 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic Question Usability Evaluation Toolkit
May 30, 2024

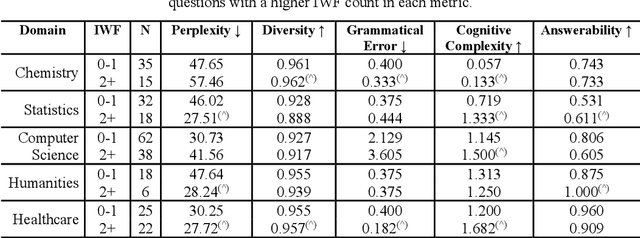
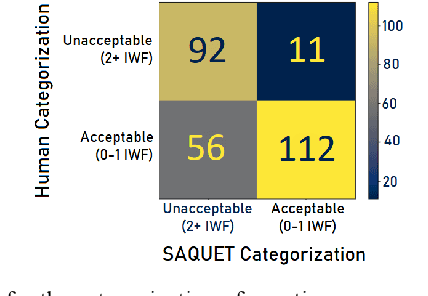
Evaluating multiple-choice questions (MCQs) involves either labor intensive human assessments or automated methods that prioritize readability, often overlooking deeper question design flaws. To address this issue, we introduce the Scalable Automatic Question Usability Evaluation Toolkit (SAQUET), an open-source tool that leverages the Item-Writing Flaws (IWF) rubric for a comprehensive and automated quality evaluation of MCQs. By harnessing the latest in large language models such as GPT-4, advanced word embeddings, and Transformers designed to analyze textual complexity, SAQUET effectively pinpoints and assesses a wide array of flaws in MCQs. We first demonstrate the discrepancy between commonly used automated evaluation metrics and the human assessment of MCQ quality. Then we evaluate SAQUET on a diverse dataset of MCQs across the five domains of Chemistry, Statistics, Computer Science, Humanities, and Healthcare, showing how it effectively distinguishes between flawed and flawless questions, providing a level of analysis beyond what is achievable with traditional metrics. With an accuracy rate of over 94% in detecting the presence of flaws identified by human evaluators, our findings emphasize the limitations of existing evaluation methods and showcase potential in improving the quality of educational assessments.
Assessing the Quality of Multiple-Choice Questions Using GPT-4 and Rule-Based Methods
Jul 16, 2023Multiple-choice questions with item-writing flaws can negatively impact student learning and skew analytics. These flaws are often present in student-generated questions, making it difficult to assess their quality and suitability for classroom usage. Existing methods for evaluating multiple-choice questions often focus on machine readability metrics, without considering their intended use within course materials and their pedagogical implications. In this study, we compared the performance of a rule-based method we developed to a machine-learning based method utilizing GPT-4 for the task of automatically assessing multiple-choice questions based on 19 common item-writing flaws. By analyzing 200 student-generated questions from four different subject areas, we found that the rule-based method correctly detected 91% of the flaws identified by human annotators, as compared to 79% by GPT-4. We demonstrated the effectiveness of the two methods in identifying common item-writing flaws present in the student-generated questions across different subject areas. The rule-based method can accurately and efficiently evaluate multiple-choice questions from multiple domains, outperforming GPT-4 and going beyond existing metrics that do not account for the educational use of such questions. Finally, we discuss the potential for using these automated methods to improve the quality of questions based on the identified flaws.
Evaluating ChatGPT's Decimal Skills and Feedback Generation in a Digital Learning Game
Jun 29, 2023



While open-ended self-explanations have been shown to promote robust learning in multiple studies, they pose significant challenges to automated grading and feedback in technology-enhanced learning, due to the unconstrained nature of the students' input. Our work investigates whether recent advances in Large Language Models, and in particular ChatGPT, can address this issue. Using decimal exercises and student data from a prior study of the learning game Decimal Point, with more than 5,000 open-ended self-explanation responses, we investigate ChatGPT's capability in (1) solving the in-game exercises, (2) determining the correctness of students' answers, and (3) providing meaningful feedback to incorrect answers. Our results showed that ChatGPT can respond well to conceptual questions, but struggled with decimal place values and number line problems. In addition, it was able to accurately assess the correctness of 75% of the students' answers and generated generally high-quality feedback, similar to human instructors. We conclude with a discussion of ChatGPT's strengths and weaknesses and suggest several venues for extending its use cases in digital teaching and learning.