 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Zero to Hero: Training-Free Custom Concept Spawning in World Models
Jun 01, 2026Autoregressive world models have emerged as a powerful paradigm for interactive video generation, allowing users to navigate dynamically generated environments through actions. These models are typically conditioned on a text prompt and/or a single reference frame, from which the entire world is generated. Yet the moment the user navigates beyond what is visible in that frame, the unseen regions are populated by the base model's priors, with no mechanism for the user to specify what should appear and where. This is a fundamental limitation for applications such as gaming, interactive storytelling, and simulation, where controllable scene composition is essential. We refer to this missing capability as concept spawning; introducing a user-specified visual concept into a world model, analogous to spawning in a game engine. We introduce SPAWN (Swapping Pinned Anchor with Windowed iNjection), a training-free method for concept spawning. SPAWN exploits a structural property of image-to-video backbones: the first slot of the context memory is pinned to the reference frame and acts as a foundational anchor for every generated chunk. By swapping this anchor with an external concept latent over a short injection window and letting the original anchor return, we cause the concept to propagate naturally through the rollout via the model's own memory. SPAWN supports concepts from fine-grained entities such as characters and props to large-scale elements such as buildings and landmarks, and accepts either a concept image or a text description as input. Experiments show that SPAWN integrates concepts with consistent lighting, scale, and perspective while preserving identity and temporal coherence, demonstrating that controllable concept spawning is achievable in existing autoregressive world models without any training.
Plot'n Polish: Zero-shot Story Visualization and Disentangled Editing with Text-to-Image Diffusion Models
Sep 04, 2025Text-to-image diffusion models have demonstrated significant capabilities to generate diverse and detailed visuals in various domains, and story visualization is emerging as a particularly promising application. However, as their use in real-world creative domains increases, the need for providing enhanced control, refinement, and the ability to modify images post-generation in a consistent manner becomes an important challenge. Existing methods often lack the flexibility to apply fine or coarse edits while maintaining visual and narrative consistency across multiple frames, preventing creators from seamlessly crafting and refining their visual stories. To address these challenges, we introduce Plot'n Polish, a zero-shot framework that enables consistent story generation and provides fine-grained control over story visualizations at various levels of detail.
Audit & Repair: An Agentic Framework for Consistent Story Visualization in Text-to-Image Diffusion Models
Jun 23, 2025Story visualization has become a popular task where visual scenes are generated to depict a narrative across multiple panels. A central challenge in this setting is maintaining visual consistency, particularly in how characters and objects persist and evolve throughout the story. Despite recent advances in diffusion models, current approaches often fail to preserve key character attributes, leading to incoherent narratives. In this work, we propose a collaborative multi-agent framework that autonomously identifies, corrects, and refines inconsistencies across multi-panel story visualizations. The agents operate in an iterative loop, enabling fine-grained, panel-level updates without re-generating entire sequences. Our framework is model-agnostic and flexibly integrates with a variety of diffusion models, including rectified flow transformers such as Flux and latent diffusion models such as Stable Diffusion. Quantitative and qualitative experiments show that our method outperforms prior approaches in terms of multi-panel consistency.
