 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbed Everything: A Method for Efficiently Co-Embedding Multi-Modal Spaces
Oct 09, 2021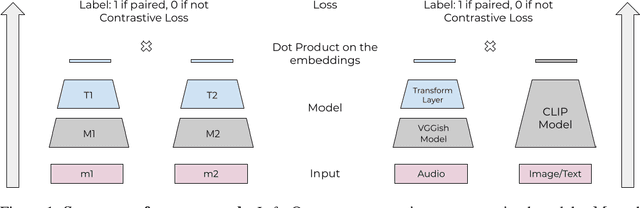
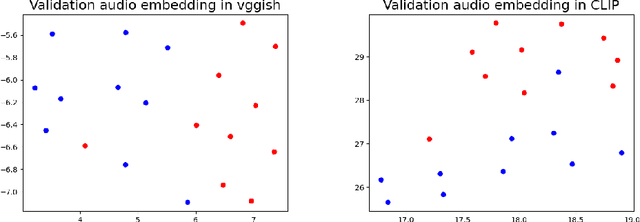
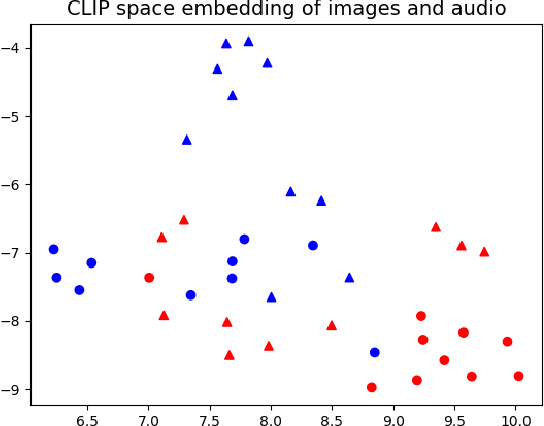
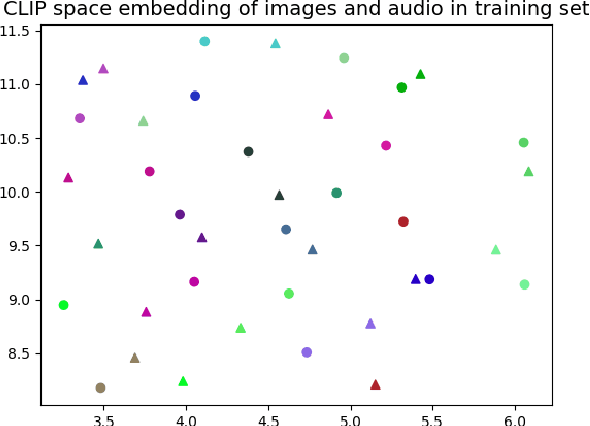
Any general artificial intelligence system must be able to interpret, operate on, and produce data in a multi-modal latent space that can represent audio, imagery, text, and more. In the last decade, deep neural networks have seen remarkable success in unimodal data distributions, while transfer learning techniques have seen a massive expansion of model reuse across related domains. However, training multi-modal networks from scratch remains expensive and illusive, while heterogeneous transfer learning (HTL) techniques remain relatively underdeveloped. In this paper, we propose a novel and cost-effective HTL strategy for co-embedding multi-modal spaces. Our method avoids cost inefficiencies by preprocessing embeddings using pretrained models for all components, without passing gradients through these models. We prove the use of this system in a joint image-audio embedding task. Our method has wide-reaching applications, as successfully bridging the gap between different latent spaces could provide a framework for the promised "universal" embedding.
