 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by solving differential equations
May 19, 2025


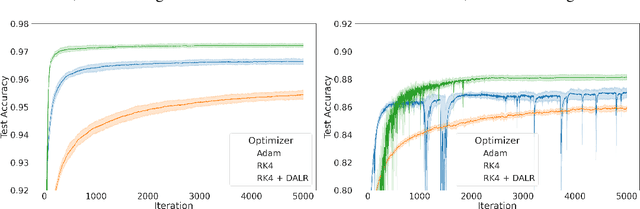
Modern deep learning algorithms use variations of gradient descent as their main learning methods. Gradient descent can be understood as the simplest Ordinary Differential Equation (ODE) solver; namely, the Euler method applied to the gradient flow differential equation. Since Euler, many ODE solvers have been devised that follow the gradient flow equation more precisely and more stably. Runge-Kutta (RK) methods provide a family of very powerful explicit and implicit high-order ODE solvers. However, these higher-order solvers have not found wide application in deep learning so far. In this work, we evaluate the performance of higher-order RK solvers when applied in deep learning, study their limitations, and propose ways to overcome these drawbacks. In particular, we explore how to improve their performance by naturally incorporating key ingredients of modern neural network optimizers such as preconditioning, adaptive learning rates, and momentum.
Training in reverse: How iteration order influences convergence and stability in deep learning
Feb 03, 2025
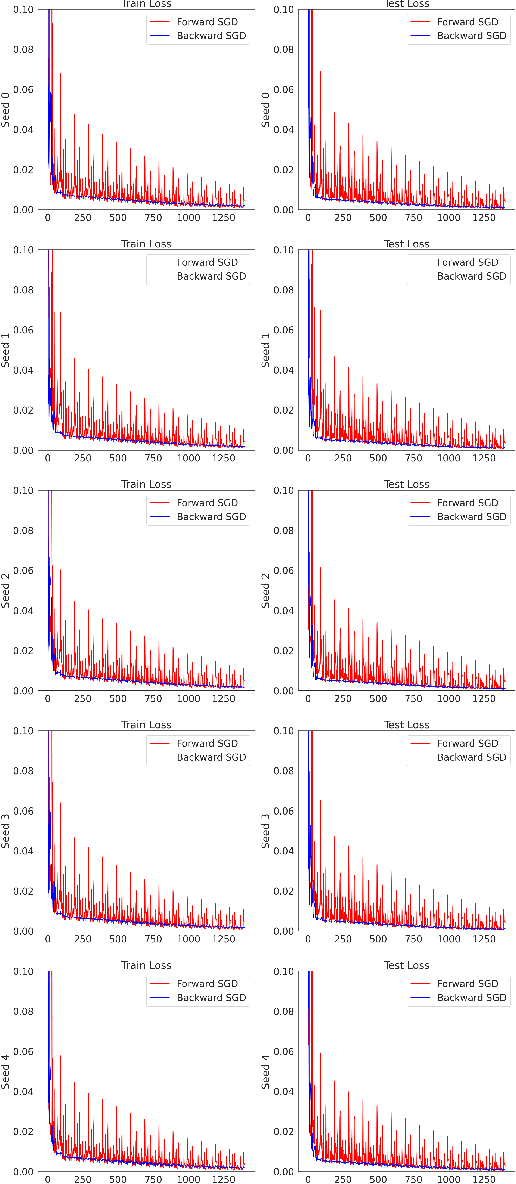


Despite exceptional achievements, training neural networks remains computationally expensive and is often plagued by instabilities that can degrade convergence. While learning rate schedules can help mitigate these issues, finding optimal schedules is time-consuming and resource-intensive. This work explores theoretical issues concerning training stability in the constant-learning-rate (i.e., without schedule) and small-batch-size regime. Surprisingly, we show that the order of gradient updates affects stability and convergence in gradient-based optimizers. We illustrate this new line of thinking using backward-SGD, which processes batch gradient updates like SGD but in reverse order. Our theoretical analysis shows that in contractive regions (e.g., around minima) backward-SGD converges to a point while the standard forward-SGD generally only converges to a distribution. This leads to improved stability and convergence which we demonstrate experimentally. While full backward-SGD is computationally intensive in practice, it highlights opportunities to exploit reverse training dynamics (or more generally alternate iteration orders) to improve training. To our knowledge, this represents a new and unexplored avenue in deep learning optimization.
The Impact of Geometric Complexity on Neural Collapse in Transfer Learning
May 28, 2024



