 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic Question Usability Evaluation Toolkit
Paper and Code
May 30, 2024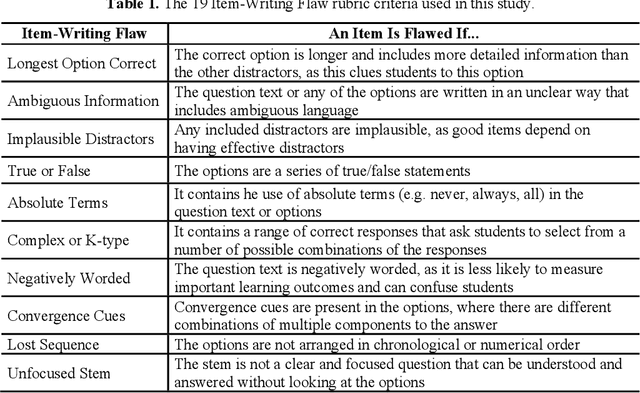

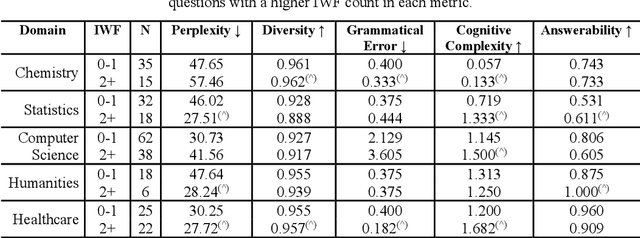
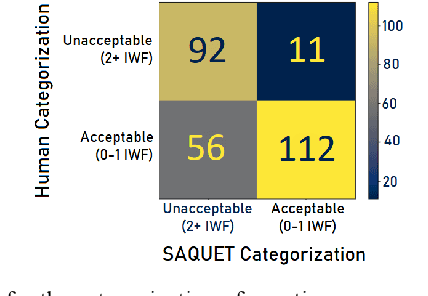
Evaluating multiple-choice questions (MCQs) involves either labor intensive human assessments or automated methods that prioritize readability, often overlooking deeper question design flaws. To address this issue, we introduce the Scalable Automatic Question Usability Evaluation Toolkit (SAQUET), an open-source tool that leverages the Item-Writing Flaws (IWF) rubric for a comprehensive and automated quality evaluation of MCQs. By harnessing the latest in large language models such as GPT-4, advanced word embeddings, and Transformers designed to analyze textual complexity, SAQUET effectively pinpoints and assesses a wide array of flaws in MCQs. We first demonstrate the discrepancy between commonly used automated evaluation metrics and the human assessment of MCQ quality. Then we evaluate SAQUET on a diverse dataset of MCQs across the five domains of Chemistry, Statistics, Computer Science, Humanities, and Healthcare, showing how it effectively distinguishes between flawed and flawless questions, providing a level of analysis beyond what is achievable with traditional metrics. With an accuracy rate of over 94% in detecting the presence of flaws identified by human evaluators, our findings emphasize the limitations of existing evaluation methods and showcase potential in improving the quality of educational assessments.