Pathfinder Discovery Networks for Neural Message Passing
Oct 24, 2020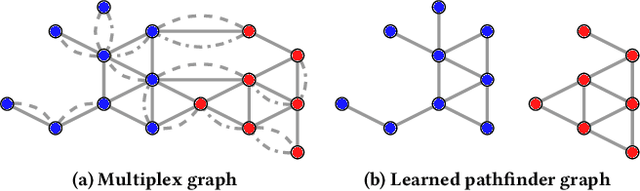
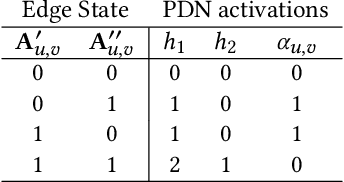
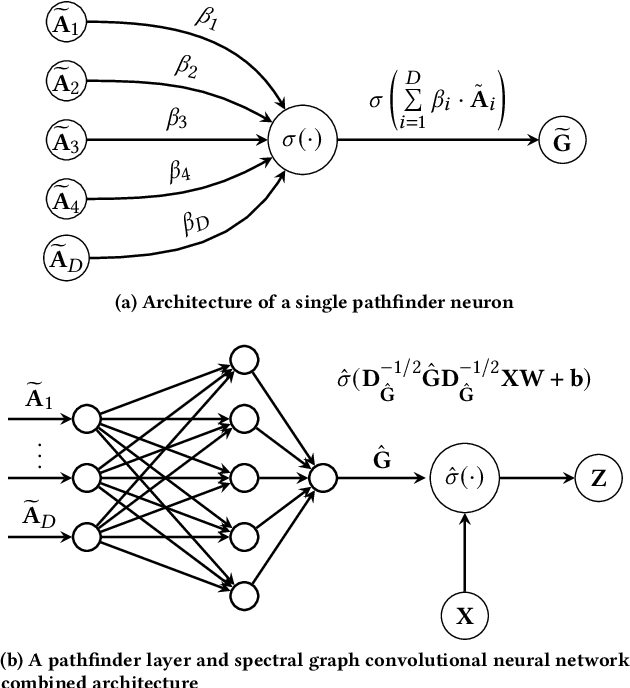
In this work we propose Pathfinder Discovery Networks (PDNs), a method for jointly learning a message passing graph over a multiplex network with a downstream semi-supervised model. PDNs inductively learn an aggregated weight for each edge, optimized to produce the best outcome for the downstream learning task. PDNs are a generalization of attention mechanisms on graphs which allow flexible construction of similarity functions between nodes, edge convolutions, and cheap multiscale mixing layers. We show that PDNs overcome weaknesses of existing methods for graph attention (e.g. Graph Attention Networks), such as the diminishing weight problem. Our experimental results demonstrate competitive predictive performance on academic node classification tasks. Additional results from a challenging suite of node classification experiments show how PDNs can learn a wider class of functions than existing baselines. We analyze the relative computational complexity of PDNs, and show that PDN runtime is not considerably higher than static-graph models. Finally, we discuss how PDNs can be used to construct an easily interpretable attention mechanism that allows users to understand information propagation in the graph.
