 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelenite: Scaffolding Decision Making with Comprehensive Overviews Elicited from Large Language Models
Oct 03, 2023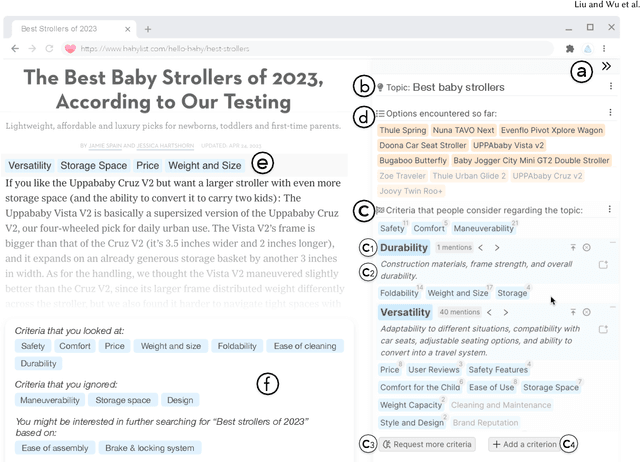



Decision-making in unfamiliar domains can be challenging, demanding considerable user effort to compare different options with respect to various criteria. Prior research and our formative study found that people would benefit from seeing an overview of the information space upfront, such as the criteria that others have previously found useful. However, existing sensemaking tools struggle with the "cold-start" problem -- it not only requires significant input from previous users to generate and share these overviews, but such overviews may also be biased and incomplete. In this work, we introduce a novel system, Selenite, which leverages LLMs as reasoning machines and knowledge retrievers to automatically produce a comprehensive overview of options and criteria to jumpstart users' sensemaking processes. Subsequently, Selenite also adapts as people use it, helping users find, read, and navigate unfamiliar information in a systematic yet personalized manner. Through three studies, we found that Selenite produced accurate and high-quality overviews reliably, significantly accelerated users' information processing, and effectively improved their overall comprehension and sensemaking experience.
Assessing the Quality of Multiple-Choice Questions Using GPT-4 and Rule-Based Methods
Jul 16, 2023Multiple-choice questions with item-writing flaws can negatively impact student learning and skew analytics. These flaws are often present in student-generated questions, making it difficult to assess their quality and suitability for classroom usage. Existing methods for evaluating multiple-choice questions often focus on machine readability metrics, without considering their intended use within course materials and their pedagogical implications. In this study, we compared the performance of a rule-based method we developed to a machine-learning based method utilizing GPT-4 for the task of automatically assessing multiple-choice questions based on 19 common item-writing flaws. By analyzing 200 student-generated questions from four different subject areas, we found that the rule-based method correctly detected 91% of the flaws identified by human annotators, as compared to 79% by GPT-4. We demonstrated the effectiveness of the two methods in identifying common item-writing flaws present in the student-generated questions across different subject areas. The rule-based method can accurately and efficiently evaluate multiple-choice questions from multiple domains, outperforming GPT-4 and going beyond existing metrics that do not account for the educational use of such questions. Finally, we discuss the potential for using these automated methods to improve the quality of questions based on the identified flaws.