Many of the recent remarkable advances in computer vision and language models can be attributed to the success of transfer learning via the pre-training of large foundation models. However, a theoretical framework which explains this empirical success is incomplete and remains an active area of research. Flatness of the loss surface and neural collapse have recently emerged as useful pre-training metrics which shed light on the implicit biases underlying pre-training. In this paper, we explore the geometric complexity of a model's learned representations as a fundamental mechanism that relates these two concepts. We show through experiments and theory that mechanisms which affect the geometric complexity of the pre-trained network also influence the neural collapse. Furthermore, we show how this effect of the geometric complexity generalizes to the neural collapse of new classes as well, thus encouraging better performance on downstream tasks, particularly in the few-shot setting.
A Margin-based Multiclass Generalization Bound via Geometric Complexity
May 28, 2024

There has been considerable effort to better understand the generalization capabilities of deep neural networks both as a means to unlock a theoretical understanding of their success as well as providing directions for further improvements. In this paper, we investigate margin-based multiclass generalization bounds for neural networks which rely on a recent complexity measure, the geometric complexity, developed for neural networks. We derive a new upper bound on the generalization error which scales with the margin-normalized geometric complexity of the network and which holds for a broad family of data distributions and model classes. Our generalization bound is empirically investigated for a ResNet-18 model trained with SGD on the CIFAR-10 and CIFAR-100 datasets with both original and random labels.
* Accepted as an ICML 2023 workshop paper (Topology, Algebra and Geometry in Machine Learning)
Towards Task and Architecture-Independent Generalization Gap Predictors
Jun 04, 2019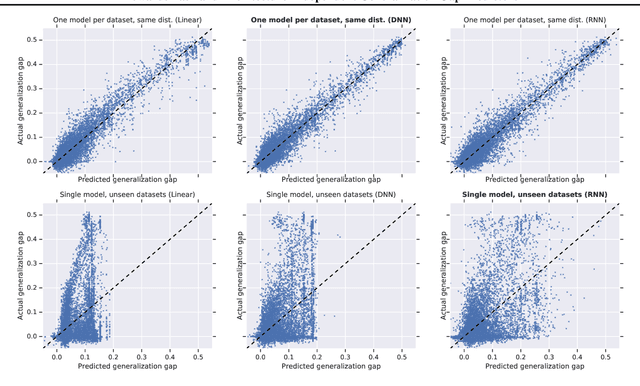