Examining COVID-19 Forecasting using Spatio-Temporal Graph Neural Networks
Jul 06, 2020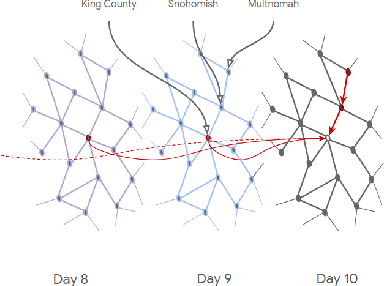
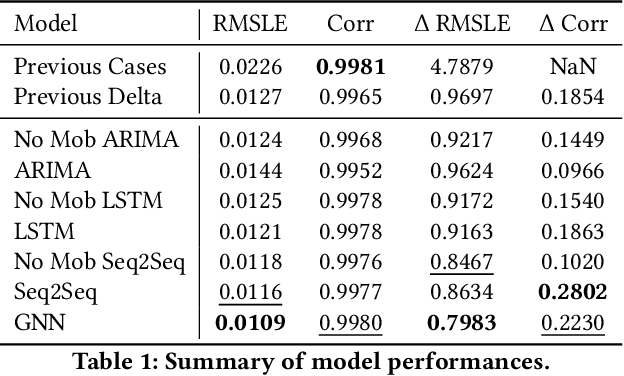
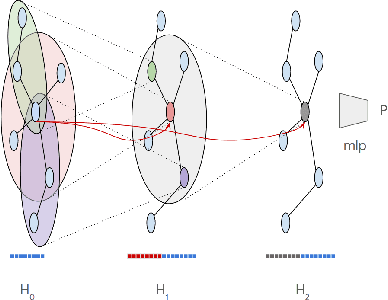
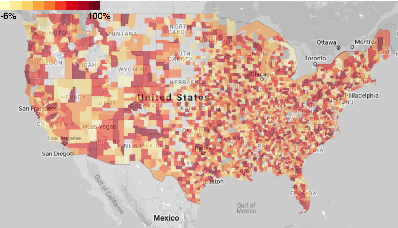
In this work, we examine a novel forecasting approach for COVID-19 case prediction that uses Graph Neural Networks and mobility data. In contrast to existing time series forecasting models, the proposed approach learns from a single large-scale spatio-temporal graph, where nodes represent the region-level human mobility, spatial edges represent the human mobility based inter-region connectivity, and temporal edges represent node features through time. We evaluate this approach on the US county level COVID-19 dataset, and demonstrate that the rich spatial and temporal information leveraged by the graph neural network allows the model to learn complex dynamics. We show a 6% reduction of RMSLE and an absolute Pearson Correlation improvement from 0.9978 to 0.998 compared to the best performing baseline models. This novel source of information combined with graph based deep learning approaches can be a powerful tool to understand the spread and evolution of COVID-19. We encourage others to further develop a novel modeling paradigm for infectious disease based on GNNs and high resolution mobility data.
Scaling Graph Neural Networks with Approximate PageRank
Jul 03, 2020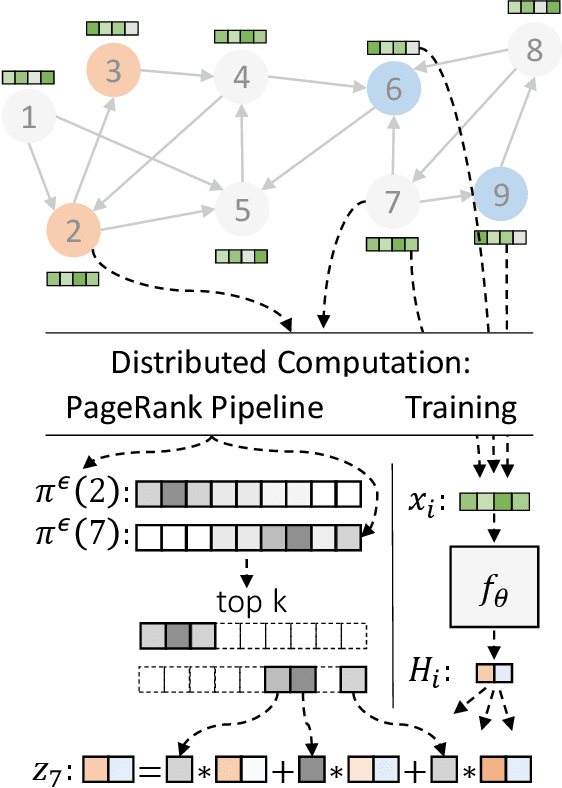



Graph neural networks (GNNs) have emerged as a powerful approach for solving many network mining tasks. However, learning on large graphs remains a challenge - many recently proposed scalable GNN approaches rely on an expensive message-passing procedure to propagate information through the graph. We present the PPRGo model which utilizes an efficient approximation of information diffusion in GNNs resulting in significant speed gains while maintaining state-of-the-art prediction performance. In addition to being faster, PPRGo is inherently scalable, and can be trivially parallelized for large datasets like those found in industry settings. We demonstrate that PPRGo outperforms baselines in both distributed and single-machine training environments on a number of commonly used academic graphs. To better analyze the scalability of large-scale graph learning methods, we introduce a novel benchmark graph with 12.4 million nodes, 173 million edges, and 2.8 million node features. We show that training PPRGo from scratch and predicting labels for all nodes in this graph takes under 2 minutes on a single machine, far outpacing other baselines on the same graph. We discuss the practical application of PPRGo to solve large-scale node classification problems at Google.
