 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating ChatGPT's Decimal Skills and Feedback Generation in a Digital Learning Game
Jun 29, 2023



While open-ended self-explanations have been shown to promote robust learning in multiple studies, they pose significant challenges to automated grading and feedback in technology-enhanced learning, due to the unconstrained nature of the students' input. Our work investigates whether recent advances in Large Language Models, and in particular ChatGPT, can address this issue. Using decimal exercises and student data from a prior study of the learning game Decimal Point, with more than 5,000 open-ended self-explanation responses, we investigate ChatGPT's capability in (1) solving the in-game exercises, (2) determining the correctness of students' answers, and (3) providing meaningful feedback to incorrect answers. Our results showed that ChatGPT can respond well to conceptual questions, but struggled with decimal place values and number line problems. In addition, it was able to accurately assess the correctness of 75% of the students' answers and generated generally high-quality feedback, similar to human instructors. We conclude with a discussion of ChatGPT's strengths and weaknesses and suggest several venues for extending its use cases in digital teaching and learning.
Embed Everything: A Method for Efficiently Co-Embedding Multi-Modal Spaces
Oct 09, 2021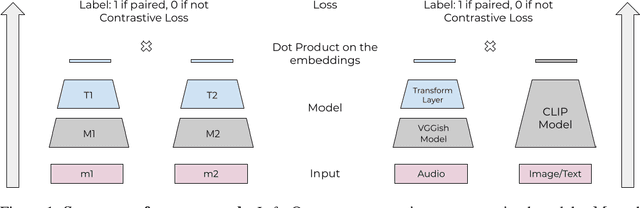
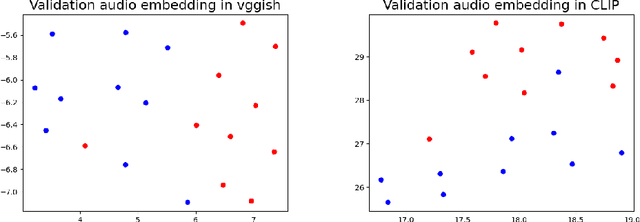
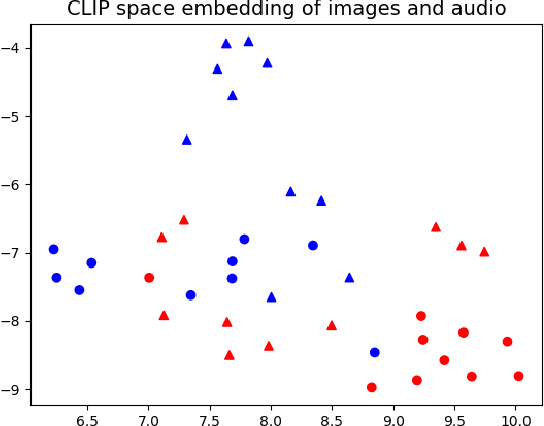
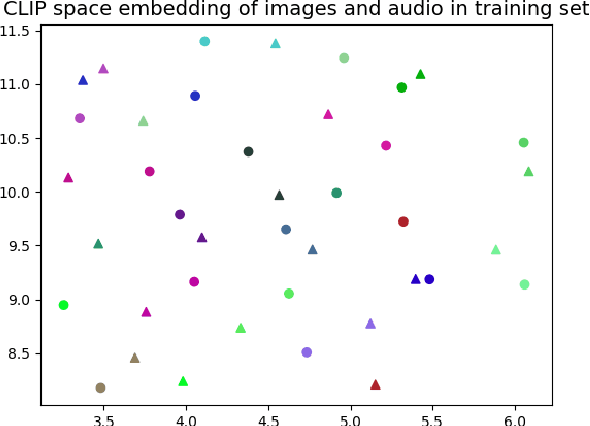
Any general artificial intelligence system must be able to interpret, operate on, and produce data in a multi-modal latent space that can represent audio, imagery, text, and more. In the last decade, deep neural networks have seen remarkable success in unimodal data distributions, while transfer learning techniques have seen a massive expansion of model reuse across related domains. However, training multi-modal networks from scratch remains expensive and illusive, while heterogeneous transfer learning (HTL) techniques remain relatively underdeveloped. In this paper, we propose a novel and cost-effective HTL strategy for co-embedding multi-modal spaces. Our method avoids cost inefficiencies by preprocessing embeddings using pretrained models for all components, without passing gradients through these models. We prove the use of this system in a joint image-audio embedding task. Our method has wide-reaching applications, as successfully bridging the gap between different latent spaces could provide a framework for the promised "universal" embedding.