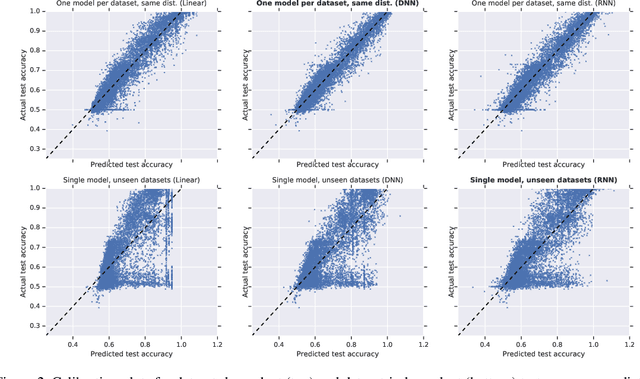

Can we use deep learning to predict when deep learning works? Our results suggest the affirmative. We created a dataset by training 13,500 neural networks with different architectures, on different variations of spiral datasets, and using different optimization parameters. We used this dataset to train task-independent and architecture-independent generalization gap predictors for those neural networks. We extend Jiang et al. (2018) to also use DNNs and RNNs and show that they outperform the linear model, obtaining $R^2=0.965$. We also show results for architecture-independent, task-independent, and out-of-distribution generalization gap prediction tasks. Both DNNs and RNNs consistently and significantly outperform linear models, with RNNs obtaining $R^2=0.584$.
AdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019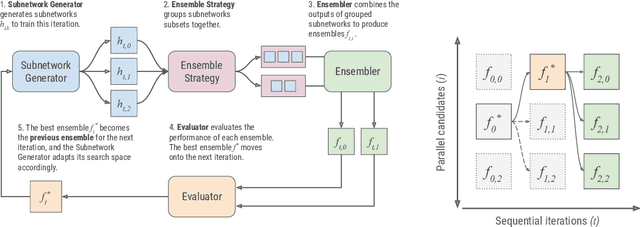
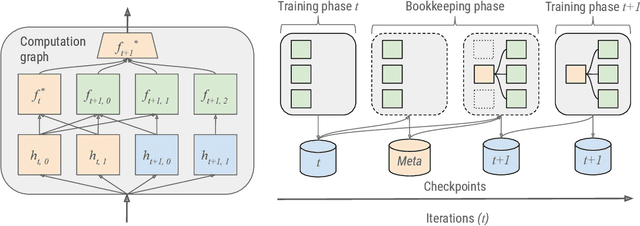
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
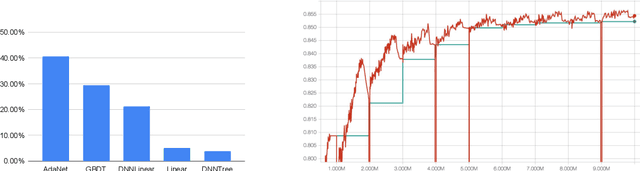
Improving Neural Architecture Search Image Classifiers via Ensemble Learning
Mar 14, 2019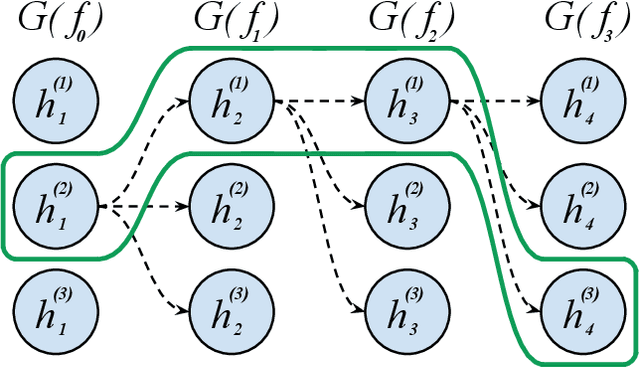
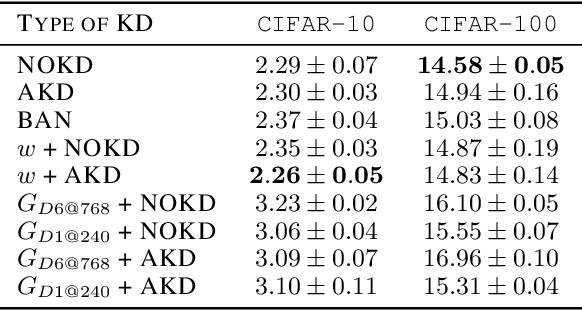
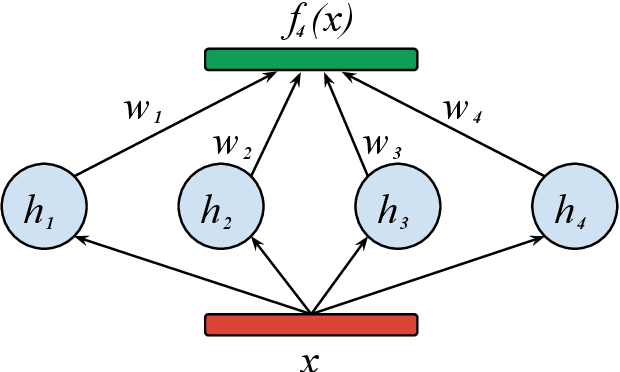
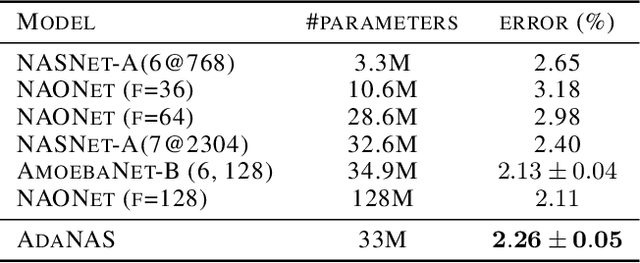
Finding the best neural network architecture requires significant time, resources, and human expertise. These challenges are partially addressed by neural architecture search (NAS) which is able to find the best convolutional layer or cell that is then used as a building block for the network. However, once a good building block is found, manual design is still required to assemble the final architecture as a combination of multiple blocks under a predefined parameter budget constraint. A common solution is to stack these blocks into a single tower and adjust the width and depth to fill the parameter budget. However, these single tower architectures may not be optimal. Instead, in this paper we present the AdaNAS algorithm, that uses ensemble techniques to compose a neural network as an ensemble of smaller networks automatically. Additionally, we introduce a novel technique based on knowledge distillation to iteratively train the smaller networks using the previous ensemble as a teacher. Our experiments demonstrate that ensembles of networks improve accuracy upon a single neural network while keeping the same number of parameters. Our models achieve comparable results with the state-of-the-art on CIFAR-10 and sets a new state-of-the-art on CIFAR-100.