ORACLE: Leveraging Mutual Information for Consistent Character Generation with LoRAs in Diffusion Models
Jun 04, 2024
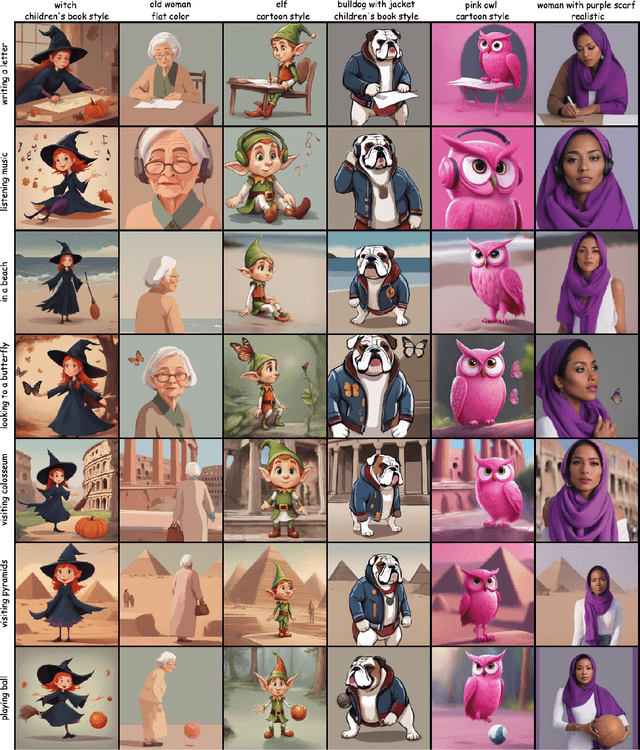
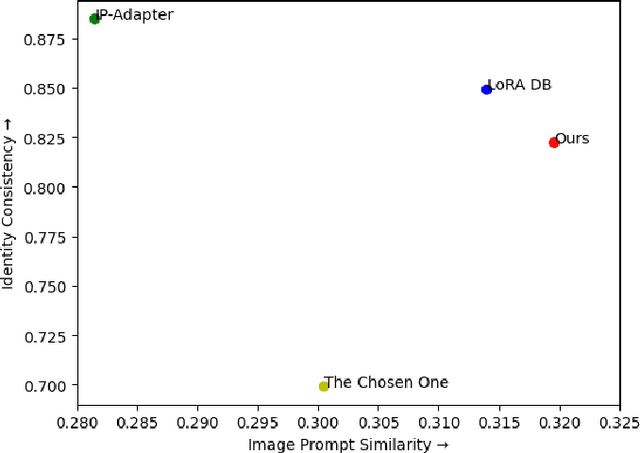
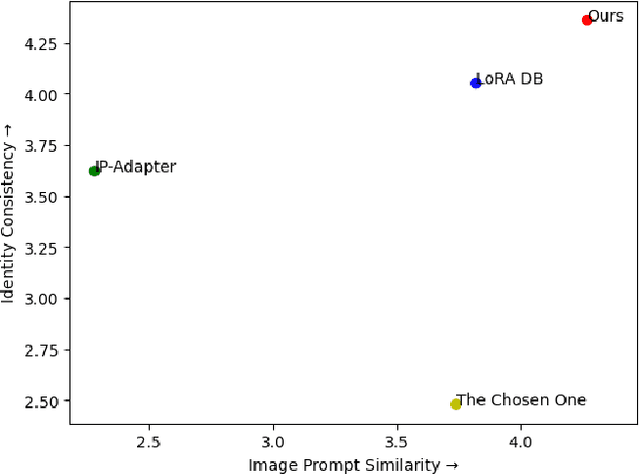
Text-to-image diffusion models have recently taken center stage as pivotal tools in promoting visual creativity across an array of domains such as comic book artistry, children's literature, game development, and web design. These models harness the power of artificial intelligence to convert textual descriptions into vivid images, thereby enabling artists and creators to bring their imaginative concepts to life with unprecedented ease. However, one of the significant hurdles that persist is the challenge of maintaining consistency in character generation across diverse contexts. Variations in textual prompts, even if minor, can yield vastly different visual outputs, posing a considerable problem in projects that require a uniform representation of characters throughout. In this paper, we introduce a novel framework designed to produce consistent character representations from a single text prompt across diverse settings. Through both quantitative and qualitative analyses, we demonstrate that our framework outperforms existing methods in generating characters with consistent visual identities, underscoring its potential to transform creative industries. By addressing the critical challenge of character consistency, we not only enhance the practical utility of these models but also broaden the horizons for artistic and creative expression.
MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models
Mar 28, 2024



Diffusion-based text-to-image models have rapidly gained popularity for their ability to generate detailed and realistic images from textual descriptions. However, these models often reflect the biases present in their training data, especially impacting marginalized groups. While prior efforts to debias language models have focused on addressing specific biases, such as racial or gender biases, efforts to tackle intersectional bias have been limited. Intersectional bias refers to the unique form of bias experienced by individuals at the intersection of multiple social identities. Addressing intersectional bias is crucial because it amplifies the negative effects of discrimination based on race, gender, and other identities. In this paper, we introduce a method that addresses intersectional bias in diffusion-based text-to-image models by modifying cross-attention maps in a disentangled manner. Our approach utilizes a pre-trained Stable Diffusion model, eliminates the need for an additional set of reference images, and preserves the original quality for unaltered concepts. Comprehensive experiments demonstrate that our method surpasses existing approaches in mitigating both single and intersectional biases across various attributes. We make our source code and debiased models for various attributes available to encourage fairness in generative models and to support further research.
Zero-Shot Ranking Socio-Political Texts with Transformer Language Models to Reduce Close Reading Time
Oct 17, 2022


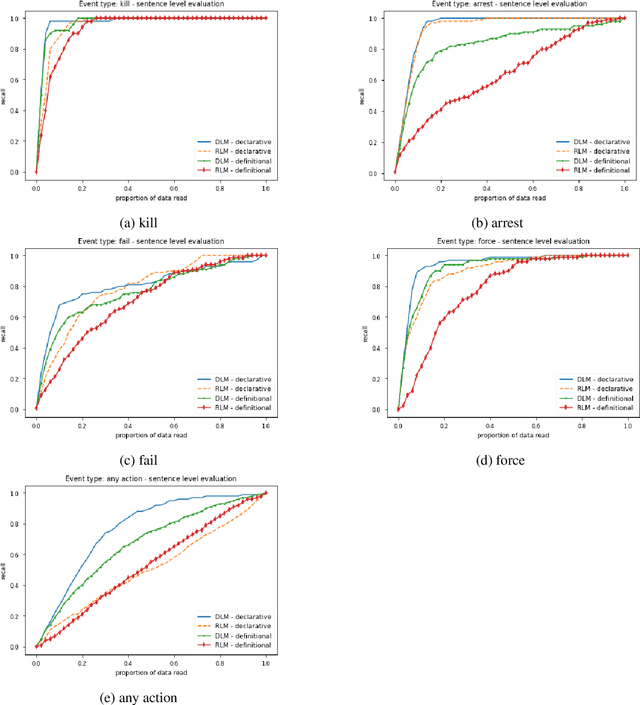
We approach the classification problem as an entailment problem and apply zero-shot ranking to socio-political texts. Documents that are ranked at the top can be considered positively classified documents and this reduces the close reading time for the information extraction process. We use Transformer Language Models to get the entailment probabilities and investigate different types of queries. We find that DeBERTa achieves higher mean average precision scores than RoBERTa and when declarative form of the class label is used as a query, it outperforms dictionary definition of the class label. We show that one can reduce the close reading time by taking some percentage of the ranked documents that the percentage depends on how much recall they want to achieve. However, our findings also show that percentage of the documents that should be read increases as the topic gets broader.