 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Under and Overfitting in Wasserstein Generative Adversarial Networks
Oct 30, 2019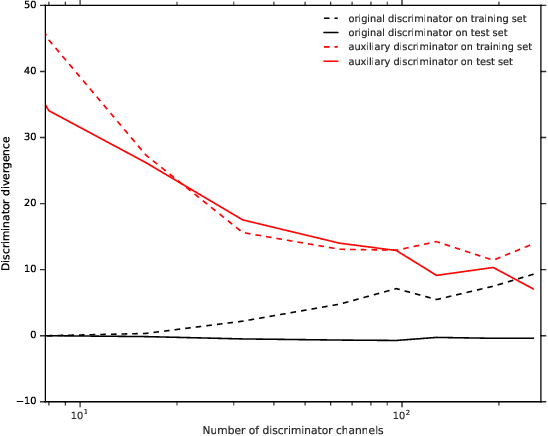

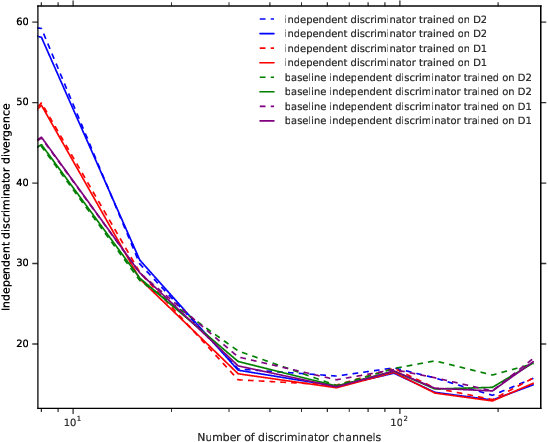
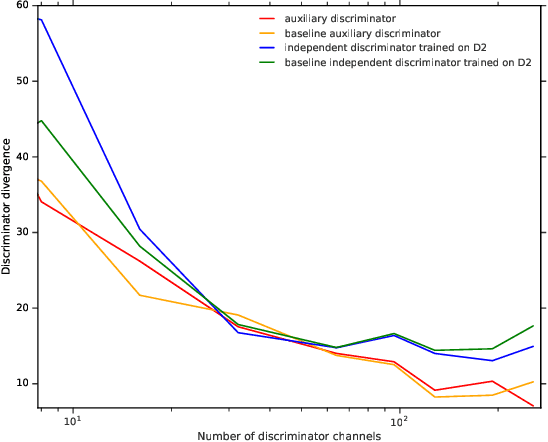
We investigate under and overfitting in Generative Adversarial Networks (GANs), using discriminators unseen by the generator to measure generalization. We find that the model capacity of the discriminator has a significant effect on the generator's model quality, and that the generator's poor performance coincides with the discriminator underfitting. Contrary to our expectations, we find that generators with large model capacities relative to the discriminator do not show evidence of overfitting on CIFAR10, CIFAR100, and CelebA.
AdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019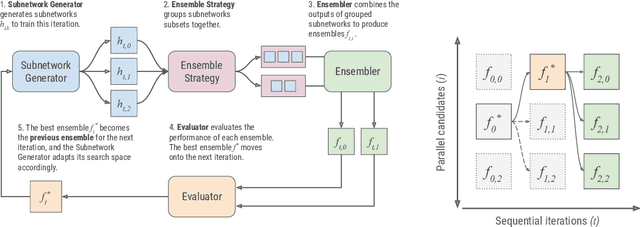
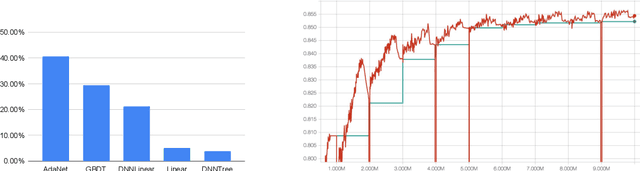
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
Improving Neural Architecture Search Image Classifiers via Ensemble Learning
Mar 14, 2019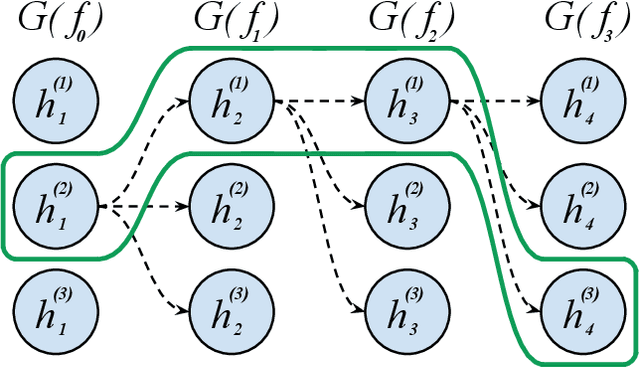
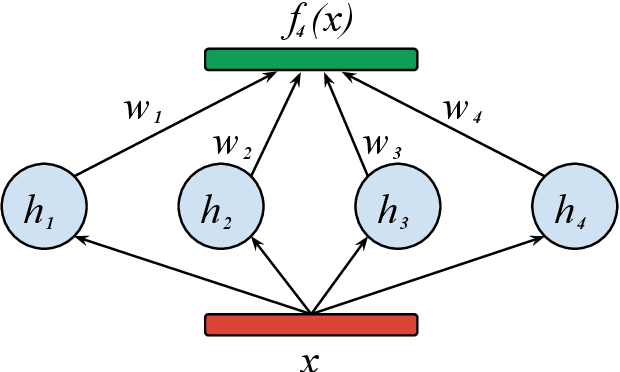
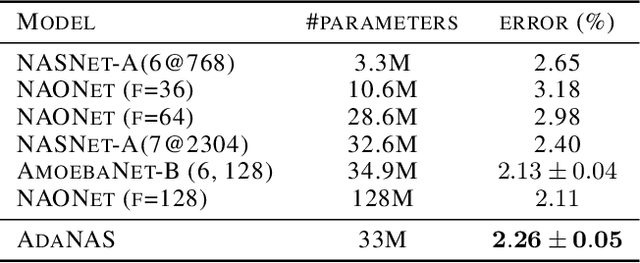
Finding the best neural network architecture requires significant time, resources, and human expertise. These challenges are partially addressed by neural architecture search (NAS) which is able to find the best convolutional layer or cell that is then used as a building block for the network. However, once a good building block is found, manual design is still required to assemble the final architecture as a combination of multiple blocks under a predefined parameter budget constraint. A common solution is to stack these blocks into a single tower and adjust the width and depth to fill the parameter budget. However, these single tower architectures may not be optimal. Instead, in this paper we present the AdaNAS algorithm, that uses ensemble techniques to compose a neural network as an ensemble of smaller networks automatically. Additionally, we introduce a novel technique based on knowledge distillation to iteratively train the smaller networks using the previous ensemble as a teacher. Our experiments demonstrate that ensembles of networks improve accuracy upon a single neural network while keeping the same number of parameters. Our models achieve comparable results with the state-of-the-art on CIFAR-10 and sets a new state-of-the-art on CIFAR-100.