Investigating Under and Overfitting in Wasserstein Generative Adversarial Networks
Oct 30, 2019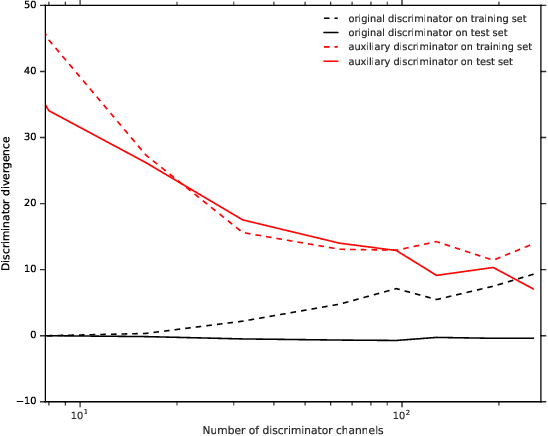

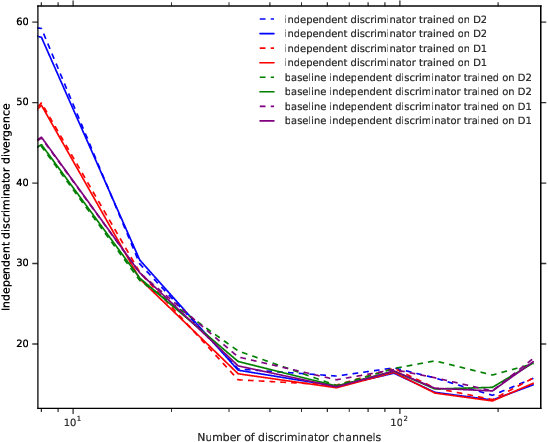
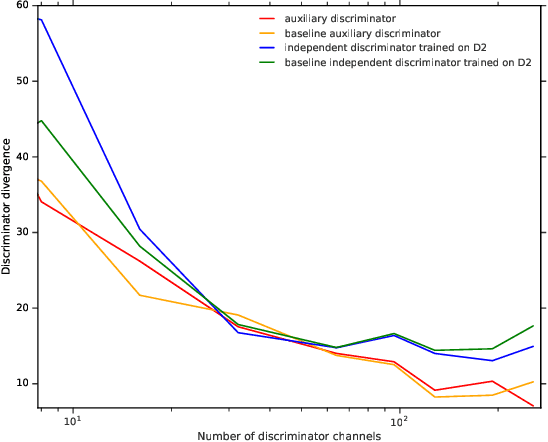
We investigate under and overfitting in Generative Adversarial Networks (GANs), using discriminators unseen by the generator to measure generalization. We find that the model capacity of the discriminator has a significant effect on the generator's model quality, and that the generator's poor performance coincides with the discriminator underfitting. Contrary to our expectations, we find that generators with large model capacities relative to the discriminator do not show evidence of overfitting on CIFAR10, CIFAR100, and CelebA.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019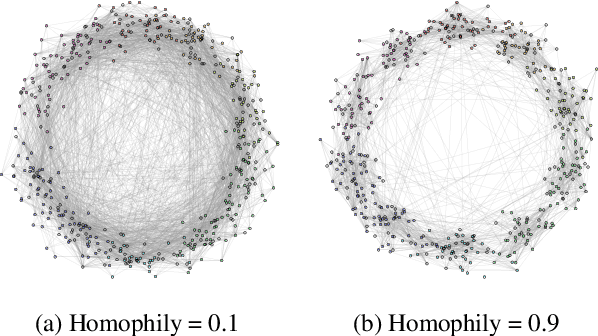
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Nostalgin: Extracting 3D City Models from Historical Image Data
May 06, 2019

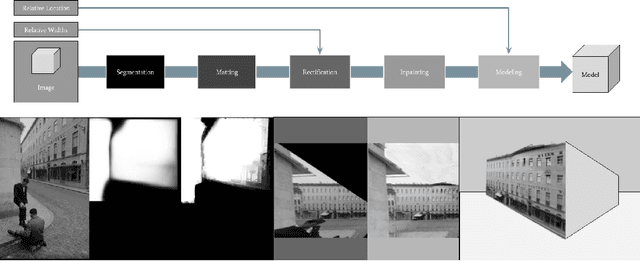
What did it feel like to walk through a city from the past? In this work, we describe Nostalgin (Nostalgia Engine), a method that can faithfully reconstruct cities from historical images. Unlike existing work in city reconstruction, we focus on the task of reconstructing 3D cities from historical images. Working with historical image data is substantially more difficult, as there are significantly fewer buildings available and the details of the camera parameters which captured the images are unknown. Nostalgin can generate a city model even if there is only a single image per facade, regardless of viewpoint or occlusions. To achieve this, our novel