun 01, 2024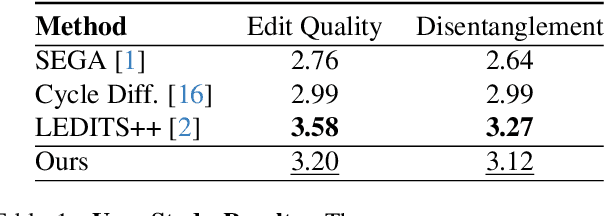
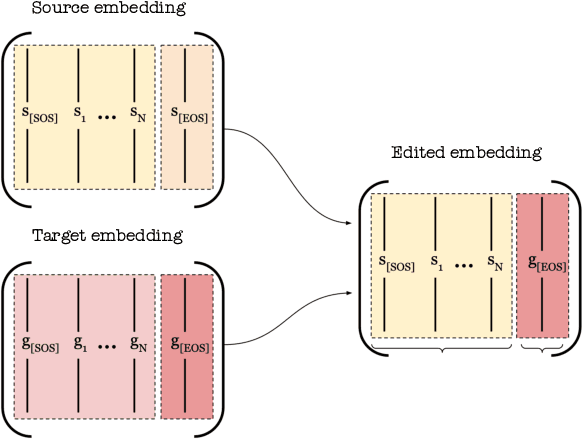


Diffusion models have become prominent in creating high-quality images. However, unlike GAN models celebrated for their ability to edit images in a disentangled manner, diffusion-based text-to-image models struggle to achieve the same level of precise attribute manipulation without compromising image coherence. In this paper, CLIP which is often used in popular text-to-image diffusion models such as Stable Diffusion is capable of performing disentangled editing in a zero-shot manner. Through both qualitative and quantitative comparisons with state-of-the-art editing methods, we show that our approach yields competitive results. This insight may open opportunities for applying this method to various tasks, including image and video editing, providing a lightweight and efficient approach for disentangled editing.
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models
Mar 28, 2024



The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.