architecture combines image segmentation, rectification, and inpainting. We motivate our design decisions with experimental analysis of individual components of our pipeline, and show that we can improve on baselines in both speed and visual realism. We demonstrate the efficacy of our pipeline by recreating two 1940s Manhattan city blocks. We aim to deploy Nostalgin as an open source platform where users can generate immersive historical experiences from their own photos.
N-GCN: Multi-scale Graph Convolution for Semi-supervised Node Classification
Feb 24, 2018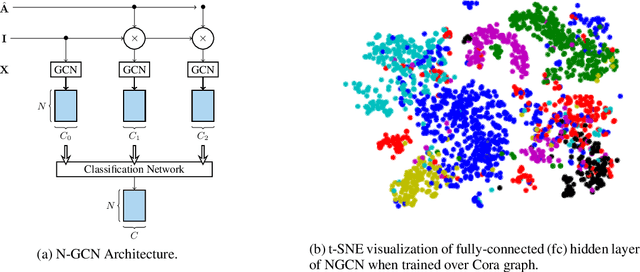

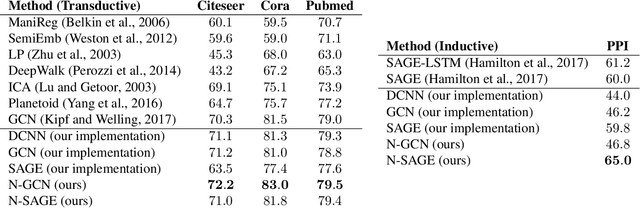
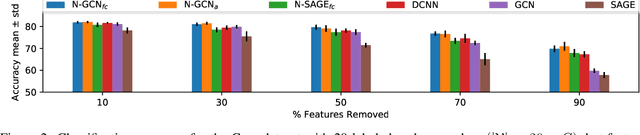
Graph Convolutional Networks (GCNs) have shown significant improvements in semi-supervised learning on graph-structured data. Concurrently, unsupervised learning of graph embeddings has benefited from the information contained in random walks. In this paper, we propose a model: Network of GCNs (N-GCN), which marries these two lines of work. At its core, N-GCN trains multiple instances of GCNs over node pairs discovered at different distances in random walks, and learns a combination of the instance outputs which optimizes the classification objective. Our experiments show that our proposed N-GCN model improves state-of-the-art baselines on all of the challenging node classification tasks we consider: Cora, Citeseer, Pubmed, and PPI. In addition, our proposed method has other desirable properties, including generalization to recently proposed semi-supervised learning methods such as GraphSAGE, allowing us to propose N-SAGE, and resilience to adversarial input perturbations.